
对象定位是指精确识别和定位图像中感兴趣的对象的任务。它在计算机视觉应用中发挥着至关重要的作用,可实现对象检测、跟踪和分割等任务。在基于 CNN 的定位器中,对象定位涉及训练卷积神经网络来预测包围对象的边界框的坐标。
定位过程通常遵循两步流程,其中主干 CNN 提取图像特征,回归头预测边界框坐标。
学习目标
- 了解卷积神经网络 (CNN) 的基础知识。
- 解释本地化模型的 CNN 架构。
- 使用预先训练的 CNN 模型进行定位来实现定位器架构。
卷积神经网络 (CNN)
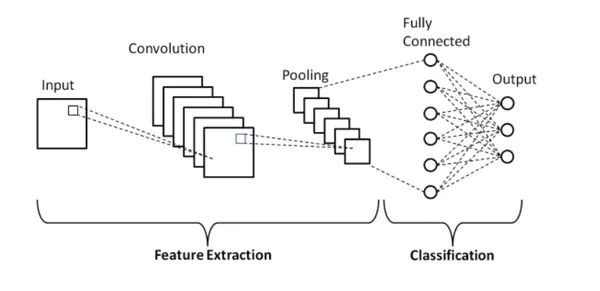

卷积神经网络 (CNN) 是一类用于图像分析的深度学习模型。
它们的架构包括一个接收图像数据的输入层,后面是使用卷积滤波器学习和提取特征的卷积层。激活函数引入了非线性,而池化层则减少了空间维度。最后的全连接层做出最终预测。
CNN 学习分层特征,从边缘等低级特征开始,逐渐发展到形状和对象组合等复杂和抽象的特征。
在CNN 的训练阶段,网络学习自动识别和提取不同级别的特征。初始层捕获低级特征,例如边缘、角和纹理,而更深的层学习更复杂和抽象的特征,例如形状、对象部分和对象组合。CNN 的层次结构使其能够学习对平移、缩放、旋转和其他图像变换的变化越来越不敏感的表示。
“越来越不敏感的表示”意味着随着CNN网络的深层学习,所学习到的特征表示对于图像变换变得越来越稳定和不变,能够在面对这些变换时保持对重要特征的有效提取和识别能力。
基于 CNN 的定位器架构
用于目标定位的基于 CNN 的定位器模型由 3 个组件组成:
1. CNN骨干网
结合 SQL 的力量:选择标准 CNN 架构(例如 ResNet 18、ResNet 50、VGG 等)来微调 Imagenet 分类任务上的预训练模型。使用额外的 CNN 层增强主干网络以减小特征图尺寸
2. 矢量化器
CNN 主干的输出是 3D 张量。但定位器的最终输出是一个一维向量,其中四个值对应于边界框的每个坐标。为了将 3D 张量转换为向量,我们使用向量化器或利用 Flatten 层作为替代方法。
3. 回归头
我们专门为此任务构建了一个完全连接的回归头。之后,从主干网络获得的特征向量被馈送到回归头。回归头由末端的 4 个节点组成,对应于 (x1, y1, x2, y2) 或任何其他等效的边界框表示。
更好地理解模型架构
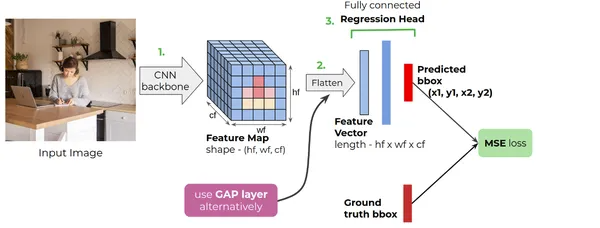
该图显示了常见的基于 CNN 的定位器模型架构。简而言之,CNN 主干接收 RGB 图像,然后生成特征图。然后,我们使用展平层或全局平均池层来形成一维特征向量。全连接回归头接收特征向量并给出预测。
CNN 网络保持输入图像的固定大小,我们使用 Flatten 层将从 CNN 主干获取的特征图转换为向量。然而,当使用 GAP(全局平均池)等自适应层时,不需要调整图像大小。
训练定位器
导入必要的库
import ast
import math
import os
import cv2
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from functools import partial
from tensorflow.data import Dataset
from tensorflow.keras.applications import ResNet50
from tensorflow.keras import layers, losses, models, optimizers, utils 构建组件
该架构采用尺寸为 300×300、具有 3 个颜色通道的输入图像。
- 主干处理图像并提取高级特征。
- 然后,矢量化器计算这些特征的固定长度矢量表示。
- 最后,回归头获取该向量并执行回归,输出 4 维向量作为最终预测。
IMG_SHAPE = (300, 300)
backbone = models.Sequential([
ResNet50(include_top=False,
weights='imagenet',
input_shape=IMG_SHAPE + (3,)),
layers.Conv2D(1024, 3, 2, activation='relu'),
], name='backbone' )
vectorizer = layers.GlobalAveragePooling2D(name='GAP_vectorizer')
regression_head = models.Sequential([
layers.Dense(512, activation='relu'),
layers.Dense(4)
], name='regression_head')建立模型
它通过组合先前定义的组件来定义完整的模型:主干、矢量化器和回归头。
bbox_regressor = models.Sequential([
