
本文提出了一个深度视频预编码框架,其核心预编码组件包括一个级联结构的降尺度神经网络,在视频编码期间,传输之前操作。这与每个可独立解码的流段的预编码模式选择算法相结合,该算法根据场景特征、所使用的编码器以及所需的比特率和编码配置调整降尺度因子。该框架与所有当前和未来的编解码器和传输标准兼容,因为该深度预编码网络结构是与线性上采样滤波器(例如双线性滤波器)一起训练的,所有网络视频播放器都支持这种滤波器。
来源:TCSVT 2019
论文链接:https://ieeexplore.ieee.org/document/8933383
作者:Eirina Bourtsoulatze , Aaron Chadha and Yiannis Andreopoulos
内容整理:王妍
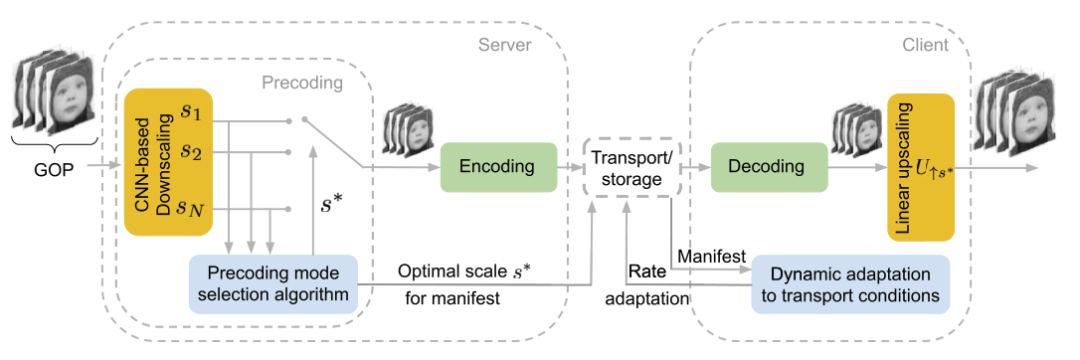

本文的主要贡献:
- 视频传输深度预编码的概念被引入,作为增强任何视频编解码器的码率失真特性的手段,而不需要在客户端/解码器端进行任何更改;
- 提出了一种多尺度预编码 CNN,该 CNN 在多个尺度因子上对高分辨率帧进行降尺度,并经过训练以减轻标准线性上采样滤波器产生的混叠和模糊伪影;
- 提出了一种自适应预编码模式选择算法,该算法在编码前自适应选择最优分辨率。
多尺度预编码网络
虽然任何降尺度方法都可以与上图中的视频预编码框架一起使用,但为了以数据驱动的方式增强性能,本文引入了一个多尺度预编码神经网络。预编码网络由一系列 CNN 预编码块组成,这些块在多个比例因子上逐步降低高分辨率 (HR) 视频帧的尺寸。该方法使得视频播放器端的标准线性上采样器能够更好地恢复信息。这与当时的图像升尺度架构完全相反,后者采用简单的双三次降尺度和视频播放器端极其复杂的超分辨率 CNN 架构。例如,EDSR 包含超过 4000 万个参数,对于 30-60 帧/秒 (fps) 的FHD/UHD视频来说,这在客户端是非常不切实际的。
网络体系结构
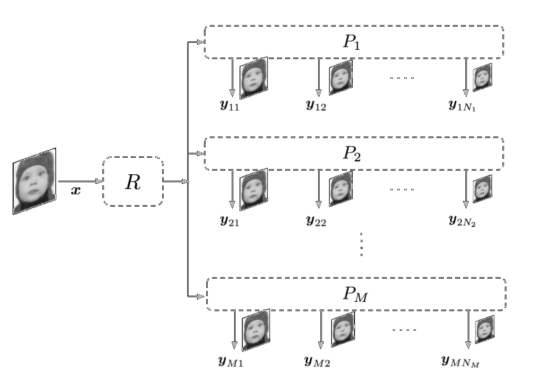
预编码网络的总体结构如图所示。它由一个“根”映射R和M个并行预编码流 pm 组成。网络根据集合 S 中的尺度因子逐步将单个亮度帧 x ∈ RHxW (其中 H 和 W 分别为高和宽)降尺度。考虑到人眼对亮度信息最敏感,预编码网络只处理亮度 (Y) 通道,而不处理色度 (Cb, Cr) 通道,以避免不必要的计算。实际上,在所有三个通道上训练网络会因为网络陷入糟糕的局部最小值而使性能恶化。此外,这样的设计还允许色度子采样(例如,YUV420),因为色度通道 (Cb,Cr) 使用标准双三次滤波器独立地降尺度。
根映射
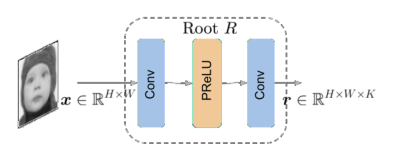
根映射 R 由两个卷积层组成,从输入 x 中提取出一组高维特征映射 r ∈ RH x W x k, 其中 K 为根映射的输出通道数。根映射 R 构成了所有预编码流和比例因子中常见的不太抽象的特征(如边)。因此,该模块在所有预编码流之间共享,这有助于降低复杂性。
预编码流
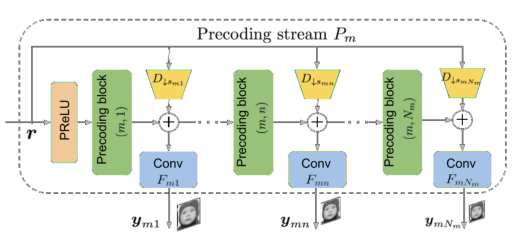
提取的特征映射 r 被传递到预编码流。预编码流 Pm 由一系列 Nm 预编码块组成,它在比例因子子集 Sm 上逐步降低输入的尺度。
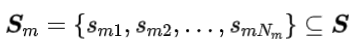
在预编码流中分配比例因子的方式是:
- 复杂度在流之间平等共享,以实现高效的并行处理
- 流中大多数连续的比例对 Sm(n-1),Smn 的比值是恒定的,即
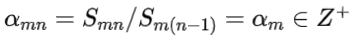

