
音频语意概述是一项跨模态音频内容理解任务,旨在通过自然语言描述音频信号蕴含信息,使机器具备理解表达音频场景事件语意内容的能力。现有的主流音频语意概述方法几乎均采用在AudioSet上获得的大规模音频预训练模型(pretrained audio neural networks, PANNs)进行音频特征表示,借助PANNs的音频事件分析能力,提升音频语意概述性能。但PANNs模型受限于所采用的卷积计算机制,缺乏对音频特征时序上下文关系的建模能力,导致现有主流方法的性能受限。为此,本文提出了一种基于图注意力机制的音频语意概述方法(GraphAC),所提方法通过构建音频节点邻接图,实现音频信号中的时序上下文信息关系建模,并通过top-k掩码机制过滤与音频场景内容无关信息,由此强化与音频场景事件相关的上下文语意关联,进而提高音频描述的准确性和流畅性。实验结果表明,GraphAC在音频语意概述任务上获得优于现有的基于PANNs音频编码器(PANNs-based audio encoder)主流方法的概述性能表现,由此验证了图注意力机制在捕获音频时序上下文信息的有效性。本文方法所构建集成系统在第八届国际声学场景和事件检测及分类竞赛(IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events, DCASE 2022 Challenge)音频语意概述赛道(Task 6A)取得了国际第6名。
本文由哈工程智能信号处理组与悉尼科技大学、萨里大学合作,发表于IEEE信号处理学会期刊IEEE Signal Processing Letters,论文一作为2020级硕士研究生肖飞扬。
论文链接:https://arxiv.org/abs/2304.03586
论文代码:https://github.com/LittleFlyingSheep/GraphAC
1. 背景
音频语意概述(automated audio captioning, 又称自动音频字幕)是一项通过机器学习方法将音频信号蕴含场景信息用自然语言进行语意表述的跨模态音频内容理解任务。该任务有助于听力障碍人群感知理解音频信息以辅助其正常生活,同时有助于城市安全监控体系音频内容辅助分析,以及流媒体视频节目内容摘要生成,具备广阔的应用前景。
目前,音频语意概述的主流方法常采用编码器-解码器(encoder-decoder)结构,其中编码器负责提取音频特征,解码器负责根据音频特征生成描述文本。近年来,得益于在大规模音频数据集(AudioSet)上学习到的音频事件信息表征能力,大规模音频预训练模型PANNs被广泛用于音频语意概述方法的编码器设计,由此提升了音频语意概述方法的性能表现。
2. 动机
然而,PANNs所采用卷积计算机制主要用于捕捉局部感受野(即局部时频区域)信息,往往忽略音频特征之间的上下文关联和长时序依赖性质。而由于音频信号是一种典型的时变信号,包含了丰富的时序上下文信息,此类信息可以反映声音场景和事件的语意关联。忽略音频时序上下文信息,将会影响音频编码器对于音频特征的有效建模,从而限制音频语意概述方法性能。
3. 方法
为了解决上述PANNs音频编码器难以表征时序上下文信息的问题,本文提出了一种基于图注意力机制的音频语意概述方法,即GraphAC。该方法在编码器中引入了一个图注意力模块,该模块可以实现音频节点的图关系建模,实现音频上下文关系挖掘,增强音频特征帧节点之间语意关联,提升音频特征表示能力。GraphAC以P-Transformer方法作为原型系统,验证所提图注意策略的有效性。所提方法以P-Transformer为骨干网络,在其音频编码器中的PANNs之后引入图注意力模块,以此实现音频时序上下文关系建模及语意信息关联;解码器设计部分,沿用了P-Transformer解码器结构设计,通过Transformer解码器结构实现音频特征表示的自然语言文本表述。
所提出的图注意力音频特征表示策略,不仅通过构建邻接图捕获音频信号中的时序上下文信息(即音频特征帧节点之间的上下文关联),还采用top-k掩码机制减轻了噪声节点干扰;此外,图注意力机制在节点特征聚合过程中,还可以根据邻接图反映的时序上下文信息,强化音频特征表示中有关声音场景事件的重要语意信息。因此,所提出方法可以解决现有PANNs音频编码器不足,有效捕获音频特征的时序上下文信息,提升音频语意概述性能。所提出方法模型结构图如下:
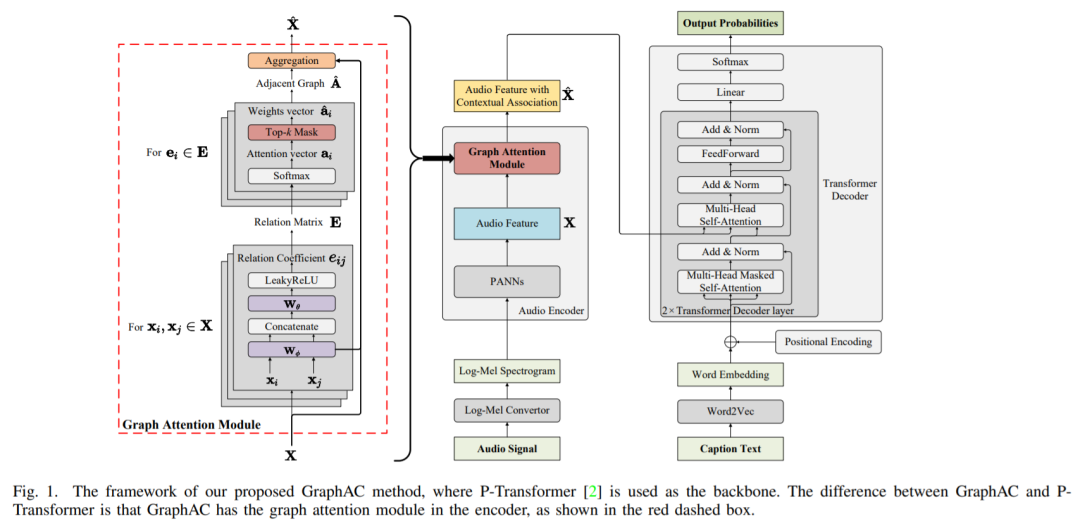

4. 实验
对比实验
本文使用Clotho数据集进行音频语意概述方法的性能评估。Clotho数据集包含开发集、验证集、评估集三部分,其中分别有3839、1045、1045条音频信号。Clotho数据集中的音频信号时长范围在30秒以内,每条音频信号有5条标注好的自然语言文本概述作为标签。实验采用音频语意概述词汇精度评价指标BLEU、ROUGEl、METEOR,以及语意评价指标CIDEr、SPICE和SPIDEr,对所提方法进行性能评价。实验结果如下表所示: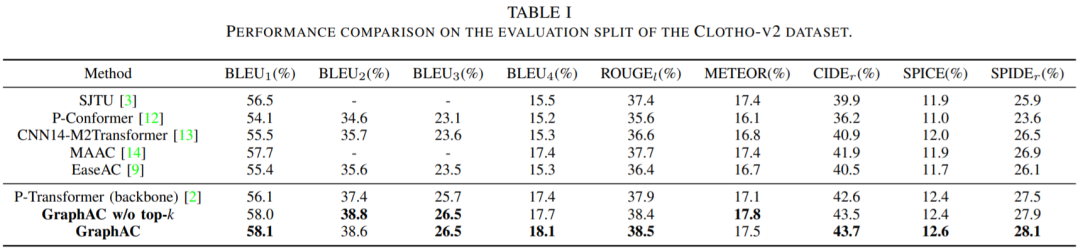
本文实验中对比了采用PANNs作为音频编码器的现有主流音频语意概述方法,包括P-Transformer、SJTU、P-Conformer、CNN14-M2Transformer、MAAC和EaseAC。实验结果表明,本文所提的GraphAC方法的音频语意概述性能优于当前使用PANNs作为编码器的主流方法。
消融实验
需要注意的是,P-Transformer方法可视作本文所提出的GraphAC方法不使用图注意力机制的退化版本。本文对比了在编码器结构中使用图注意力机制的方法(GraphAC)和不使用图注意力机制的方法(P-Transformer),以验证图注意力机制进行音频特征建模的有效性。实验结果表明,借助图注意力机制捕获音频特征的时序上下文信息,可以获得优于仅采用PANNs作为音频编码器方法的音频语意概述性能。
此外,为进一步验证本文所提出的GraphAC方法在音频特征时序上下文建模中的有效性,本文给出可视化分析过程,如下图所示。可视化分析中,每一列分别对应一个输入音频样例,左侧一列对应的音频样例为01 barreau bunker original.wav,其参考概述文本为“five different sounding bells are ringing between short pauses”,右侧一列对应的音频样例为01 A pug struggles to breathe 1_14_2008.wav,其参考概述文本为“a small dog snoring and groaning”。下图中,(a)和(b)表示音频信号的频谱图特征;(c)和(d)表示所提GraphAC方法构建的音频特征帧之间邻接图关系;(e)和(f)表示所提GraphAC方法不使用top-k掩码机制时(即GraphAC w/o top-k方法)构建的音频特征帧之间邻接图关系。

对比可视化分析图中的(a)和(c)、(b)和(d),可以发现所提GraphAC方法构建的邻接图关系中的高亮部分(重要性高的音频帧)与音频信号的频谱图特征中的音频场景事件基本对应,这表明所提的GraphAC方法能够有效捕获音频特征中与场景事件信息相关的重要语意信息。由此可以说明,所提的GraphAC方法可以建立音频特征帧节点上下文关系,并强化音频场景内容信息和语意关联。
为验证GraphAC方法中top-k掩码机制的作用,本文在消融实验中还与未使用top-k掩码机制的GraphAC w/o top-k方法进行对比分析。表1中量化评价指标表现表明,GraphAC方法的语意评价指标性能表现要优于GraphAC w/o top-k方法,使用top-k掩码机制能够提升音频语意概述方法的语意概述性能。而对比图2可视化分析中的(c)和(e)、(d)和(f),可以发现不使用top-k掩码机制时,所提方法构建的邻接图关系会存在无意义的关联信息干扰(如蓝色框)与上下文关系失真(如绿色框)的问题,这表明top-k掩码机制能够一定程度上过滤与场景内容无关的音频信息,提升音频语意概述的表现。本文模型以及预测的音频语意概述文本示例可以在论文代码项目中获得。
结论
本文针对基于PANNs音频编码器难以发掘音频特征时序上下文信息的不足,从音频特征帧节点的时序上下文关系出发,通过图注意力机制构建了音频特征帧之间的邻接图结构,并应用top-k掩码机制过滤了与场景内容无关的音频信息,进而捕获了音频特征的时序上下文关系,并强化了音频场景上下文语意关联。实验结果表明,所提的GraphAC方法能够取得优于基于PANNs音频编码器的现有主流方法的音频语意概述性能表现。
编辑:关 键
校对:肖飞扬 张合静
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。