
这篇文章主要介绍了一种名为D-NeRV的框架。该框架将每个视频解耦为特定的视觉内容和运动信息,并分别对其进行建模。此外,该框架引入了时间推理和任务导向流等技术,以更好地处理视频中的全局时间依赖性和空间冗余性。D-NeRV框架的引入旨在提高视频编码的效率和压缩结果。
来源:CVPR 2023
作者:Bo He等
论文题目:Towards Scalable Neural Representation for Diverse Videos
论文链接:https://arxiv.org/abs/2303.14124
内容整理:李竣韬
引言
隐式神经表征(INR)在各种信号的参数化方面取得了巨大的成功,如三维场景、图像、音频和视频。其关键思想是将信号表示为一个由神经网络近似表示的函数,将一个参考系数映射到其相应的信号值。与基于学习的视频压缩技术相比,基于INR的方法(如NeRV)更有利,因为其训练更简单,视频解码速度更快。虽然已经取到了很大进展,但是现有的基于INR的方法仅限于一次对单一短视频进行编码。这阻碍了大多数现实世界场景中的潜在应用,在这些场景中,我们需要表示和压缩大量不同的视频。对不同视频进行编码的一个直接策略是将它们分为多个子集,并通过一个简单的神经网络对其建模。然而,由于这种策略无法利用跨视频的长期冗余,与用一个单一的共享模型拟合所有不同的视频相比,它取得的结果较差。我们认为,目前视觉内容和运动信息的耦合设计夸大了记忆不同视频的难度。为了解决这个问题,我们提出了D-NeRV,一种新型的隐式神经表征,专门用于有效编码长的或大量不同的视频。图1显示了D-NeRV和NeRV之间的差异。当表示不同视频时,NeRV将每个视频编码到一个单独的模型中,或者简单地将多个视频串联成一个长视频进行编码,而我们的D-NeRV可以通过调节每个视频片段的关键帧在一个模型中表示不同的视频。
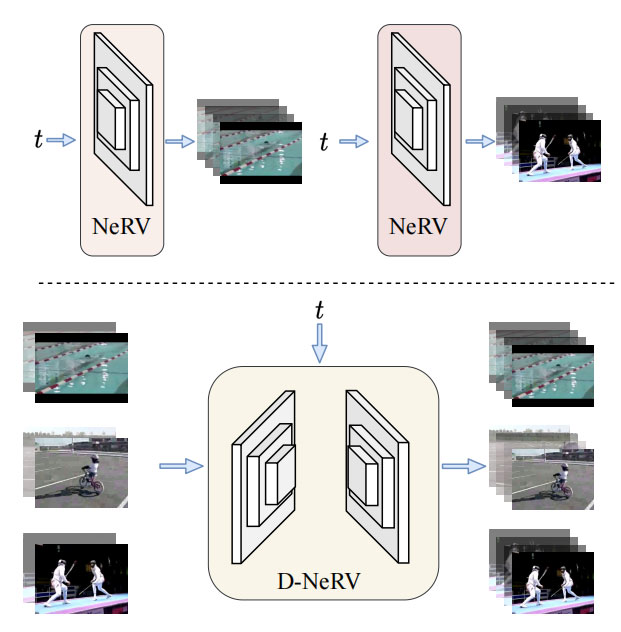