backbone,
vectorizer,
regression_head
])
bbox_regressor.summary()
utils.plot_model(bbox_regressor, "localizer.png", show_shapes=True)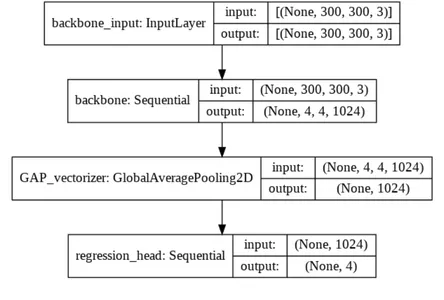
下载数据集
我们正在使用自拍数据集。Selfie 数据集包含 46,836 张自拍图像。我们使用 Haar Cascades 生成面部边界框。提供了一个 CSV 文件,其中包含大约 22K 图像的图像路径和边界框坐标。
该数据集可在以下位置获取:
https://www.crcv.ucf.edu/data/Selfie/Selfie-dataset.tar.gz
生成数据批次
DataGenerator 类负责加载和预处理本地化任务的现有数据。
- 它采用图像目录和带有图像路径和边界框信息的 CSV 文件作为输入。
- 该类根据提供的分数将数据划分为训练和测试子集。
- 在生成过程中,该类通过调整图像大小、转换颜色通道和标准化像素值来预处理每个图像。
- 边界框坐标也正常。
生成器为每个数据样本生成预处理图像和相应的边界框。
class DataGenerator(object):
def __init__(self, img_dir, _csv_path, train_max=0.8, test_min=0.9, target_shape=(300, 300)):
for k, v in locals().items():
if k != "self" and not k.startswith("_"):
setattr(self, k, v)
self.df = pd.read_csv(_csv_path)
def __len__(self):
return len(self.df)
def generate(self, phase):
assert phase in [None, 'train', 'test']
_df = self.divide_data(phase)
for rel_img_path, bbox in _df.values:
img, bbox = self.preprocess_data(rel_img_path, bbox)
img = tf.constant(img, dtype=tf.float32)
bbox = tf.constant(bbox, dtype=tf.float32)
yield img, bbox
def preprocess_data(self, rel_img_path, bbox):
bbox = np.array(ast.literal_eval(bbox))
img_path = os.path.join(self.img_dir, rel_img_path)
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
_h, _w, _ = img.shape
img = cv2.resize(img, self.target_shape)
img = img.astype(np.float32) / 127.0 - 1
bbox = bbox / np.array([_w, _h, _w, _h])
return img, bbox # np.expand_dims(bbox, 0)
def divide_data(self, phase):
train_max = int(self.train_max * len(self.df))
_df = None
if phase is None:
_df = self.df
elif phase == 'train':
_df = self.df.iloc[:train_max, :].sample(frac=1)
else:
_df = self.df.iloc[train_max:, :]
return _df 加载和创建数据集
这使用 DataGenerator 类通过 TensorFlow 的数据集 API 创建训练和测试数据集。
- 它使用 TensorFlow 的数据集 API 创建训练和测试数据集。
- 我们通过调用 DataGenerator 实例的“generate”方法来生成训练数据集,并指定“train”阶段。
- 使用“test”阶段生成测试数据集。
- 两个数据集均经过混洗和批处理,批量大小为 16。
生成的 train_dataset 和 test_dataset 是 TensorFlow Dataset 对象,准备好进一步处理或训练模型。
IMG_DIR = 'Selfie-dataset/images'
CSV_PATH = '3-lv1-8-4-selfies_dataset.csv'
BATCH_SIZE = 16
