
顺丰作为国内领先的快递物流综合服务商,一直致力于为用户提供更优质、更高效便捷的快递物流服务。顺丰科技作为顺丰集团旗下的科技公司,以科技深耕于物流与供应链行业,通过在大数据、人工智能等前沿科技上不断努力探索、发展和落地,实现整体产业链的降本增效,进而提升客户服务体验。随着语音识别的不断发展,在快递物流领域引入语音服务成为了必然的发展趋势。
自2021年初,我们从零开始逐渐完善形成了全面的信号处理、语音合成、语音识别和语言理解的能力体系,同时根据公司业务场景的需求,打造了智能质检、智能外呼等实际产品并实现了落地。2022年我们基于WeNet搭建了自研语音识别框架并构建了自研识别引擎,下半年实现了kaldi方案向WeNet方案落地的顺利过渡, 基于业务场景测试集上已获得相当甚至优于第三方方案的识别效果。
本文将对我们基于WeNet进行的研究工作做个简要的介绍。
背景工作
众所周知,语音识别根据其应用场景的不同,有非流式和流式两种模型推理架构。非流式架构主要应用在语音质检、会议记录转写等不必须实时反馈结果的应用场景,重点关注的是识别精度和RTF;流式架构则主要用在语音外呼、对话机器人等需要及时反馈结果的应用场景,侧重于识别精度和延迟的权衡。
顺丰根据自身业务特点,在非流式和流式解码均存在大量需求。我们最初的方案是采用在工业界已经比较成熟的kaldi的hybrid落地方案,非流式和流式场景均采用此框架。通过对声学模型和语言模型的一系列finetune,我们在实验室端基于实际业务数据达到了超越第三方方案的性能效果并实现了在智能质检和智能外呼的一期落地。但实际落地后我们也看到了这一方案在处理更复杂场景上的不足,对于噪声等方面的鲁棒性不够理想。因此,为了突破算法的局限性,我们对当前比较热门的端到端方案进行了大量的调研工作,最后综合识别准确率、流式实现和落地可行性等多方面因素,决定采用WeNet框架替代原有kaidl框架作为新的识别方案落地。
研究工作
非流式识别
基线系统
我们首先将WeNet的非流式Conformer方案落地到了顺丰内部的智能语音质检场景。在可利用的业务数据上finetune,最终WeNet技术方案相比kaldi方案在售前业务测试集上CER相对下降35%,字准确率也达到92%以上,同时基于CPU硬件条件下RTF在单核上的效率相较于kaldi基本持平。在不影响质检效率的前提下,大幅提升了质检识别的准确度,以下为几个阶段性结果的对比。
| 售前50h | kaldi | wenet基线 | wenet finetune |
|---|---|---|---|
| CER | 14.0 | 10.4 | 9.1 |
我们知道,有监督训练通常需要大量的标注训练数据来进行支撑以获得较为满意的性能效果。顺丰在各类业务中有着深厚的普通话语料积累,这方面相对易于达成;但对于小众的方言,如粤语、闽语等,考虑到其标注难度,想要获得可观的数据量成本相对较大。因此考虑到后续相关场景的业务扩展,我们在进行基线系统优化的过程中对比了无监督wav2vec2.0框架及WeNet在不同数量级上微调的识别效果,以为后续数据稀缺场景的训练提供参考。
下表为无监督wav2vec2.0框架在50h售前业务数据上的性能表现。可以看到使用开源的英文预训练模型在部分业务数据上微调的性能已经可以比拟kaldi在全量数据下最优模型的结果。同时,基于业务数据重新训练中文预训练模型再微调可使字错误率进一步下降,相对幅度近20%。
| wav2vec+1400h业务数据微调 | 英文预训练 | 中文预训练 |
|---|---|---|
| CER | 14.05% | 11.53% |
与此同时,我们基于wenet预训练模型使用了不同量级的业务标注数据进行finetune,并在相同测试集进行测试,结果如下:
| CER | base | 10h | 50h | 200h | 2000h |
|---|---|---|---|---|---|
| wenet(wenetspeech) | 23.81% | 14.39% | 12.73% | 11.51% | 9.62% |
从上面的结果可以看出, 1) wenet在10h数据量上相比wenetspeech原预训练模型在对应的新场景下字错误率相对下降40%,和kaldi使用全量数据达到的性能效果相当。2) wenet在200h数据量级获得了和无监督wav2vec2.0使用1400h微调模型相似的性能。