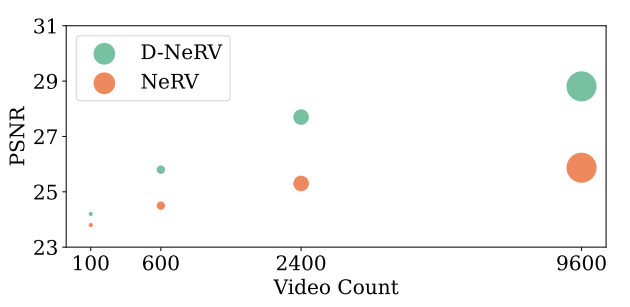
相对于NeRV,D-NeRV主要有以下改进。首先,我们观察到每个视频的视觉内容差异很大,而运动信息则可以再不同视频中共享。因此,我们将每个视频片段解耦为“视觉内容”和“运动信息”两部分,再分开单独建模。其次,我们在基于INR的网络中引入时间推理,而不是独立输出每一帧,明确地对不同帧的全局时间依赖性进行建模。最后,考虑不到视频中显著的时间冗余,我们不直接预测原始像素值,而是预测面向任务的流作为中间输出,并将其与关键帧一起使用以获得最终的输出。它减轻了记忆不同帧的相同像素值的复杂性。通过这些改进,在视频数量较多时,D-NeRV性能明显优于NeRV,如图2所示。
本文的主要贡献为:
- 提出了D-NeRV,一种新型的隐式神经表征模型,将大量不同的视频作为一个单一的神经网络来表示。
- 对视频重建和视频压缩任务进行了广泛的实验。D-NeRV一直由于最先进的基于INR的方法(E-NeRV)、传统的视频压缩方法(H.264、HEVC)以及基于学习的视频压缩方法(DCVC)。
- 进一步展示了D-NeRV在动作识别任务中的优势,即更高的准确率和更快的解码速度,并揭示了其在视频修复任务中的有趣特性。
方法
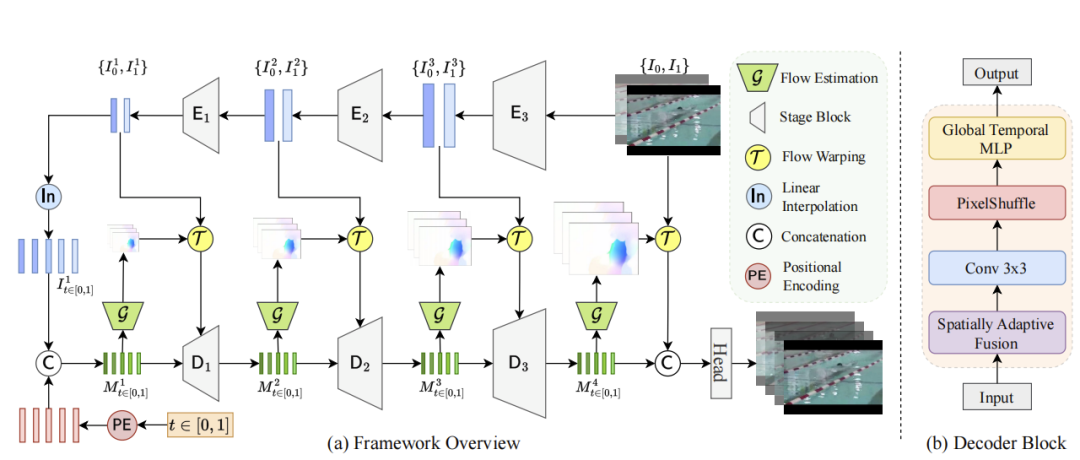
视觉内容编码器
不同的视频有不同的内容信息,例如,每个视频的外观和背景有很大的不同。D-NeRV的第一个组成部分是视觉内容编码器E,用来获取特定片段的视觉内容。与现有的仅通过模型本身记忆不同视频内容的工作相比,我们通过采样的关键帧向网络提供视觉内容。直观地说,我们把每个视频分成连续的片段。对于每个视频片段,我们对开始和结束的关键帧

运动感知解码器
虽然不同的视频有不同的外观或背景,但相同动作类型的视频可以共享类似的运动信息。我们通过一个基于共享隐式神经网络的解码器来模拟运动信息。通过关键帧的视觉内容,运动感知解码器提供运动信息来重建完整的视频。标准的隐式神经网络只接受坐标并输出相应的信号值,而我们的运动感知解码器同时接受时间坐标和内容特征图。然后,它预测面向任务的流作为中间输出,用于扭曲生成的内容特征。除此之外,提出空间自适应融合模块,将内容信息以更高效的方式融合到解码器。最后,将全局时态MLP模块加入解码器中。
多尺度流量估计

