
Total-Recon 是第一种从单目 RGBD 视频中逼真地重建可变形场景的方法。为了扩展到长视频,该方法将场景运动分层分解为每个对象的运动,而每个对象的运动本身又被分解为全身整体运动和局部关节运动。
文章来源:arXiv
项目链接:https://andrewsonga.github.io/totalrecon/
作者:Chonghyuk Song, Gengshan Yang, Kangle Deng, Jun-Yan Zhu, Deva Ramanan
内容整理:王睿妍
引入
Total-Recon探索了具体化视图合成,这是一类新的新颖视图合成任务。它根据对象在场景中的运动所重建的6自由度轨迹来呈现可变形的场景:以自身为中心的相机模拟了运动对象的视角,第三人称跟踪摄像机从后面跟踪移动对象。Total-Recon专注于人类与宠物互动的日常场景,从人和宠物的角度生成渲染,如下图所示。相比于依靠从 8 到 18 个静态相机的专用相机设备捕获的同步多视图视频来实现的方法,Total-Recon 只需要从配备惯性传感器的移动 RGBD 相机捕获的单个视频,随着 Apple 的 iPhone 和 iPad Pro 的出现,这现在在消费产品中得到了广泛的应用。
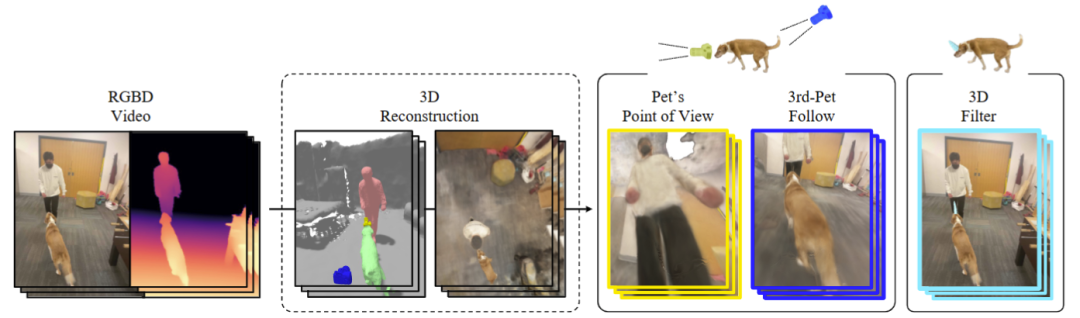

挑战
构建具体化视图合成系统具有挑战性。首先,重建日常内容需要处理多个交互参与者的长、单目捕获视频。然而这种视频可能包含大的场景动作,很难用目前的方法重建。其次需要生成支持自由视点合成的可变形 3D 场景表示,这也需要从不同视点捕获场景的长视频。最近的方法将神经辐射场 (NeRF)扩展到可变形场景,但这项工作通常仅限刚性物体运动、场景运动有限的短视频,或重建单个对象而不是整个场景。第三,需要计算多个参与者全身整体和局部部位(如头部)的全局六自由度轨迹。
贡献
- Total-Recon 将变形场景建模为以对象为中心的表示组合,每个表示都将对象运动分解为其全局身体和局部关节运动
- 基于 Total-Recon 的系统被用于从高度动态场景的自由视角、分钟级长度的 RGB 视频合成自动具体化视图;
- 提出在许多不同的背景环境中包含各种变形对象(例如人和宠物)的立体 RGB 视频数据集。
具体实现
现有的单目可变形 NeRF 很难扩展到分钟级长度的视频,因为时长的增加可能会包含姿态和动作的更大范围变化,从而使优化复杂化;另一个限制是它们无法跟踪单独的变形对象,因此无法对有多个参与者的场景执行第三人称跟随视图合成。给定一个单目 RGBD 视频,Total-Recon 将场景重构为以对象为中心的表示的组合,对每个可变形对象和背景的三维外观、几何和运动进行编码。至关重要的是,Total-Recon 将场景的运动分层分解为单个对象的运动,单个对象被分解为全身运动和关节部位的局部变形。
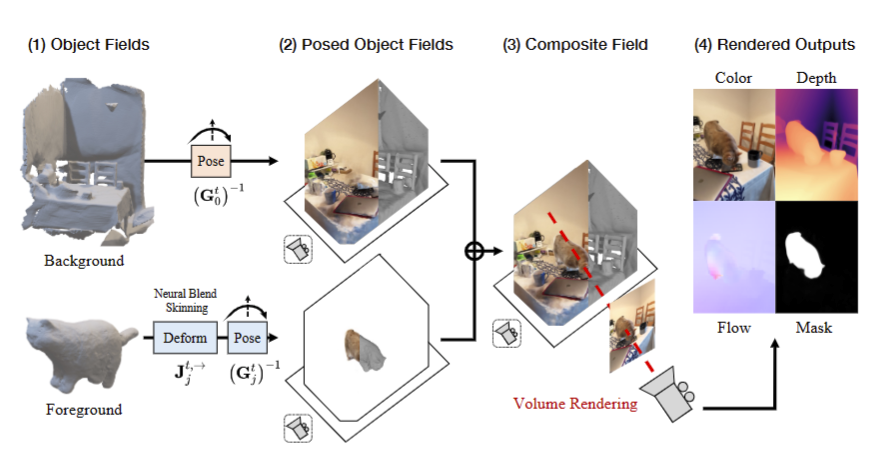
组合辐射场
为了解决现有单目可变形 NeRF 的局限性,Total-Recon 将可变形场景建模为 M 个以对象为中心的神经场的组合,其中一个用于刚性背景其余 M−1 个用于可变形对象,如下图所示。Total-Recon 将场景运动分层分解为每个对象的运动,每个对象又被分解为全局身体和局部关节运动,这种关键的设计将方法扩展到包含高度动态和可变形对象的分钟级长度视频。


