
1 背景
近期,GPT大模型的发布给自然语言处理(NLP)领域带来了令人震撼的体验。随着这一事件的发生,一系列开源大模型也迅速崛起。依据一些评估机构的评估,这些开源模型大模型的表现也相当不错。一些大模型的评测情况可以去这里查询:Huggingface的Open LLM排行榜,UC伯克利发布大语言模型排行榜等。
随着大模型的发展,大模型的训练与部署技术变的非常重要了。我们调研了LORA与QLORA等微调训练技术,以及GPTQ量化部署技术。在跑通最小Demo并验证效果后,把这些技术集成到KubeAI平台(得物AI平台),提供给大家去快速上手。
本篇主要分为技术理论与技术实战两个部分去讲解。
技术理论主要讲解微调训练与量化推理的理论部分,微调训练包括LoRA,QLoRA, 部署包括GPTQ量化推理等,并针对关键代码进行走读,针对部署进行性能测试。
技术实战部分我们把这些技术集成到KubeAI平台上,供大家可以快速上手实战。依据前面同学的反馈情况,大约一天内可以完成大模型训练并部署推理上线。
2 LoRA与QLoRA训练技术
2.1 LoRA技术介绍
对于大语音模型来说,其参数量非常多。GPT3有1750亿参数,而且LLAMA系列模型包括 7B,13B,33B,65B,而其中最小的7B都有70亿参数。要让这些模型去适应特定的业务场景,需要对他们进行微调。如果直接对这些模型进行微调,由于参数量巨大,需要的GPU成本就会非常高。LoRA就是用来解决对这些大语言模型进行低成本微调的技术。