空间自适应融合

全局时态MLP

实验
与SOTA INRs的比较
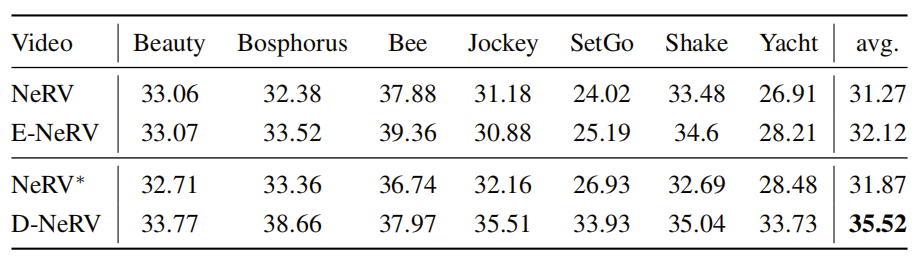
将D-NeRV与NeRV和E-NeRV在UVG数据集上的视频重建任务(不经过任何压缩步骤)进行比较。实验结果如表1所示,D-NeRV在UVG数据集的不同视频上的表现一直优于NeRV和E-NeRV。具体来说,在平均PSNR方面,D-NeRV比当下最先进的基于INR的方法E-NeRV高出3.4dB。
视频压缩
对于视频压缩,采用与NeRV相同的做法进行模型量化和熵编码,但没有模型修剪以加快训练过程。
UCF101数据集
实验结果如表2,观察到D-NeRV的性能大大超过NeRV。特别是当模型大小从小变大时,二者之间的差距也变得更大,从1.4dB增加到2.5dB。这表明D-NeRV比NeRV更有能力压缩高质量的大尺度视频。同时,我们可以用观察到D-NeRV一直超过了传统的视频压缩技术H.264,显示了其在现实世界大规模视频压缩中的巨大潜力。
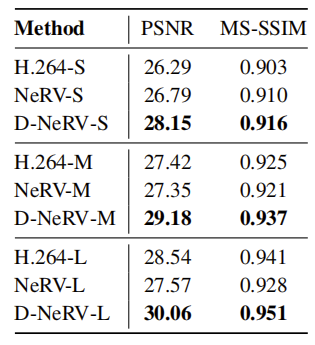
UVG数据集
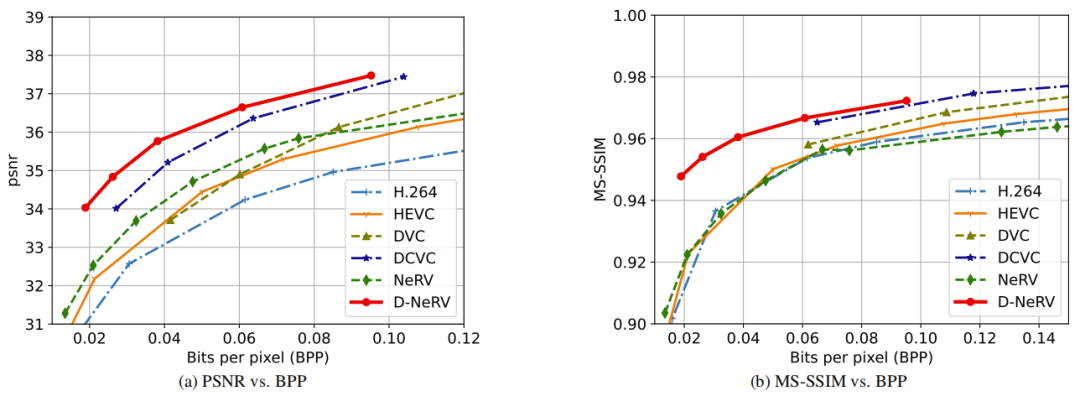
尽管D-NeRV是专门为表征大规模和多样化视频而设计的,而UVG数据集(7个视频)的情况并非如此,但它仍然可以持续地大大超越NeRV,如图4所示。具体来说,在相同BPP比率下,它超过NeRV 1.5dB以上。
消融
每部分组件的贡献
结果如表3,我们观察到带有空间自适应融合(SAF)的编码器可以在很大程度上提高NeRV的性能。其次,加入GTMLP模块可以进一步提供性能。特别地,如果仅添加全局时间MLP模块并不能促进最终结果。这是因为在表示多个视频时,NeRV沿时间轴将所有的视频连接起来。NeRV的输入是以串联视频的长度为标准的绝对时间指数,它不能反映相对帧之间的运动。相反,D-NeRV的输入是由每个视频的长度归一化的相对时间指数,它可以代表不同视频中共享的帧间运动。最后,为了进一步减少视频帧间固有的空间冗余,我们增加了面向任务的流作为中间输出,同样可以优化结果表现。
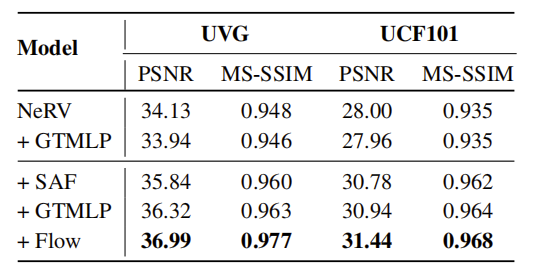
组件设计选择性消融
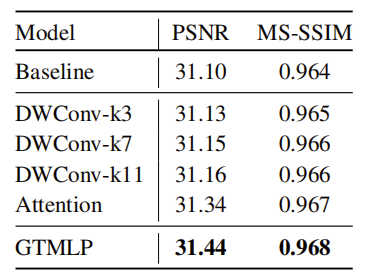
结果如表4,显示了不同时间建模设计的结果。与基础相比,通过增加深度时间卷积,纳入局部时间关系,可以略微提高性能,当内核大小从3增加到11时,差距变得更大,这验证了时间建模对有效的视频表示的重要性。受Trans-former的成功启发,我们引入时间注意力模块。与局部接收场的卷积操作不同,时间注意力模块可以对全局的时间依赖性进行建模,这比深度卷积的结果要高。然而,由于注意力操作的编译成本很高,注意力模块的训练速度比其他变体慢很多。最后,我们的GTMLP结合了全连接层的效率和注意力模块的全局时间建模能力,以更快的训练速度得到更好的结果。
