
在过去的五年中,AWS 的北弗吉尼亚集群(即US-EAST-1)至少发生了三次引发重大互联网瘫痪的事件。
每项服务各不相同,而如今系统间存在如此多的依赖关系和耦合,很难不受此类事件的影响。不过,对于 WebRTC 平台而言,处理单个 AWS 区域宕机的情况应该相对简单。
WebRTC 基本架构
大多数 WebRTC 平台的基本架构包含四个组件:
- 负载均衡服务:客户端应用程序的初始接触点,为会话选择合适的媒体服务器。
- 数据库:存储服务器信息(状态、负载、位置)和会话到服务器的映射,通常使用像 Redis 这样的快速数据库。
- 信令服务:管理会话状态并转发控制消息。本文假设它是媒体服务器的一部分,因此在以下图表中将其忽略。
- 媒体转发服务:核心组件,负责在参与者之间路由音频和视频。它通常是无状态的,并会报告其状态。


整个解决方案通常包含其他组件来管理诸如录制或防火墙穿越之类的事情,但为了本次讨论的目的,这些组件将被忽略。而且,无论如何,它们通常是无状态的,并且很容易使其在出现网络问题时保持健壮。
分布式 WebRTC 架构
当你想要提供最佳质量时,你会在多个区域部署媒体服务器,这时候的架构通常如下所示:

根据我的经验,这是最常见的部署方式,但很明显,存在一个中心故障点,该故障点可能是数据库,也可能是负载均衡服务 + 数据库,具体取决于你的部署方式。
稳健的分布式架构
如果负载均衡服务和数据库在它们所在区域发生故障时出现问题,那么解决方案显而易见,我们只需复制它们即可。
复制负载均衡服务很简单,将其部署到所需的任意多个区域(理想情况下是所有区域),并使用以下方法之一在最近的区域发生故障时故障转移到其他负载均衡器:
- 依靠健康检查和较短的 DNS 超时时间。这样,如果出现故障,DNS 服务器会将某些区域标记为不可用,并将客户端请求路由到其他区域。但如果 DNS 服务(例如 Route 53)出现故障,这可能会造成问题。
- 将客户端配置为回退到不同的 URL(例如 api.domain.com 和 api-backup.domain.com)。
复制数据库稍微复杂一些,最常用的方法有以下几种:
- 最简单的方法是采用主备模式,即维护多个数据库实例,但同一时间只使用其中一个,其他实例仅负责复制数据。一旦发生故障,我们会通过监控流程手动或自动将查询迁移到其中一个副本上。
- 更先进的方法是采用分片的双活架构。这种方法更复杂,但可行,并且具有分散负载的额外优势。
- 您可以使用像 Azure Spanner 这样的分布式数据库。但如果该分布式数据库包含一些中心组件,则可能会比较棘手,就像上次 AWS 服务中断时 DynamoDB 的情况一样。
最终架构图如下所示:
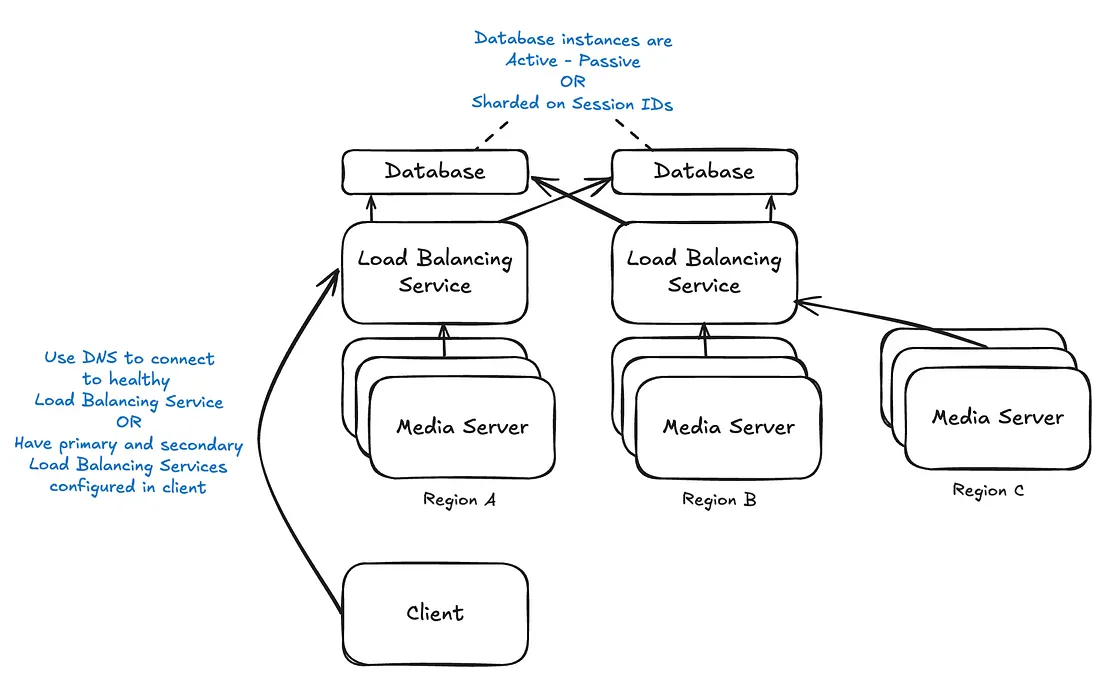
通过以上提出的解决方案,你的 WebRTC 基础架构应该能够抵御影响云提供商单个区域的所有问题。
当然,还可以更进一步,例如部署在多个提供商(AWS、GCP、Azure 等)上,或者使用自己的基础设施,但除非是真正关键的软件,或者出于成本或合规性等其他原因需要这样做,否则我不建议这样做。
作者:Gustavo Garcia
来源:https://medium.com/@ggarciabernardo/webrtc-architecture-that-keeps-working-when-us-east-1-goes-down-25ae994dc781
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/webrtc/65561.html