系统设计
系统设计方面,我们根据自身的功能需求和场景的需要重新整合实现了WeNet语音识别服务的流程。实践中我们看到通过SpecAug和模型对局部和全局信息的捕捉,WeNet面对非复杂噪声环境情况下具有良好的抵抗噪声和尾点检测的能力,但WeNet非流式模式下直接处理数据也有以下几方面的问题。
- 对音频时长存在约200s的限制;
- full chunk模式因为可以看到全局信息模型分布的估计会更准确,但在处理长时音频时,也会引入更多干扰和冗余信息。如果不做其它的处理,一是会使得解码时间明显加长,二是对性能也会有负面的影响。以下是不改变语音解码量,单纯进行语音切分时相同非流式模型的性能对比。
| 售前50h | 无切分(<200s) | 切分(平均时长30s) | 切分(平均时长20s) |
|---|---|---|---|
| CER | 22.6% | 13.3% | 12.7% |
| Acc | 77.9% | 87.8% | 88.5% |
| RTF(CPU) | 0.268 | 0.135 | 0.133 |
可以看到,平均时长20~30s,语音识别模型的性能和效率都有明显的提升,说明距离当前时刻较远的音频信息不能为识别模型带来性能的提升,以句子为单位对音频数据进行划分是必要的处理步骤。
- 长语音角色切换的分界点容易出现识别漏字或错误。
因此在实际落地时我们对整体流程进行了调整和优化,增加了端点检测和话者分离的模块对输入音频进行前处理。以下非流式识别过程的整体示意。


以下为全流程下基于售前50h业务数据测试集上的测试结果。
| 售前50h | ASR | VAD + ASR | VAD + SD + ASR |
|---|---|---|---|
| CER | 22.6% | 11.4% | 10.8% |
| Acc | 77.9% | 90.0% | 91.5% |
可以看到,端点检测和话者分离对于提升整体解码性能起到很重要的作用。
解码加速
针对模型解码效率的提升,在不考虑硬件条件的情况下,我们首先考虑的是参数量对解码速度的影响。为此,我们对比统计了非流式不同参数量的时间消耗。
| 售前50h | 12层 | 6层 | 4层 |
|---|---|---|---|
| CER | 10.7% | 11.4% | 12.6% |
| RTF(GPU) | 0.0225 | 0.0191 | 0.018 |
在未进行知识蒸馏的情况下,参数量减少一倍,字错误率相对下降6%的情况下,RTF仅相对下降15%,由此引入的加速收效有限。为具体探究其原因,我们对比了各模块在解码时的耗时占比,结果如下
| forward | search | rescoring | |
|---|---|---|---|
| 非流式12层 | 1025k | 1477k | 436k |
| 流式12层 | 1076k | 1429k | 292k |
| 流式6层 | 625k | 1429k | 297k |
参数量减少有效的降低了forward的计算耗时,但整个解码中最耗时的部分是ctc search的部分,占总耗时的将近一半,实际最终能引入的加速效果就会变得相对有限。
在GPU本身解码速度比较快的情况下,这种加速能带来的效率提升就更为有限,需同时重视的是解码搜索的加速。
考虑到各功能模块的整体效率和成本等因素,我们当前落地的是CPU版本的语音识别服务。当然我们也看到GPU整体的运行效率是CPU的10倍,运行效率提升十分显著,经NVIDIA优化效率会进一步提升,所以未来我们的一个重要的优化方向就是实现GPU版本的迁移和优化。
流式识别
基线系统
流式识别服务主要应用在智能外呼、对话机器人等几个实时业务场景。为了比较快速的获得鲁棒性较好的端到端模型,我们采用U2++模型作为基本框架进行基线的训练,并以微调为主进行了多种改进尝试。
我们使用标注的业务数据进行基线的训练,但在训练数据不够充分的情况下,所得模型的精度有限。一个很明显的现象就是模型难以避免的会受到对话场景、信道特征等方面的影响,在场景内表现尚可,但在场景外性能则明显下降。因此我们引入了基于大数据量训练的U2++模型Wenetspeech作为初始的预训练模型,并以此为基础在业务场景上进行微调。这一方式可以较好的弥补业务场景数据对分布的有偏估计,提供更泛化的音频和文本对应的信息分布以供后续的迁移学习。通过微调,模型在各场景下的性能表现更加稳定。
