
论文题目:Towards Building Speech Large Language Models for Multitask Understanding in Low-Resource Languages
作者列表:邵明辰,穆秉甡,王成有,李海,闫影,付中华,谢磊
合作单位:爱奇艺
论文原文:https://arxiv.org/abs/2509.14804
开源地址:https://huggingface.co/datasets/mcshao/Thai-understanding
背景动机
近年来,大语言模型在文本理解、生成与推理等自然语言处理任务中表现卓越,推动了语音大语言模型的快速发展,使其可直接处理语音输入,并在自动语音识别、意图分类等多类口语理解任务中取得亮眼成果。当前主流 SLLMs 采用 “预训练语音编码器 + 适配器 + LLM” 架构 [1],在英、中等高资源语言的多任务理解中性能优异,但在泰语等低资源语言场景下,其效果受到极大制约,核心存在三大痛点:现有语音编码器(如 Whisper 系列)在低资源语言上表现欠佳且仅适配少量任务,难以支撑多任务理解;基于自动语音识别的语音 – 文本对齐方式需训练整个 SLLM,计算成本高昂且无法实现通用对齐;低资源语言的多任务口语理解标注数据极度稀缺,远无法满足 SLLMs 的训练需求 [2]。
为解决低资源语言 SLLMs 多任务理解的核心难题,本文以泰语为典型研究对象,提出一套集专用语音编码器、高效通用对齐方法、规模化数据生成方案于一体的综合性解决方案。现有泰语语音编码器仅基于有限 ASR 标注构建,多任务处理能力不足,且泰语领域尚无可用的口语理解标注数据,成为 SLLMs 落地的关键障碍。对此,我们针对性提出三项核心创新:打造首个泰语自监督学习语音编码器 XLSR-Thai,基于 3.6 万小时泰语无标注语音对 XLSR 模型持续预训练,实现声学与语言信息的全面捕捉;设计通用语音 – 文本对齐方法 U-Align,脱离 LLM 直接将适配后的语音表征与文本嵌入对齐,大幅降低计算成本且提升多任务适配性;构建泰语口语理解数据生成流水线 Thai-SUP,从高资源英语文本语料出发,经大语言模型数据增强、翻译、语音合成等步骤,生成首个超 1000 小时的泰语多任务口语理解开源数据集,覆盖意图分类、命名实体识别、语音改写三大任务。
实验结果验证,XLSR-Thai 有效提升了泰语 ASR 性能与多任务理解能力,U-Align 相较传统 ASR 对齐方式,在更低计算成本下实现了各任务精度的全面提升。本文提出的方案具备语言无关性与可迁移性,为低资源语言构建高性能多任务理解 SLLMs 提供了全新可行路径。
提出的方法
为构建在低资源语言中具备强大多任务理解能力的语音大语言模型,本文以泰语为研究对象,提出一套完整解决方案,主要包含XLSR-Thai 语音编码器、U-Align 通用语音 – 文本对齐方法与Thai-SUP 数据生成流水线三部分,分别解决编码器表达能力不足、语音 – 文本对齐效率低、口语理解数据稀缺三大核心问题。
XLSR-Thai
现有面向 ASR 训练的语音编码器多以语义信息为主,难以满足多任务理解所需的语言及副语言特征。为此,我们提出首个面向泰语的自监督学习语音编码器 XLSR-Thai。原始 XLSR 模型虽经过多语言预训练,但泰语数据仅几十小时,对泰语特性建模不足。为提升其在泰语上的表征能力,我们基于16,000 小时开源泰语语音 + 20,000 小时内部无标注泰语语音,对 XLSR 进行持续预训练,得到 XLSR-Thai。经过大规模预训练,XLSR-Thai 能够同时捕获泰语的语言结构与关键副语言线索,为后续多任务理解提供更鲁棒、泛化性更强的语音表征。
U-Align
我们以 XLSR-Thai作为语音编码器,使用 LayerNorm、CNN 下采样器与 MLP 投影层构成模态适配器,将语音特征映射到文本嵌入空间。LLM 解码器采用冻结的 Typhoon2-LLaMa2-3B[7] 模型,在任务提示与适配后语音特征的条件下生成文本输出。传统基于 ASR 的对齐方法需要微调整个 SLLM 以优化 ASR 目标,计算成本高且仅针对 ASR 任务优化。为此,我们提出 U-Align,直接在 LLM 嵌入空间中将适配后的语音表征与对应转录文本的表征对齐,使语音输入更接近文本嵌入,让 LLM 能更自然地理解语音。为解决语音与文本长度不匹配问题,我们使用基于余弦距离的 DTW 损失进行对齐。
U-Align 分为两阶段:
- 阶段一:不参与 LLM,仅使用 DTW 损失训练适配器完成语音 – 文本对齐,大幅降低计算开销;
- 阶段二:固定 LLM,接入任务提示与语音嵌入,在口语理解数据上微调以支持多任务。


阶段1:使用 DTW-loss 将适配后的语音表征与转录文本的嵌入表征进行对齐,此过程无需LLM的参与。
阶段2:使用阶段1训练好的适配器进行初始化,并利用特定任务的提示词和语音表征作为输入,引导冻结的 LLM 运行。与之对比,基于 ASR 的对齐方法在整个 SLLM 中,仅针对 ASR 任务来优化适配器。
Thai-SUP
