
摘要
近些年来,上下文学习((In-context Learning, ICL)日益受到越来越多的关注,并成为大型语言模式(LLM)评估的新范例。与传统的微调方法不同,ICL采用预先训练的模式,适应了无形的任务,而没有任何参数更新。然而,由于所涉及的检索和推断方法多种多样,不同模型、数据集和任务都有不同的预处理要求,ICL的实施十分复杂。迫切需要为ICL建立一个统一灵活的框架,以方便上述组成部分的执行。为了便利ICL研究,我们引入OpenICL,这是ICL和LLLM评估的开放源工具包。OpenIC是一个方便研究的、高度灵活的结构,用户可以很容易地将不同的组成部分结合起来,以适应其需要。它还提供了各种最先进的检索和推理方法,简化了ICLL适应尖端研究的进程。OpenICLLL的实效已经通过一系列NLP任务得到验证,包括分类、问答、机器翻译和语义分析。我们发现OpenICL是一种高效而稳健的LLM评估工具,OpenICL发布在https://github.com/Shark-NLP/OpenICL。
1 介绍
大型语言模型(LLMs)的崛起展示了令人印象深刻的上下文学习(ICL)能力。不同于需要参数更新的微调,ICL可以在模型参数冻结的情况下执行推理。ICL规避了微调需要大量资源的特性,但在特定任务中仍可以产生与微调模型相当的结果。然而,我们观察到缺乏一个统一的ICL框架。现有项目的实现通常高度定制以适应自己的需求,因此使得进一步的开发和与先前方法的比较成为一个挑战。
基本的ICL流程包含两个步骤:检索和推理。在检索阶段中,给定一个测试输入X,从训练集中检索出多个上下文演示示例。在推理阶段中,这些演示示例被添加到X之前,并馈入LLM以生成预测。研究人员已经探索了各种方法来进行检索、TopK和VoteK和推理(例如基于困惑度的)、基于通道的和思维链的操作。然而,这些方法通常在不同的框架下实现,或者使用不同的LLMs和任务进行评估。这些不一致性使得各种方法的系统评估和比较变得困难,从而阻碍了更好的ICL方法的发展。为了解决这个问题,我们提出了OpenICL,一个易于使用的ICL开源工具包。OpenICL内置了许多最先进的检索和推理方法,以便进行系统比较和快速研究原型。OpenICL还提供了统一而灵活的界面,用于开发和评估新的ICL方法。用户可以轻松地将不同的检索和推理方法以及不同的提示指令合并到他们的流程中。
为了验证OpenICL的实现和设计,我们使用OpenICL在几个NLP任务上评估LLMs,包括分类、问答、翻译和语义解析。我们的贡献总结如下:
- 我们提出了OpenICL,一个易于使用且可扩展的ICL框架,用于零/少样本语言模型评估。
- OpenICL提供了广泛的ICL方法、LLMs和任务,仅需要几行代码即可使用,并为未来的更多扩展铺平了道路。
- 我们提供完整的教程,引导用户使用该框架,从而促进ICL的研究和开发。
2 相关工作
上下文学习 除了经典的“预训练和微调”范式外,Brown等人提出了上下文学习(In-context learning,ICL),一种利用预训练语言模型在没有梯度训练的情况下执行新任务的新范式。它在测试输入之前附加少量训练示例作为提示,并已被证明能够提高LLMs在少样本场景中的性能,并推广到各种下游任务,如信息检索、事实核查、常识推理、算术推理、机器翻译和数据生成等。
除了这些早期的成功之外,研究人员已经开发出更为复杂的ICL方法,需要一些中间的推理步骤。其中,思维链(Chain-of-thoughts,CoT)是第一个显著超过以前的许多推理任务的最先进方法。在此之后,提出了CoT的不同变体来加强其性能,如自问、iCAP、从少到多提示和选择推断。