预编码块
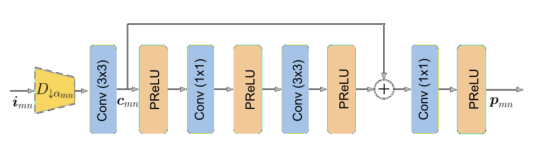
预编码块是预编码框架的主要组成部分,由交替的 3 × 3 和 1 × 1 卷积层组成,每一层后面都跟随一个参数 ReLU (PReLU) 激活函数。1 × 1 卷积被用作信道减少的有效手段,以减少用于计算的乘累加 (mac) 的总体数量。第 m 个预编码流中的第 n 个预编码块有效地将原始高分辨率帧按尺度因子 smn 降尺度。将预编码块的输入记为 imn ,预编码块的第一卷积层 Cmn 的输出记为 cmn ,空间步长记为 k。线性降尺度操 Dαmn 仅在第一卷积层中无法通过步长实现到目标分辨率的降尺度时执行,以降低复杂度。

模式选择算法
模式选择算法在每个 GOP、比特率和编解码器的基础上运行。模式选择的目标是确定每个 GOP 的最优预编码比例因子。预编码模式选择算法包括三个步骤。第一步是获得每种预编码模式(尺度)的率失真特征。S = {s1,s2,…,sN}是包括原始分辨率的比例因子完整集。利用多尺度预编码网络将每个 GOP 段 g 预编码为 S 中所有可能的尺度。 hi表示 GOP g 使用比例因子 si 的预编码版本。然后用视频编码器的预设和编码参数编码 GOP g 的所有预编码版本。因此,每个比例因子 si 都有一个对应的 GOP 编码,在解码和升尺度到原始分辨率后,在 RD 平面上产生一个率失真点( Ri , Di )。为了进一步加速这一步骤,引入了一个“足迹”过程:不是对 GOP 的所有帧进行编码,而是只对少数帧进行选择性编码,例如,只保留 GOP 中的每隔 n 个帧。这大大加快了初始编码步骤,特别是如果考虑多种预编码模式,因为每个比例因子需要预编码和编码的帧数减少了 n 倍。第二步是剪枝。首先,消除 RD 点不提供单调递减的 RD 曲线的预编码模式。即对于每一个预编码模式 i,如果存在一个预编码模式 j,使得 Rj ≤ Ri 且 Dj < Di ,则 预编码模式被修剪掉。如果在此消除过程后,剩余的预编码模式数大于 2,则通过剔除 RD 点不在剩余 RD 点的凸包上的模式,进一步修剪预编码模式。最后一步,使用恒定比特率编码 (CBR) 对剩余的预编码版本 hi 进行重新编码。用于 CBR 编码的比特率等于剪枝步骤后剩余的所有 RD 点比特率的平均值。将剪枝过程后剩余的 RD 点重新映射到一个公共比特率值后选择最优的预编码模式 s* ——在重新映射的 RD 点集中提供最低失真的模式。