为解决低资源语言口语理解数据极度稀缺的问题[3,4],我们设计了 Thai-SUP流水线,将高资源语言的文本理解数据迁移为低资源语言的口语理解监督数据。
流程如图 2 所示:
- 采集高资源文本理解数据(如英文 IC、NER 公开数据集);
- 使用 LLM 进行数据增强,丰富句式与表达;
- 将增强后文本翻译为目标低资源语言(泰语),并做口语化与质量过滤;
- 通过TTS语音合成生成语音,构建大规模语音 – 文本对。
在泰语上具体实现:
- 从英文 SNIPS、WikiANN、CONLL-2023 等数据集出发;
- 使用 DeepSeek-v3 做数据增强,Gemini-2.5-flash 做质量筛选;
- 翻译为泰语口语化文本,再通过泰语 TTS 模型 LLaSa 合成语音;
- 语音改写(SR)任务则从 ASR 语料中筛选可改写样本,由 LLM 生成改写标签。
最终构建出超过 1073 小时的泰语口语理解数据集:
- SR 任务:250 小时
- NER 任务:648 小时
- IC 任务:175 小时
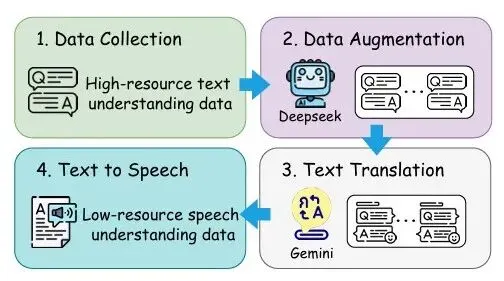
Thai-SUP 利用基于 LLM 的数据增强、翻译和 TTS 技术,从高资源英语文本语料库中生成低资源泰语口语理解数据。
实验结果
实验设置
我们在16,000 小时公开泰语数据(包括 GigaSpeech2 [5] 和 MSR-86K [6])以及20,000 小时内部无标注泰语数据上对 XLSR 进行持续预训练,得到 XLSR-Thai。为验证编码器的效果,我们分别使用 XLSR-Thai 与原始 XLSR 在 GigaSpeech2、MSR-86K 和 Common Voice 数据集上进行 ASR 微调,并以字符错误率(CER)作为评价指标。
为验证 U-Align 的有效性与效率,我们在相同模型设置与相同数据集上,将其与传统基于 ASR 的对齐方法进行对比。在多任务训练中,我们先从 GigaSpeech2、MSR-86K 和 Common Voice 中抽取2,000 小时数据用于 U-Align 的对齐阶段,再加入 Thai-SUP 数据集进行多任务微调,以实现多任务理解能力。
评价指标如下:
- ASR 任务:字符错误率(CER)
- NER 和 IC 任务:分类准确率(ACC)
- SR 任务:由 Gemini-2.5-Flash 计算的 1–5 分自动评分
XLSR-Thai编码器有效性验证
为验证 XLSR‑Thai编码器的优越性,我们分别在ASR 单任务和多任务理解上开展实验。在 ASR 单任务中,我们采用两种方式对自监督编码器进行微调:
- CTC方式:自监督编码器与 CTC 层全部微调;
- AED方式:冻结自监督编码器,将其作为 Conformer 编码器 + Transformer 解码器 AED 模型的特征提取器。
此外,我们使用相同数据训练了同等规模的 AED 模型 Conformer‑giga2 作为对比。
如表格 1 所示,在两种微调方式下,XLSR‑Thai 均优于原始 XLSR 模型。同时,与 Conformer‑giga2 相比,XLSR‑Thai‑AED 取得显著提升,表明本文自监督模型能学习到更优质的语音表征。此外,与开源的 Monsoon‑Whisper‑Medium‑GigaSpeech2 相比,XLSR‑Thai 同样展现出更强的性能潜力。
在多任务理解任务中(表格 2),无论是基于 ASR 对齐还是 U‑Align 对齐,使用 XLSR‑Thai 作为编码器的效果均稳定优于 Whisper。这说明,在构建语音大语言模型时,XLSR‑Thai 能更有效地支撑多任务理解。

U-Align 多任务语音理解的性能
为验证U-Align方法可实现多任务有效的通用语音-文本对齐,我们开展了多任务理解实验,并设计了以下实验方案:
- XLSR-Thai+基于ASR的对齐:首先利用2000小时的ASR数据,通过基于ASR的对齐方法训练模态对齐1个轮次(epoch),然后加入1个轮次的Thai-SUP多任务训练,采用XLSR-Thai作为语音编码器。
- XLSR-Thai+直接多任务训练(Directly-MT):不设置单独的对齐阶段,直接在ASR数据与Thai-SUP数据的组合数据集上训练多任务能力,共训练2个轮次。
- XLSR-Thai+U-Align:采用我们提出的两阶段方法,先通过U-Align训练1个轮次的对齐,再加入Thai-SUP进行多任务理解训练。
- XLSR-Thai+U-Align(CTC):将对齐阶段的DTW损失替换为CTC损失。
- Whisper+基于ASR的对齐:将XLSR-Thai+基于ASR的对齐方案中的编码器替换为monsoon-Whisper-medium-GigaSpeech2。
- Whisper+U-Align:采用monsoon-Whisper-medium-GigaSpeech2作为编码器,并应用U-Align方法进行训练。