同时,考虑到有监督的业务数据量相对有限,更易于获取的是没有标注信息的实际业务数据,我们利用已有的精度更高的非流式Conformer模型为大数据量无监督业务数据生成伪标签信息,同时通过诸如模型/语法得分过滤,长度匹配等一系列机制对生成的音频伪标签进行筛选,获得置信度较高的音频-文本数据对用于后续模型的优化训练。实验证明,伪标签数据在已有预训练模型微调后更泛化的分布上依然可以为模型提供有用的信息。
通过预训练模型微调、伪标签数据生成等优化操作,chunksize=16性能相比无预训练知识情况下字错误率相对下降12%。
| CER | 标注数据训练 | 预训练模型微调 | 伪标签(>10000h)预训练模型微调 |
|---|---|---|---|
| 售前50h测试集 | 12.3% | 11.2% | 10.8% |
系统设计
在实际落地时,基于流式场景我们在WeNet ASR前端保留了端点检测的功能。端点检测一方面配合协议判断语音的起始和结束完成外呼和对话的交互,一方面辅助ASR去除冗余解码和噪声干扰,提升识别效果和响应速度。两者通过数据缓存池配合完成流式语音数据的接入,在ASR端结合具体场景使用不同的热词集配合解码,对语音识别结果进行实时的返回。具体流程示意如下:
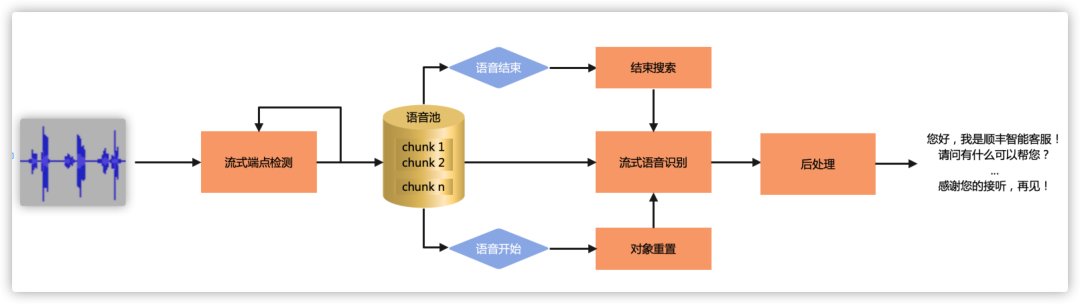
系统改进
通过线上业务开展反馈的实测情况,我们发现部分热词的引入会导致偶发的后续识别文本缺失的现象。
以下述热词列表为例,热词列表包含下述两个词及若干其他词,但不包含“顺丰客服”。
顺丰标快
顺丰小哥
当发音输入包含”顺丰客服”,且context_score设置相对比较大的值时,有可能会出现识别文本识别至“<context>顺丰”后漏字或者后续识别文本全部丢失的现象,即识别“卡死”的错觉。
对此,我们跟踪解码流程发现,某些case由于发音者在热词前段各字的得分比较高,配以权重奖励导致得分更高;新来的字在其ctc得分最高的几帧也未能超越热词奖励后的路径,导致正确路径被剪枝掉,造成后续部分字或者是整句识别结果的缺失。
这一问题的其中一个解决方式是适当调低context的奖励值,但是对于不同的输入语音,这个调低的幅度是变化的,不能保证调低到某个值就确定可以规避所有在搜索中出现这类现象。因此,为了解决这个问题,我们尝试对搜索过程中的热词权重进行动态scale。根据当前非blank的最后一个token的时间戳距离当前时刻的时长判断是否要对热词权重进行scale的方式削弱热词权重对整体搜索的影响。我们尝试了几种不同的scale方式,在权衡过对该问题的解决效果和对其他样本识别结果的影响程度后,最后选用了“常值+指数”的方式对搜索过程中的context score进行更新。通过这种方式的介入,上述热词引入偶发的识别文本缺失现象基本得到了解决。
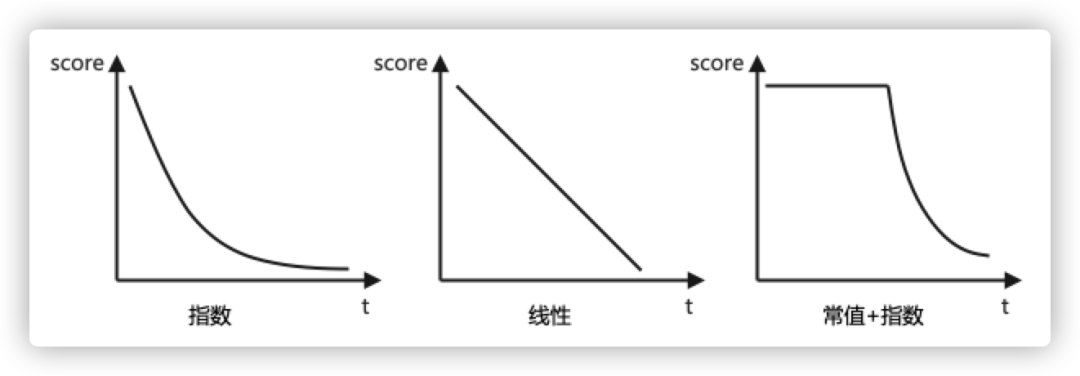
以下是未进行和引入了context scale修复在同一模型同一测试集下的性能对比。
| 售前50h | CER | Acc |
|---|---|---|
| 无热词+原context处理 | 11.28% | 90.15% |
| 有热词+原context处理 | 12.5% | 88.8% |
| 有热词+context scale | 11.59% | 89.8% |
注:热词总计60个,售前50h测试集基本不包含热词列表中的热词。
对context score进行scale,在保证热词正确识别的情况下,可以在对话不包含热词时确保绝大多数的情况下的识别结果不受影响。
总结
这篇文章主要介绍了WeNet语音识别在顺丰科技流式和非流式场景落地的相关工作,包括在性能、效率和用户体验提升上相关的探索。未来我们的工作重点将主要聚焦在噪声环境、口音等复杂场景下语音识别性能、用户体验的提升,以不断完善顺丰科技语音服务。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。