损失函数

实施及训练细节
在提出的多尺度预编码网络中,使用 Xavier 初始化的方法初始化所有的内核;使用 PReLU 作为激活函数;使用零填充来确保所有层都是相同的大小;降尺度仅由下采样操作控制,例如步幅或线性降尺度过滤器。根映射 R 由单个 3 × 3 和 1 × 1 卷积层组成,所有 1 × 1 和 3 × 3 卷积层中的通道数分别设置为 4 和 8 (不包括 Fmn ,它使用 3 × 3 的核大小,但只有一个输出通道)。
最终的并行实现包括三个预编码流 P1 , P2和 P3,尺度因子集 S \{1} 划分为三个子集: S1 = {4/3,2,4},S2 = {3/2,3,6} 和 S3 ={5/4,5/2}。这些尺度因子包含了 DASH/HLS 流系统中使用的所有代表性比例因子,并提供了更高灵活性的其他比例因子。训练数据集为 DIV2K,用 Adam 优化器训练所有模型,批大小为 32,迭代 20 万次。初始学习率设置为 0.001,在 100k 次迭代时衰减 0.1 倍。训练过程中使用数据增强,随机翻转图像,并从 DIV2K 图像中随机提取 120 × 120 的切片。所有实验均在 NVIDIA K80 GPUs上的 Tensorflow 中进行。本文不使用 Tensorflow 内置的线性图像调整函数,并从头重写所有线性升尺度/降尺度函数,以便它们与标准的 FFmpeg 和 OpenCV 实现匹配。
实验结果
内容和测试设置
测试内容包括 16 个 FHD (1920 × 1080) 和 14 个 UHD (3840 × 2160) 标准视频序列,来自 XIPH 集合的 8 位 YUV420 格式。FHD 帧率在 25fps 到 50fps 之间。UHD 帧率均为 60fps。性能是根据平均 PSNR 和平均 VMAF 来衡量的,使用 Netflix 提供的工具计算。PSNR 和 VMAF 都是在解码和双线性滤波器上采样后,在原始分辨率帧上计算的。
预编码模式的评估
首先比较了所提出的多尺度预编码网络的性能与双三次和 Lanczos 滤波器的性能,这是所有主流编码库(如 FFmpeg) 支持的两个标准降尺度滤波器。具体设置为:“medium” 预设,两种通过率控制模式,GOP = 30,比特率范围 0.5 – 10Mbps。
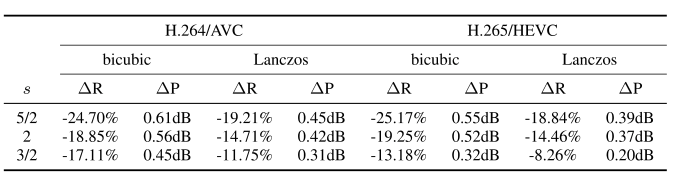
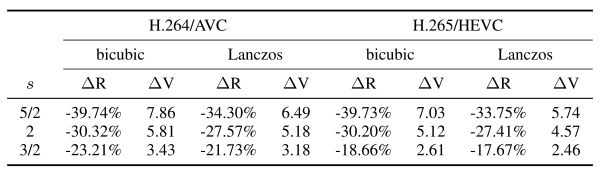
上面两个表格分别为相对 PSNR 和 VMAF 的 BD-rate 增益。本文的预编码被证明在所有模式下都优于双三次和 Lanczos 降尺度。对于 PSNR,其 BD-rate 的增益范围为 8% ~ 25%,而对于 VMAF,其 BD-rate 的增益范围为 18% ~ 40%。