评估指标:意图分类 (IC) 采用准确率 (ACC, %) ↑;命名实体识别 (NER) 采用准确率 (ACC, %) ↑(其中 NER-ALL 为总体,NER-PER 为人名,NER-ORG 为组织机构,NER-LOC 为地理位置,NER-OTH 为其他实体类型);语音响应 (SR) 采用 LLM 评分 (1-5) ↑;语音识别 (ASR) 采用字符错误率 (CER, %) ↓。
实验结果如表2所示。对比XLSR-Thai+基于ASR的对齐、XLSR-Thai+直接多任务训练(Directly-MT)与XLSR-Thai+U-Align三种方案可以发现,在多任务理解训练前进行语音-文本对齐,其性能优于直接进行多任务理解训练。此外,U-Align方法的效果优于基于ASR的对齐方法,这表明该方法可实现更通用、更具多任务有效性的对齐。Whisper+基于ASR的对齐与Whisper+U-Align的对比结果也表明,U-Align在不同编码器上均能持续提升对齐效果,验证了我们方法的鲁棒性。

U-Align在ASR任务上的有效性和高效性
为验证U-Align在自动语音识别(ASR)任务上的有效性与高效性,我们设计了对比实验。基线模型采用基于ASR的对齐方法,在ASR数据上训练语音大语言模型(SLLM);而我们的方法则分两个阶段使用相同的数据:第一阶段通过U-Align学习模态对齐,第二阶段在ASR任务上进行微调。
我们通过对比模型在相同计算成本下取得的性能来衡量有效性,通过对比模型达到相同性能所需的计算成本来衡量高效性。图3所示的实验结果表明,U-Align的(计算成本)始终低于基于ASR的对齐方法,这说明与基于ASR的对齐方法相比,U-Align兼具更高的高效性与有效性。

参考文献
[1] Chu, Yunfei and Xu, Jin and Yang, Qian and Wei, Haojie and Wei, Xipin and Guo, Zhifang and Leng, Yichong and Lv, Yuanjun and He, Jinzheng and Lin, Junyang and others, “Qwen2-audio technical report,” arXiv preprint arXiv:2407.10759, 2024.
[2] A. Seth, S. Ghosh, S. Umesh, and D. Manocha, “Stable Distilla-tion: Regularizing Continued Pre-Training for Low-Resource Automatic Speech Recognition,” in Proc. ICASSP, 2024, pp. 10 821–10 825.
[3] R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Henretty, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common Voice: A Massively-Multilingual Speech Corpus,” in Proc.LREC, 2020, pp. 4218–4222.
[4] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,”in Proc. ICASSP 2015, pp. 5206–5210.
[5] Y. Yang, Z. Song, J. Zhuo, M. Cui, J. Li, B. Yang, Y. Du, Z. Ma,X. Liu, Z. Wang et al., “GigaSpeech 2: An Evolving, Large-Scale and Multi-domain ASR Corpus for Low-Resource Languages with Automated Crawling, Transcription and Refinement,”arXiv preprint arXiv:2406.11546, 2024.
[6] S. Li, Y. You, X. Wang, Z. Tian, K. Ding, and G. Wan, “MSR-86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research,” arXiv preprint arXiv:2406.18301, 2024.
[7] K. Pipatanakul, P. Manakul, N. Nitarach, W. Sirichotedumrong, S. Nonesung, T. Jaknamon, P. Pengpun, P. Taveekitworachai, A. Na-Thalang, S. Sripaisarnmongkol et al., “Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models,”arXiv preprint arXiv:2412.13702, 2024.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。