尽管ICL表现出令人惊讶的性能,但也因对上下文示例的选择和排序非常敏感而受到批评。为了解决这个问题,提出了不同的标准和上下文构建方法。Gao和Liu等人选择在嵌入空间中与测试输入更接近的示例;一系列工作选择训练集中最具代表性的示例,以鼓励多样性的上下文示例;Wu等人观察到最小描述长度(Minimum Description Length,MDL)原则可以成为上下文示例选择的有效标准。
提示学习(Prompt Learning是没有上下文示例的 ICL 的一种特殊情况。Prompt 学习包括手动模板工程、自动模板学习以及答案工程等多种主题。我们建议读者使用专为 Prompt 学习设计的工具包 OpenPrompt。与此相比,OpenICL 更专注于整合各种范例检索方法和推理策略,以进行上下文学习。需要注意的是,通过将上下文示例的数量设置为零并为不同的任务指定手动或预先搜索的 Prompt 模板,OpenICL 也可以无缝支持 Prompt 学习。
3 OpenICL
本节中,我们首先解释OpenICL的设计原则。然后,我们将简要描述OpenICL的两个主要组件,即Retriever和Inferencer。
3.1 设计原则
OpenICL的设计原则是促进上下文学习研究,实现高效且鲁棒的大语言模型评估。具体而言,我们考虑以下原则:
[P1:模块化] 由于ICL是一个快速发展的研究领域,OpenICL的设计应该是解耦的,以便不同的组件可以轻松修改以支持最新的方法和/或组合以适应各种任务和应用需求。
[P2:效率] 如今,大语言模型可以具有数百亿的参数。为了支持这种大规模的推理,OpenICL应该被优化以实现高效的并行推理。
[P3:普适性] ICL已广泛用于NLP领域的所有领域,因此OpenICL需要一个灵活的接口,使其能够与各种LLMs、任务、检索方法和推理方法一起工作。
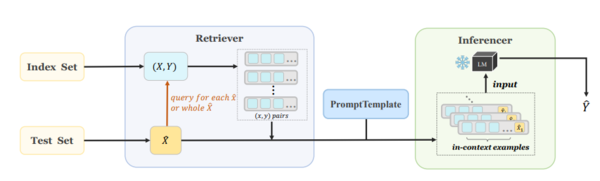

图1:OpenICL的架构概览。OpenICL首先通过用户指定的检索方法(例如TopK或VoteK)从索引集中获取适当的上下文示例,针对每个测试输入或整个测试集。然后,根据提供的提示模板,将上下文示例和测试输入连接成单个序列。最后,所有提示都被馈送到语言模型中,通过定义的推理策略(例如Chain-of-thought)推断输出。
3.2 架构概览
图1概述了OpenICL的架构。对于来自测试集Xˆ的每个输入xˆ,Retriever从索引集(X,Y)中检索几个(x,y)对(表示为虚线框中的一行),作为xˆ的上下文示例。然后,这些示例以及xˆ根据用户定义的提示模板进行格式化,并连接成一个文本序列。之后,Inferencer会处理这些序列并将它们提供给LLM,以获得模型的预测Yˆ。
3.3 模块化
为了满足原则P1,OpenICL采用了松散耦合的设计,将数据预处理、检索和推理过程分开,并提供非常灵活的接口,以便轻松定制以适应特定需求。下面详细介绍了两个主要组件:
Retriever Retriever 负责从预先存在的训练数据中检索上下文示例。该模块支持语料库级别的(即仅为整个测试集检索一组示例)和实例级别的(即为每个测试输入分别检索示例)检索方法。OpenICL主要支持无学习的检索方法,如下:
• 随机方法(Random):早期的 ICL 研究常常使用随机方法来选择例子构建上下文。虽然随机方法的性能变化范围较大,但在只有少量演示可用时仍然是常用的选择。
• 启发式方法(Heuristic method):为了克服随机方法的缺点,提出了各种基于语义相似性的检索方法,例如 BM25、TopK和 VoteK,已经显示出很大的潜力。
• 基于模型的方法(Model-based method):近年来,研究人员开始探索使用模型对输出的置信度来选择和排序示例,例如熵(Entropy)和 MDL。
OpenICL已经实现了上述现有的方法,以促进未来研究和系统性比较。此外,Retriever模块的灵活性允许从业者选择检索方法并进行进一步修改,以最适合其任务和数据。Retriever的接口还允许用户打包这些上下文示例并在其他地方使用。