多个对象的复合渲染
给定一组 M 个对象的表示(背景也被视为一个对象),Total-Recon 使用与 GIRAFFE 工作中的复合渲染方案来组合所有对象的输出,并体渲染整个场景。在帧 t 处对图像进行体渲染时,沿每个相机光线 vt 采样多个点。将第 i 个采样点表示为 Xti,我们将对象 j 的第 i 个采样点的密度和颜色写为:


通过将对象颜色 cij 替换为其它定义的 3D 特征 fij 并渲染得到的合成特征 fi,可以使用组合渲染方案来渲染不同的量。

实验
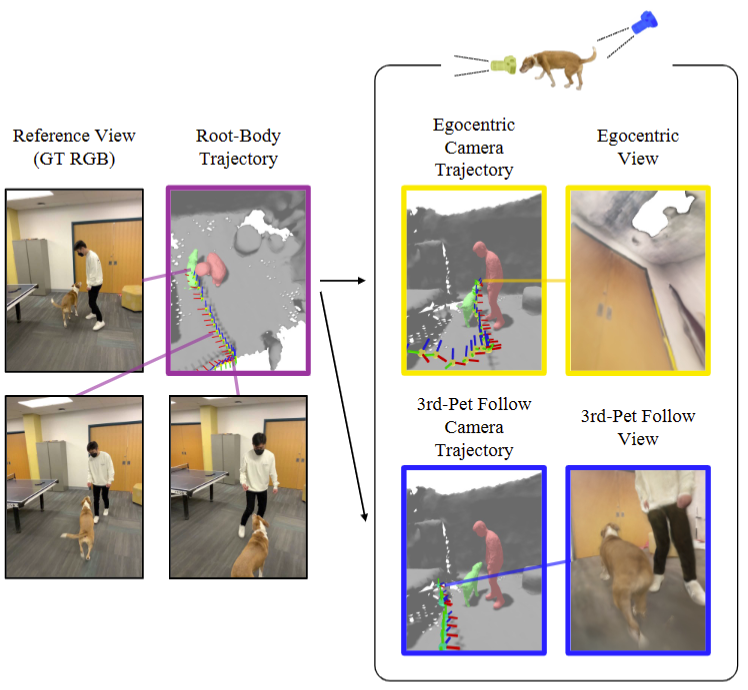
通过将场景运动分层分解为每个对象的运动,该运动本身被分解为整体和局部关节运动,Total-Recon 自动计算新的 6-DoF 轨迹,例如以自我为中心的相机和第三人称跟随相机所穿越的轨迹,如下图所示。
数据集
为了实现定量评估,Total-Recon 构建了一个立体装置,由两个刚性连接到相机支架上的 iPad-Pros 组成,设置类似于 Nerfies。在 4 个不同的室内环境中捕获了 11 个 RGBD 序列,包含 3 个不同的猫、1 条狗和 2 个人类对象 。RGBD 视频是使用 Record3D iOS App 捕获的,并自动注册每个相机捕获的帧。
定性结果
如下图所示,将 Total-Recon与 HyperNeRF 和 D2 NeRF 的深度监督进行了比较(左侧摄像头用于训练,右侧摄像头用于测试),Total-Recon 成功重建了整个场景,而基线最多只能重建刚性背景。

定量结果
如下表所示,Total-Recon 在 LPIPS 和 RMS 深度误差方面也显著优于所有基线,这是由于基线的方法无法重建移动的可变形物体。

限制
在 Total-Recon 中,场景分解主要由现成的分割模型计算的对象轮廓监督,这可能不准确,尤其是在部分遮挡场景中,因此可能会影响生成的重建和视图渲染。其次,Total-Recon使用为人类和四足动物训练的 PoseNet 来初始化每个可变形对象的身体姿势,该PoseNet不适用于其他对象类别(例如,鸟、鱼)。除此以外,模型需要在每个序列的基础上使用 4 个 NVIDIA RTX A5000 GPU 优化大约 15 小时,因此不适合实时应用程序。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。