
视频剪辑是大家生活中经常使用的工具,现有的视频剪辑软件支持种类丰富的视频裁剪、编辑功能。对于一个长视频,剪辑出里面需要的视频片段,往往需要花费很长的时间来浏览视频,剪辑需要的音视频片段。
ClipVideo剪辑工具结合了达摩院语音实验室在Modelscope社区开源的语音识别相关能力,通过语音转文字,以及根据文字内容,快速裁剪出对应的视频片段,提升音视频剪辑的效率。
仅需通过上传视频、识别、复制所需文字片段、裁剪几个简单的步骤,用户可以快速方便的获取所需的视频片段,并且自动生成字幕。
ClipVideo的demo已经上线到Modelscope创空间👇:
https://modelscope.cn/studios/damo/funasr_app_clipvideo/summary
相应的工具包也在Github进行了开源👇:
https://github.com/alibaba-damo-academy/FunASR-APP
如何使用ClipVideo?
方法一:通过Modelscope创空间,在线便捷体验ClipVideo的DEMO;
方法二:通过源代码将ClipVideo服务部署在本地。
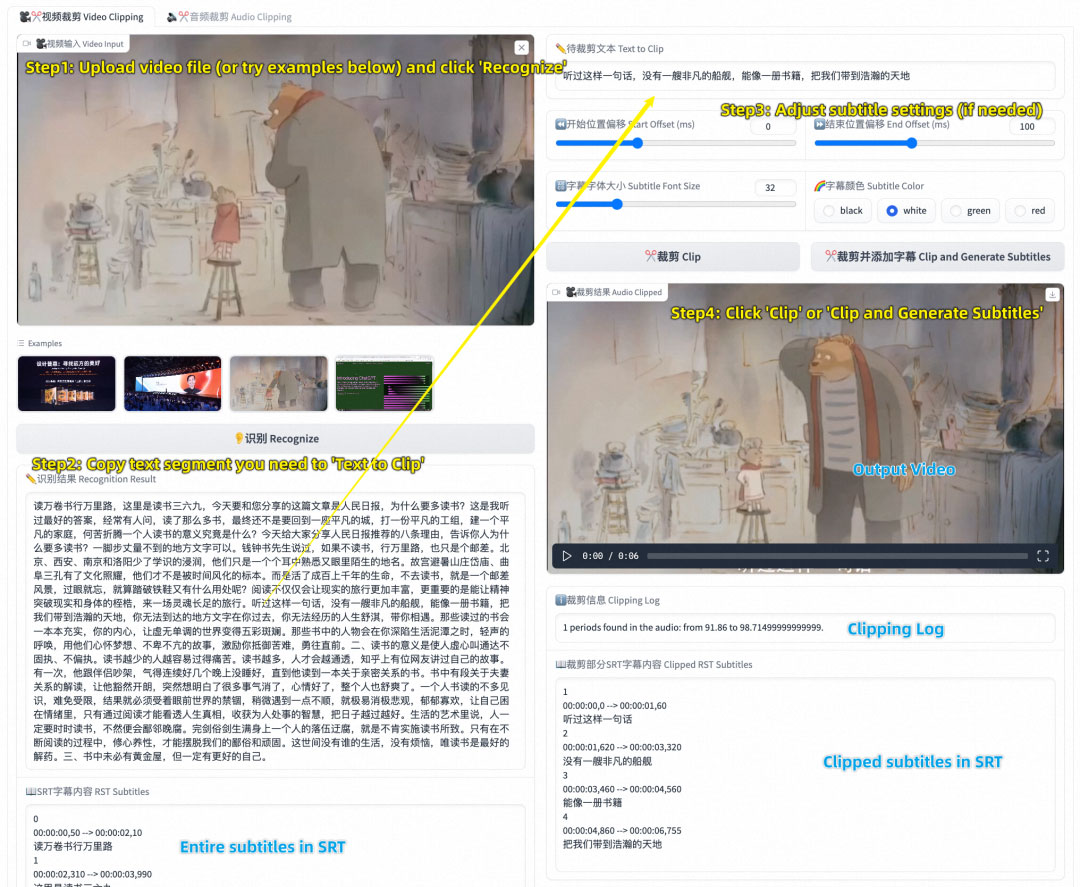
用户可以通过上述两种方式使用基于Gradio交互的ClipVideo服务,其界面设置如下,按以下三个步骤可以快速获取根据文本截取的视频片段:
(1)上传视频文件,点击“识别”按钮进行识别;
(2)复制识别结果中的文字段落至“待裁剪文本”处;
(3)配置字幕设置(可选),点击“裁剪”或“裁剪并添加字幕”按钮。
对于有批量处理文件需求的用户,ClipVideo支持通过命令行的方式交互,详见Github。

ClipVideo背后的语音技术