LoRA的做法是对这些预训练好的大模型参数进行冻结,也就是在微调训练的时候,这些模型的参数设置为不可训练。然后往模型中加入额外的网络层,并只训练这些新增的网络层参数。这样可训练的参数就会变的非常少,可以以低成本的GPU微调大语言模型。
下面以Transformer的线性层为例,讲解下LoRA具体是如何操作的。
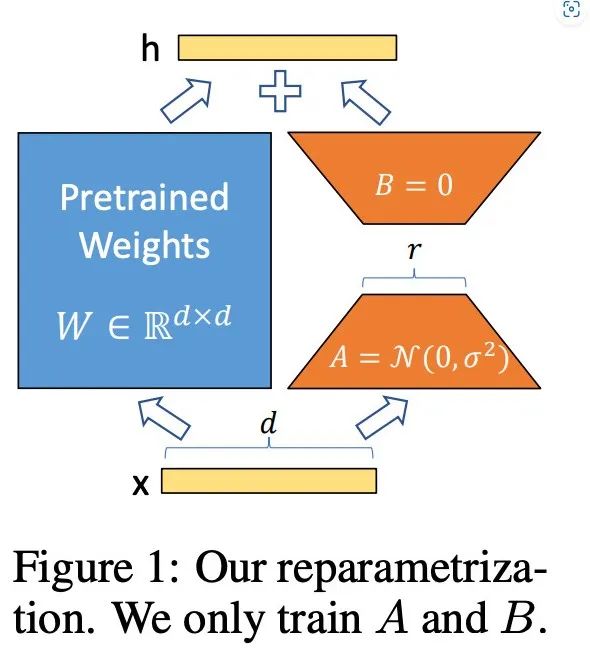

在Transformer模型中的线性层,通常进行矩阵乘法操作,如Y = XW,其中X是输入矩阵,W是权重矩阵,也是模型训练求解的参数。
对于LoRA方法在Transformer的线性层中的操作步骤:
|
2.2 LoRA关键代码走读
上面讲解了LoRA的关键,接下来我们针对最新的版本PEFT中的LoRA实现,进行关键代码走读。LoRA的核心代码逻辑在:https://github.com/huggingface/peft/blob/main/src/peft/tuners/lora.py
其中有两个核心的类,一个是LoraConfig,另一个是LoraModel。

LoraConfig是LoRA的核心配置类,它是用于配置LoRAModel的类,其中包含了一些用于控制模型行为的参数。
这个类的主要参数有:
|