dataset_generator = DataGenerator(IMG_DIR, CSV_PATH)
train_max = int(len(dataset_generator) * 0.9)
train_dataset = Dataset.from_generator(partial(dataset_generator.generate,
phase='train'), output_types=(tf.float32, tf.float32),
output_shapes = (IMG_SHAPE + (3,), (4,)))
train_dataset = train_dataset.shuffle(buffer_size=2 * BATCH_SIZE).batch(BATCH_SIZE)
test_dataset = Dataset.from_generator(partial(dataset_generator.generate,
phase='test'),output_types=(tf.float32, tf.float32),
output_shapes = (IMG_SHAPE + (3,), (4,)))
test_dataset = test_dataset.shuffle(buffer_size=2 * BATCH_SIZE).batch(BATCH_SIZE)损失函数和性能指标
多个回归损失函数可用于训练边界框定位器。MSE 和 Smooth L1 等回归损失函数的使用方式与其他回归任务的情况类似,并应用于地面实况边界框向量和预测边界框向量之间。
并交交集 (IoU) 是边界框回归中常用的性能指标。
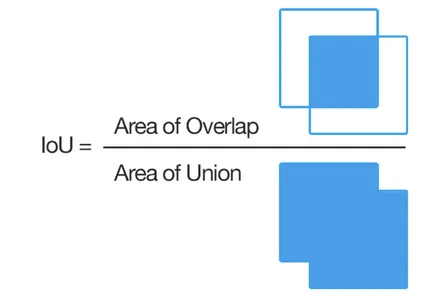
该函数定义了一组函数,用于计算并交交集 (IoU) 并评估模型预测的性能。它提供了计算 IoU、根据损失和 IoU 评估预测以及将评估标准分配给变量的方法。
def cal_IoU(b1, b2):
zero = tf.convert_to_tensor(0., b1.dtype)
b1_x1, b1_y1, b1_x2, b1_y2 = tf.unstack(b1, 4, axis=-1)
b2_x1, b2_y1, b2_x2, b2_y2 = tf.unstack(b2, 4, axis=-1)
b1_width = tf.maximum(zero, b1_x2 - b1_x1)
b1_height = tf.maximum(zero, b1_y2 - b1_y1)
b2_width = tf.maximum(zero, b2_x2 - b2_x1)
b2_height = tf.maximum(zero, b2_y2 - b2_y1)
b1_area = b1_width * b1_height
b2_area = b2_width * b2_height
intersect_x1 = tf.maximum(b1_x1, b2_x1)
intersect_y1 = tf.maximum(b1_y1, b2_y1)
intersect_y2 = tf.minimum(b1_y2, b2_y2)
intersect_x2 = tf.minimum(b1_x2, b2_x2)
intersect_width = tf.maximum(zero, intersect_x2 - intersect_x1)
intersect_height = tf.maximum(zero, intersect_y2 - intersect_y1)
intersect_area = intersect_width * intersect_height
union_area = b1_area + b2_area - intersect_area
iou = tf.math.divide_no_nan(intersect_area, union_area)
return iou
def calculate_iou(y_true, y_pred):
y_pred = tf.convert_to_tensor(y_pred)
y_pred = tf.cast(y_pred, tf.float32)
y_true = tf.cast(y_true, y_pred.dtype)
iou = cal_IoU(y_pred, y_true)
return iou
def evaluate(actual, pred):
iou = calculate_iou(actual, pred)
loss = losses.MSE(actual, pred)
return loss, iou
criteron = evaluate优化器和学习率调度器
我们使用指数衰减学习率来调度学习率,并使用 Adam 优化器来进行优化。
zEPOCHS = 10
LEARNING_RATE = 0.0003