ClipVideo方便准确的裁剪的背后是达摩院语音实验室自研的一系列语音相关模型,包括语音端点检测(Voice Activity Detection, VAD),语音识别(Automatic Speech Recognition, ASR),标点预测(Punctuation Restoration)及时间戳预测(Timestamp Prediction, TP)。ClipVideo按如图2所示的逻辑组成了完整的交互链路。
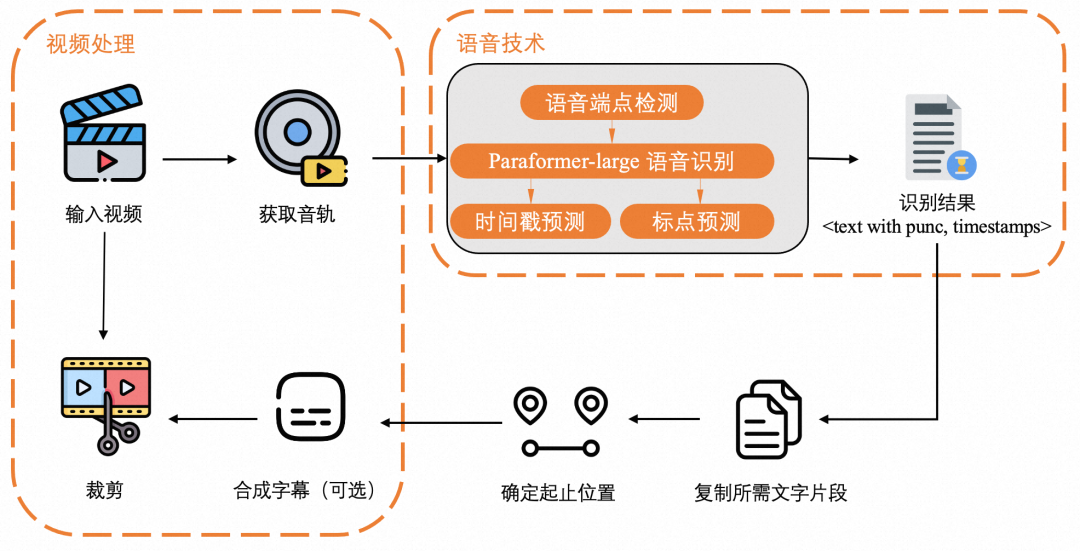
为了准确而高效的识别(可能较长的)输入视频,ClipVideo调用了Paraformer-Large-长音频版识别模型,其链路中包含FSMN-VAD模型,支持时间戳预测的BiCIF-Paraformer-Large ASR模型以及CT-Transformer标点预测模型。
其中BiCIF-Paraformer-Large ASR模型是达摩院新一代端到端ASR方案,兼具AED(attention-encoder-decoder)框架的离线ASR准确性与非自回归(non-autoregressive)方案的高效率,并且使用额外的CIF头在多倍帧率的情况下进行帧权重预测从而得到时间戳,省略了传统时间戳预测所需要的额外的hybrid force-alignment模型(图3)。
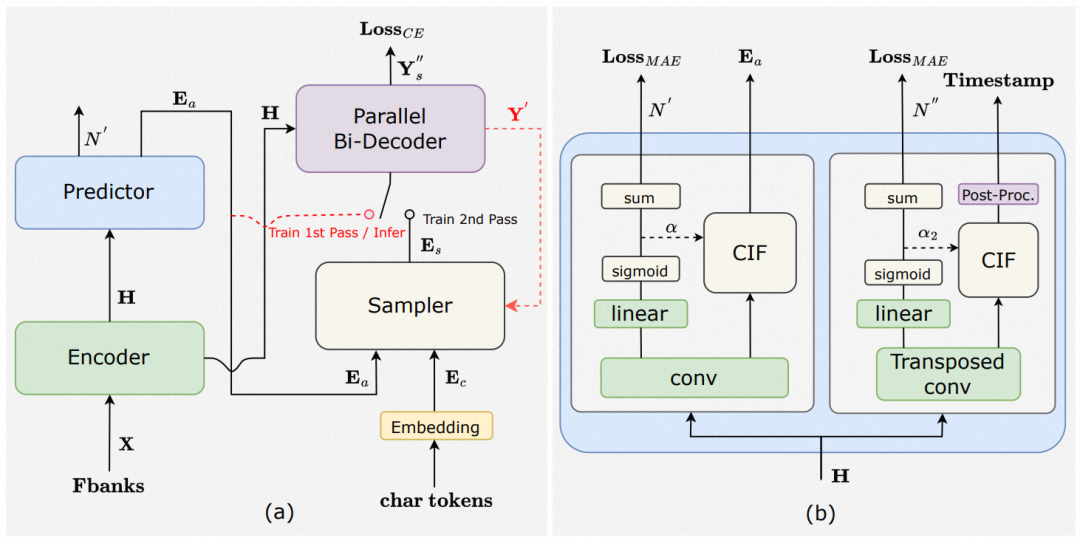
实验表明,Paraformer-Large模型的ASR准确率与时间戳预测准确率均为优异。
具体参见FunASR论文:https://arxiv.org/pdf/2305.11013.pdf
上述全部模型均已在ModelScope和FunASR社区进行了开源:https://github.com/alibaba-damo-academy/FunASR
上述全部模型均可以在modelscope上体验与下载:https://modelscope.cn/models?page=1&tasks=auto-speech-recognition&type=audio
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。