2.2.1 初始化函数

2.2.2 初始化:使用新的LoraLayer替换target_modules中配置的Layer,实现上面所说的添加旁路低秩矩阵的功能。
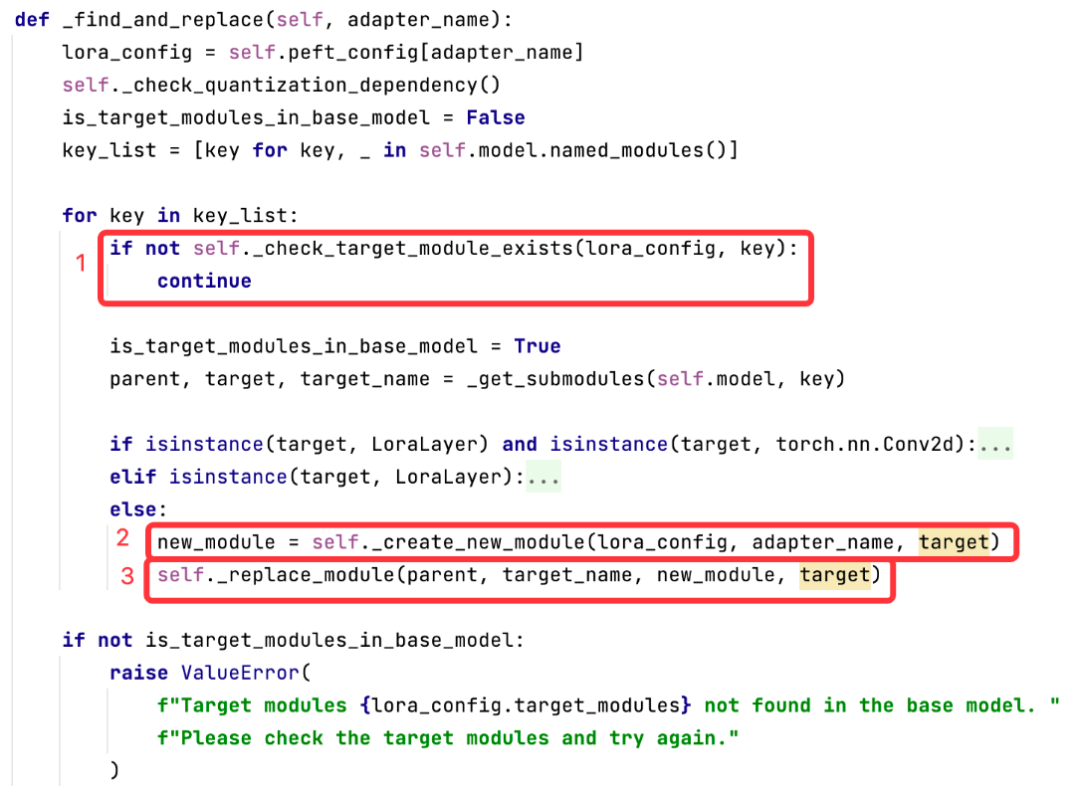
上述代码的主要功能:
|
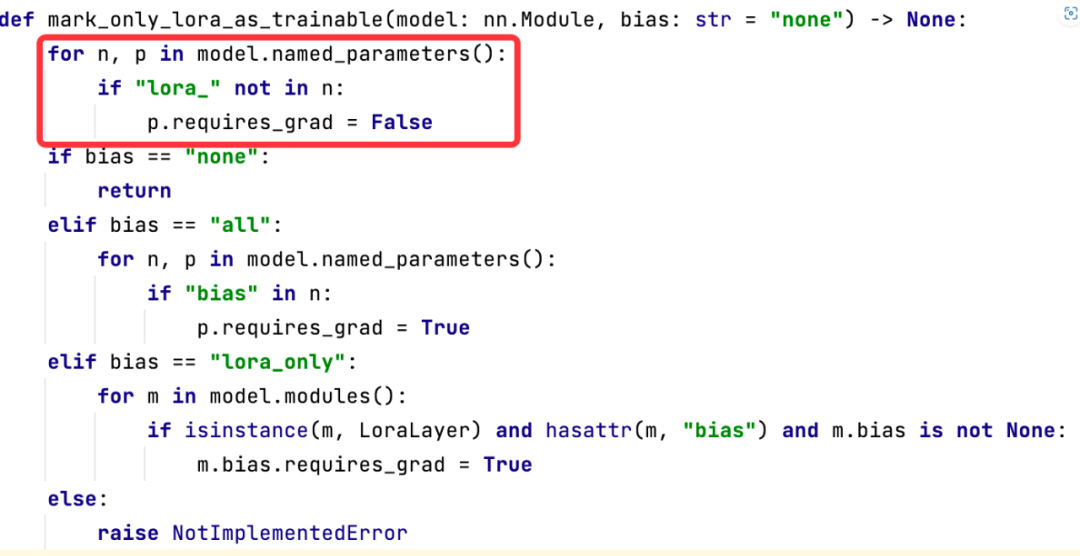
2.2.3 初始化:冻结大模型的参数
2.2.4 前向传播:添加了旁路低秩矩阵后的运算逻辑(以LineLayer为例)
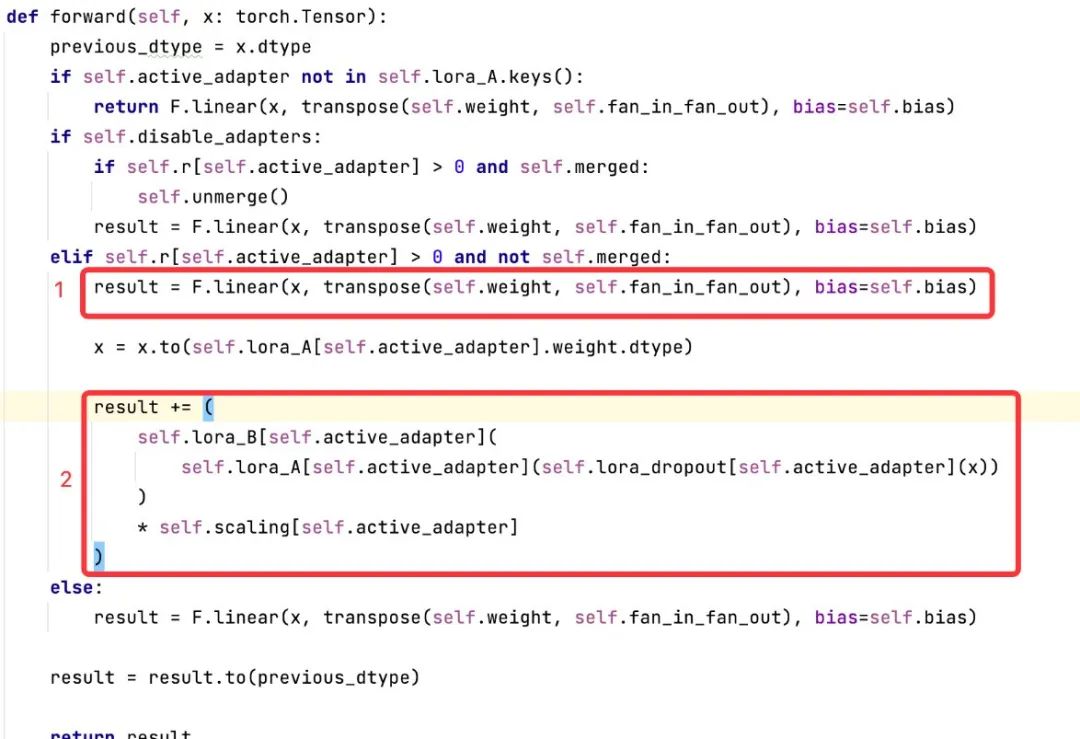
在上述代码中:
|
以上是主要逻辑,其他逻辑可以深入代码去了解。PEFT库中Lora的实现与论文中所述一致。
2.3 QLORA技术介绍
LoRA技术虽然可以在一定程度上节省显存,提升训练速度,但是把大模型以float16的方式运行,还是会占用很多显存。比如:在batch size开到极小的情况下,单卡A100(80G显存)只能微调7B系列的模型,13B模型在正常情况下需要120G显存,微调65B模型需要超过780G的显存。
为此华盛顿大学的研究者提出了QLoRA技术,极端情况下单个24GB GPU上实现33B的微调,可以在单个48Gi显存微调65B模型。当然这种情况下微调会变得比较慢
论文参考 https://arxiv.org/abs/2305.14314。