Inferencer Inferencer会调用预训练语言模型,基于上下文示例和测试输入的串联生成预测。Inferencer支持各种推理方法:
• 直接方法:Brown等人使用词汇表中的标记来表示候选答案,并选择概率最高的作为最终预测结果。
• 困惑度方法:Brown等人计算输入和候选答案的序列连接的句子困惑度,并选择困惑度最低的作为最终预测结果。
• Channel方法:Min等人提出利用通道模型来反向计算条件概率,即估计标签给定的情况下输入查询的可能性。 Inferencer的灵活性还允许用户递归地调用它,以支持多阶段ICL方法,例如chain-of-thought和selection-inference。此外,Inferencer可以通过加入得分器来评估其预测结果。
3.4 效率
为了满足P2原则,我们为OpenICL配备了各种并行技术,以实现大规模模型的高效推理。
数据并行 数据并行是并行计算中常用的技术,用于提高大规模计算任务的效率。OpenICL实现了数据并行以提高检索和推理步骤的性能。在检索和推理过程中,数据被分成更小的批次进行处理。此外,对于可以适应GPU VRAM的模型,OpenICL通过将数据分片到多个GPU上,并在每个GPU上使用完整模型的副本进行并行推理,实现了数据并行。这显著提高了处理大型数据集时的推理速度。
模型并行 在LLM时代,模型通常具有超过现代GPU容量的数十亿或数千亿个参数。为了解决这个问题,我们采用了模型并行:一种并行计算技术,将大型深度学习模型分成较小的子模型,每个子模型可以在单独的GPU上运行。OpenICL支持模型并行,用户可以轻松地将其模型并行化,只需进行最少的代码修改。目前,我们支持Megatron和Zero。
3.5 通用性
为了满足P3原则,OpenICL的设计旨在通过支持多种模型、任务和方法来最大化用户的生产力:
[模型] OpenICL支持仅解码器的语言模型(如GPT系列)和编码器-解码器型语言模型(如T5)。我们还提供两种访问模型的替代方案:用户可以直接加载模型检查点进行评估,也可以通过API访问模型(例如OpenAI的GPT-3系列模型)。
[任务] 在OpenICL的帮助下,用户可以轻松进行分类和生成任务的实验。OpenICL集成了HuggingFace的数据集,使用户可以轻松访问和下载数千个NLP任务。
[方法] 如前所述,OpenICL提供广泛的ICL方法支持,涵盖检索和推断。此外,OpenICL提供了灵活性,可以以逐步方式返回Retriever和Inferencer的结果,使得将这些中间结果集成到其他项目中变得容易。
在本节中,我们通过演示几个典型的ICL用例,向读者展示了OpenICL的使用。
示例1。图3展示了如何使用OpenICL解决生成问题。我们考虑流行的机器翻译数据集WMT16(Bojar等人,2016)。与示例1类似,我们可以轻松地加载数据集、定义提示模板并通过向函数提供新参数来启动检索器。与示例1不同的主要API差异是:(i)我们为翻译任务添加了一些预处理(line 5); (ii) PPLInferencer被专门用于生成的inferencer(line 16)取代; (iii)我们使用BLEU来评估模型性能。 展示了如何使用OpenICL开发典型的ICL语言分类管道,使用几行代码对流行的情感分类数据集SST-2 进行评估。如图2所示,管道始于DatasetReader,它根据其在HuggingFace Dataset Hub3上的名称或本地文件路径加载数据集。用户需要指定输入(“text”)和输出(“label”)存储的列的名称。其次,使用定义了每个类标签提示的字典实例化自定义的PromptTemplate。占位符</E>和</Q>将分别被上下文示例和测试输入替换。然后,我们启动基于TopK(Liu等,2022)的Retriever,并将上下文示例的数量设置为8(“ice_num = 8”)。我们选择基于困惑度的方法来启动Inferencer,并使用GPT2-XL作为LLM。完成这些设置后,我们可以通过调用Inferencer(第17行)并计算模型预测的准确性(第18行)来运行推理。