lr_scheduler = optimizers.schedules.ExponentialDecay(LEARNING_RATE, 3600, 0.8)
optimizer = optimizers.Adam(learning_rate=lr_scheduler)
os.makedirs('checkpoints', exist_ok=True)训练循环
它实现了一个运行指定次数的训练循环。
- 在每个时期内,循环都会迭代训练数据集的批次。
- 它执行前向传播以获得预测的边界框坐标,计算损失和 IoU 值,应用反向传播来更新模型的权重,并记录训练指标。
- 每个时期之后,计算平均训练损失和 IoU。
该模型在每个时期结束时保存。
for epoch in range(EPOCHS):
train_losses, train_ious = np.array([]), np.array([])
for step, (inputs, labels) in enumerate(train_dataset):
with tf.GradientTape() as tape:
preds = bbox_regressor(inputs, training=True)
loss, iou = criteron(labels, preds)
grads = tape.gradient(loss, bbox_regressor.trainable_weights)
optimizer.apply_gradients(zip(grads, bbox_regressor.trainable_weights))
loss_value = tf.math.reduce_mean(loss).numpy()
train_losses = np.hstack([train_losses, loss_value])
iou_value = tf.math.reduce_mean(iou).numpy()
train_ious = np.hstack([train_ious, iou_value])
print('Training Loss : %f'%(step + 1, math.ceil(train_max / BATCH_SIZE),
loss_value), end='')
tr_lss, tr_iou = np.mean(train_losses), np.mean(train_ious)
print('Train loss : %f -- Train Average IOU : %f' % (epoch, EPOCHS,
tr_lss, tr_iou))
print()
save_path = './models/checkpoint%d.h5' % (epoch)
bbox_regressor.save(save_path)预测
我们通过在图像中绘制边界框来可视化 Bbox 回归器为测试集中的某些图像预测的边界框。
for inputs, labels in test_dataset:
bbox_preds = bbox_regressor(inputs, training=False).numpy()
bbox_preds = (bbox_preds * (dataset_generator.target_shape * 2)).astype(int)
imgs = (127 * (inputs + 1)).numpy().astype(np.uint8)
for idx, img in enumerate(imgs):
x1, y1, x2, y2 = bbox_preds[idx]
img = cv2.rectangle(img, (x1, y1), (x2, y2), (255, 0, 0), 4)
plt.imshow(img)
plt.show()
break输出

结论
总之,基于 CNN 的定位器有助于推进计算机视觉应用,特别是在对象定位任务中。该文章强调了 CNN 在图像分析中的重要性,并解释了两步流程,包括用于特征提取的骨干 CNN 和用于预测边界框坐标的回归头。
随着深度学习技术的进步、更大的数据集以及其他模式的集成,对象定位的未来拥有巨大的潜力,有望对行业产生重大影响并改变视觉感知和理解。
要点
- 基于 CNN 的定位器对于推进计算机视觉应用至关重要,它利用 CNN 从图像中学习分层特征的能力。
- 两步管道由特征提取主干 CNN 和回归头组成,通常用于基于 CNN 的定位器中,以实现准确的对象定位。
- 随着深度学习、更大数据集和其他模式集成的进步,对象定位的未来前景广阔,对自动驾驶、机器人、监控和医疗保健等行业产生重大影响。
作者:磐怼怼
来源:深度学习与计算机视觉
原文:https://mp.weixin.qq.com/s/mXRC0IIEkEAOjf9T8_7KTw
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。