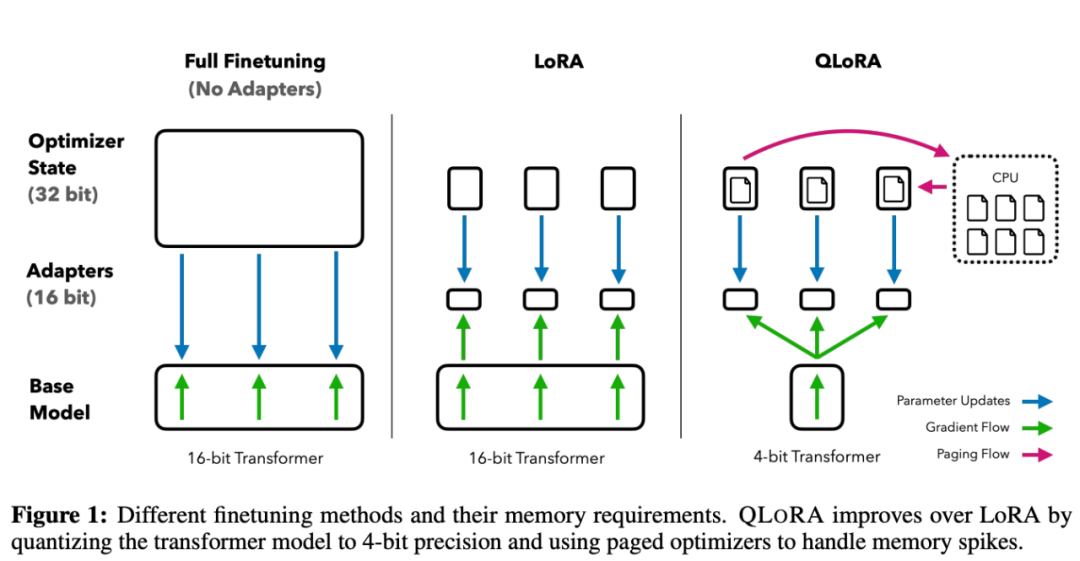
上图中描述了LoRA与QLoRA在微调训练的时候的区别,从QLoRA的名字可以看出,QLoRA实际上是Quantize+LoRA技术,简单的说就是把大模型(Base Model)在训练的时候从16bit压缩到4bit。从而降低训练的显存。
|
在我们的平台经过实测,训练33B的模型最低需要26G显存。但是需要把batch-szie设置为1,这样训练速度会比较慢。在实际操作中可以再适当加大batch size的值,配合4bit量化,就可以在少量GPU资源情况下训练33B大模型了,当然13B的大模型使用QLORA同样效果不错。
目前最新版本的PEFT库也添加了对QLoRA的支持,喜欢代码的同学可以去深入了解下。
3 量化推理介绍
3.1 GPTQ量化介绍
所谓后训练量化是指在模型训练完成之后进行量化,模型的权重会从32位浮点数(或其他较高精度格式)转换为较低精度格式,例如4位整数。这种转换大大减小了模型的大小,并减少了运行模型所需的计算量。但是,这也可能会导致一定程度的精度损失。
3.2 GPTQ量化数据对比
我们通过对13B的模型进行4bit量化测试,发现经过GPTQ量化后的对比如下:

4 实战:kubeai平台大模型训练与推理
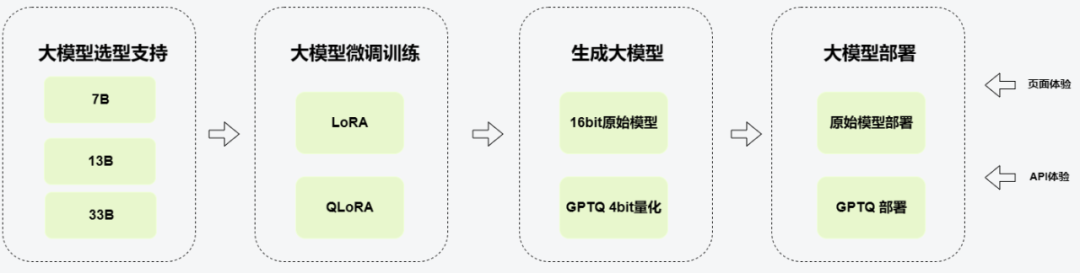