图2:展示了示例1的情况,该示例使用PPL推理策略评估了GPT2-XL(1.5B)在SST-2数据集上的ICL性能。
示例2。图3展示了如何使用OpenICL解决生成问题。我们考虑流行的机器翻译数据集WMT16。与示例1类似,我们可以轻松地加载数据集、定义提示模板并通过向函数提供新参数来启动检索器。与示例1不同的主要API差异是:(i)我们为翻译任务添加了一些预处理(line 5); (ii) PPLInferencer被专门用于生成的inferencer(line 16)取代; (iii)我们使用BLEU来评估模型性能。
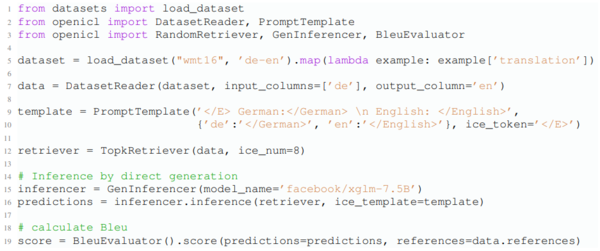
图3:展示了示例2的情况,该示例使用直接推理策略评估了XGLM(7.5B)在WMT16(de-en)数据集上的ICL性能。
示例3。OpenICL还支持更高级的ICL方法,如图4所示。用户只需修改两行代码即可轻松切换到思维链推理方法:第14行定义了思维链模板,第15行使用OpenAI的API启动了与GPT3配合的推理器。类似的多步ICL方法,如自一致性和选择推理,也可以通过继承OpenICL中设计的超类Inferencer来轻松实现。
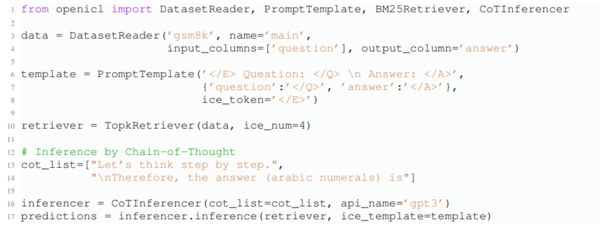
图4:展示了示例3的情况,该示例使用思维链推理策略评估了GPT-3的text-davinci-003版本(175B)在GSM8K数据集上的ICL性能。
5 评估
为了展示OpenICL的灵活性,我们在多个不同的数据集、LLMs和ICL方法上进行了实验。我们考虑用于常识推理的PiQA,用于情感分析的SST-2,用于算术推理的GSM8K,用于机器翻译的WMT16 de-en和用于摘要的Gigaword。我们还测试了各种LLMs,包括GPT-Neo(2.7B),GPT-3的text-davinci-003版本(175B)和XGLM(7.5B)。我们使用OpenAI的官方API4来访问GPT-3。详细的设置和结果如图5所示,正如我们所看到的那样,OpenICL的组件可以轻松地链接在一起,以支持不同的评估需求并复制最先进方法的结果。
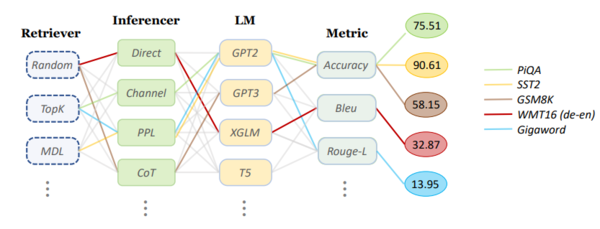
图5:评估结果。我们使用OpenICL在五个代表性任务上进行实验,并使用不同的检索器、推理器、语言模型和其他组件。在模型使用方面,我们采用GPT-Neo(2.7B)用于SST2、PiQA和Gigaword,XGLM(7.5B)用于WMT16(de-en),以及GPT-3的text-davinci-003版本(175B)用于GSM8K。
6 结论
我们提出了OpenICL,这是一个开源的工具包,用于上下文学习In-context learning。OpenICL为上下文学习实践和研究提供了方便和灵活的接口。我们的模块化设计使其能够轻松支持各种LLM、任务和ICL方法。我们实现了模型并行和数据并行,以使大型模型的推理更加高效。OpenICL具有高度可扩展性,我们将继续更新它以跟上最新的研究。尽管ICL的前景非常有希望,但它仍处于早期阶段,还存在许多挑战。我们相信OpenICL将成为研究人员和从业者的宝贵资源,以促进他们的研究和开发。
论文链接:https://arxiv.org/abs/2303.02913
—煤油灯科技victorlamp.com编译整理—
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。