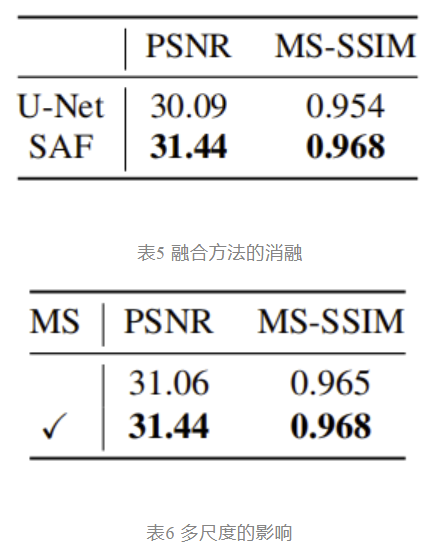
如表5所示,我们比较了不同的融合策略。U-Net将每个编码器阶段的输出特征图链接到解码器的输入,而提出的SAF模块利用内容特征图作为解码器特征的调制,这被证明是一个比简单连接更有效的设计。此外,如表6显示,多尺度设计可以提高最终的性能。
视频多样性的影响
我们设置如下实验:
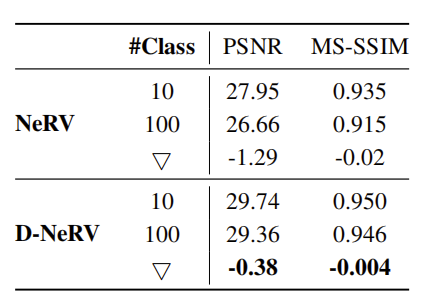
- 从10个类别中选出1000个视频,每个类别有100个视频;
- 从100个类别中选出1000个视频,每个类别有10个视频。结果如表7所示。当视频多样性从10类增加到100类时,虽然D-NeRV和NeRV的性能都有所下降,但D-NeRV的结果比NeRV下降得慢得多。这也验证了尤其是表征多样性视频时,D-NeRV更有效。
动作识别
动作识别精确度
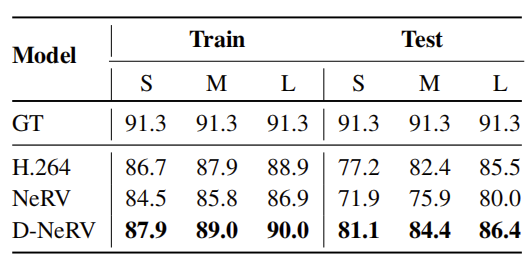
在实验中,我们采用广泛使用的TSM作为骨干,评估H.264、NeRV和D-NeRV的压缩视频的动作识别精度。S/M/L表示不同的BPP值,如表2。BPP值越低意味着压缩率越高。实验结果如表8所示,在“训练”和“测试”的两种设置下,D-NeRV的动作识别精确度始终比NeRV高出3-4%和6-10%。此外,D-NeRV的性能一直优于H.264。这证明了D-NeRV在现实世界中作为一个有效的数据传输器使用时的优越性。
模型运行时间
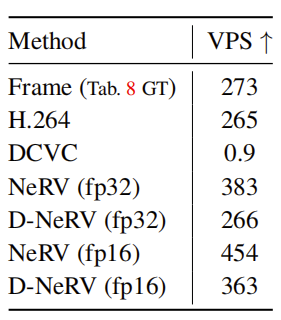
在表9中,我们比较了以下设置的模型运行时间:帧、H.264、DCVC、NeRV、D-NeRV。需要注意的是,尽管NeRV由于其结构的模拟性而具有最高的模型运行速度,但其压缩质量却远不如D-NeRV,如表2和表8所示。
视频修复
结果显示在表10中,为每一帧应用了5个宽度为50的随机盒式掩码。D-NeRV在PSNR上仍然比NeRV高出1.4dB。另外,有趣的是,在一个共享模型中对所有视频进行编码也可以提高画中画的性能,验证了之前所讲的,用一个共享模型对所有视频编码更有利。

高质量结果
在图5中,比较了压缩任务的解码帧的可视化结果。在相同BPP下,与H.264和NeRV相比,D-NeRV在主要物体和背景方面都能产生更清晰的图像,质量更高。图6显示了视频内修复任务的可视化结果。与NeRV相比,D-NeRV可以更自然地对遮罩区域进行填充,质量也更好。


版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。