前面我们介绍了大模型的训练技术:LoRA与QLoRA的工作原理,介绍了通过GPTQ量化部署的步骤。我们把这些步骤集成在KubeAI的训练推理平台中,供大家研究,并同时提供7B,13B,33B大模型备选。KubeAI中选择GPT服务/定制版(Finetune)即可体验。
4.1 kubeAI平台的训练与推理工作流程
|

|
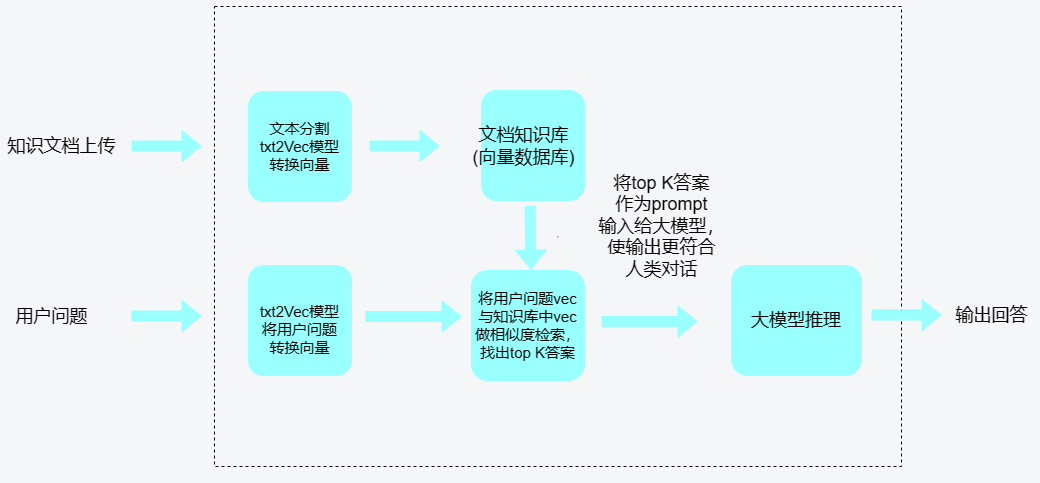
4.3 kubeAI平台基于知识库的推理功能
|
5 总结
我们调研了大模型的微调训练方法LoRA与QLoRA,以及大模型的推理部署GPTQ量化部署。把上面的微调训练到推理部署的整个链路集成到kubeAI平台上,提供给大家快速实验。此外还集成了以文档形式上传到知识库,配合知识库进行推理的场景。
大模型的训练与推理方法除了以上所提LORA、QLORA、GPTQ外,还有其他技术。因为大模型社区比较火爆,后面肯定会有更优的微调训练与量化部署技术。后续我们会持续跟踪,如果在效果与性能上优于当前支持的方法,平台也将及时基于目前的框架继续集成这些新的方法。
作者:linggong
来源:得物技术
原文:https://mp.weixin.qq.com/s/5EE1VXxq7k_VoC9gRPvyM
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。