上图给出了比例因子 s = 5/2 时 PSNR 和 VMAF 的指示率失真曲线,表明所提出的预编码网络的性能始终优于传统的降尺度滤波器。虽然在较高比特率时增益增加,但在低比特率区域也观察到大量增益。具体而言,对于 PSNR, 0.5-2Mbps 比特率区域,相对双三次 (Lanczos) 降尺度下的 BD-rate 和 BD-PSNR 增益分别为 10.54%(6.9%) 和 0.27dB (0.18dB)。对于 VMAF,在相同的低比特率区域,相对双三次 (Lanczos) 降尺度下的 BD-rate 和 BD-VMAF 增益分别为 29.29% (24.74%) 和 5.94(4.91)。

上图显示了分别用所提出的预编码网络,以及 Lanczos 和双三次降尺度滤波器以 5000kbps 编码的帧的示例片段。图中显示的视觉保真度的提高也体现在 VMAF 的指示率失真曲线中 5Mbps 点所显示的(大约) 10 点平均 VMAF 差异中。
自适应预编码框架的评价
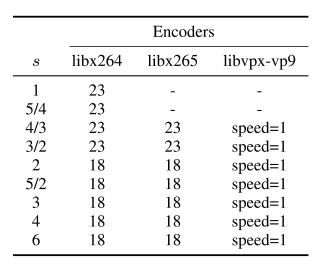
然后评估整个自适应视频预编码框架,将其(用 “iSize” 表示)与 H.264/AVC,H.265/HEVC,VP9 结合后与原本的编码器进行比较。使用加速因子为 5 的足迹,即在选择最佳预编码模式时只处理每隔 5 帧,并使用与相应基线编码器相同的编码配置。对于 H.264/AVC 和 H.265/HEVC ,对 libx264/libx265 采用高度优化的 “slower” 预设和 VBV 编码,GOP=90,对 VBV 采用广泛使用的 crf=23 配置。对于本文提出的方法,采用(每个编解码器)下表所示的预编码模式和 crf 值。
为了说明收益是通过视频点播 (VOD) 编码设置实现的,对于 H.264/AVC,还包括使用 MULTI_P ASS_HQ H.264/AVC 配置文件的高性能 AWS MediaConvert 编码器及其最近宣布的高性能 QVBR 模式(默认值为质量级别 7) 的结果。结果表明,相对于 H.264/AVC libx264 实现,在两个指标(PSNR 和 VMAF)下,结合自适应预编码后对于 FHD 和 UHD 的平均比特率节省为 35%;与 H.264/AVC AWS MediaConvert 相比,平均节省了 44%。对于 H.265/HEVC libx265,平均节省了 15%。
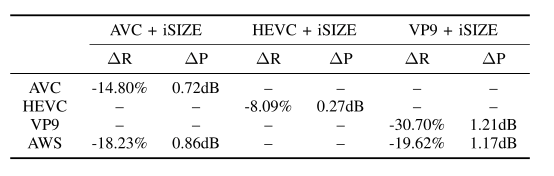
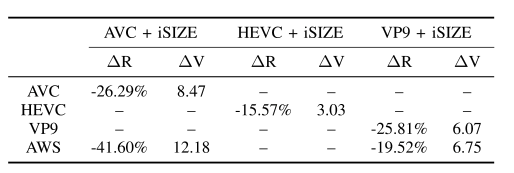
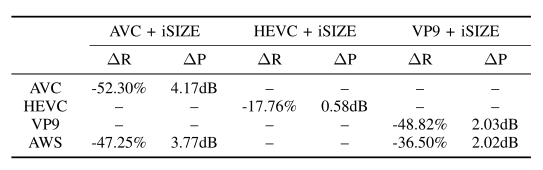
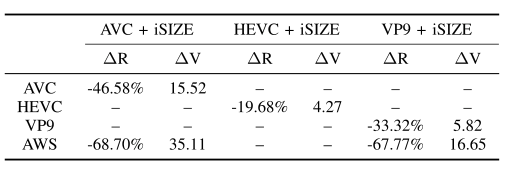
对于 VP9,因为只使用原始分辨率的 6% 到 64% 的视频像素的缩小版本,本文使用最小-最大比特率的 VBV 编码,GOP=90 帧,maxrate = 1.45 × minrate,低分辨率编码的 speed = 1,全分辨率编码的 speed = 2。结果表明,相对于 VP9 libvpx-vp9 实现,结合自适应预编码后对于 FHD 和 UHD 的平均比特率节省为 35%;相对于 VP9 AWS Elastic Transcoder 的平均节省是 36%。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。