
语音增强算法旨在提高带噪语音的感知质量和可理解性,它需要在不扭曲语音的情况下抑制背景噪声。
目前,深度学习方法在语音增强领域处于前沿。深度神经网络(DNNs)被用来将有噪声的语音幅度谱映射到干净的语音幅度谱,或者将有噪声的语音时域帧映射到干净的语音时域帧。
Deep Xi框架
Deep Xi是一种用于先验信噪比估计的深度学习方法。
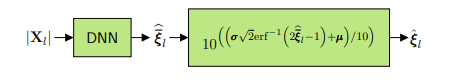

如上图所示。Deep Xi包括两个阶段
- 第一阶段,输入噪声语音幅度谱,经过DNN估计出映射先验信噪比。映射是指将先验信噪比映射到[0,1]区间,可以提高所使用的随机梯度下降算法的收敛速度。
- 第二阶段, 映射先验信噪比用于计算MMSE逼近增益函数,该函数与噪声语音幅度谱相乘,得到清晰的语音幅度谱估计。
MHANet
Deep Xi框架中的DNN可以选择多种网络,如RNN,TCN等。
multi-head attention (MHA)是一种机制,它在机器翻译等任务中比RNN和TCN的表现都要好。通过使用序列相似性,MHA能够更有效地建模长期依赖关系。MHANet的Deep Xi (Deep Xi-MHANet)可以利用多头注意对噪声语音的长期依赖性进行有效建模。
Deep Xi-MHANet如下图所示:
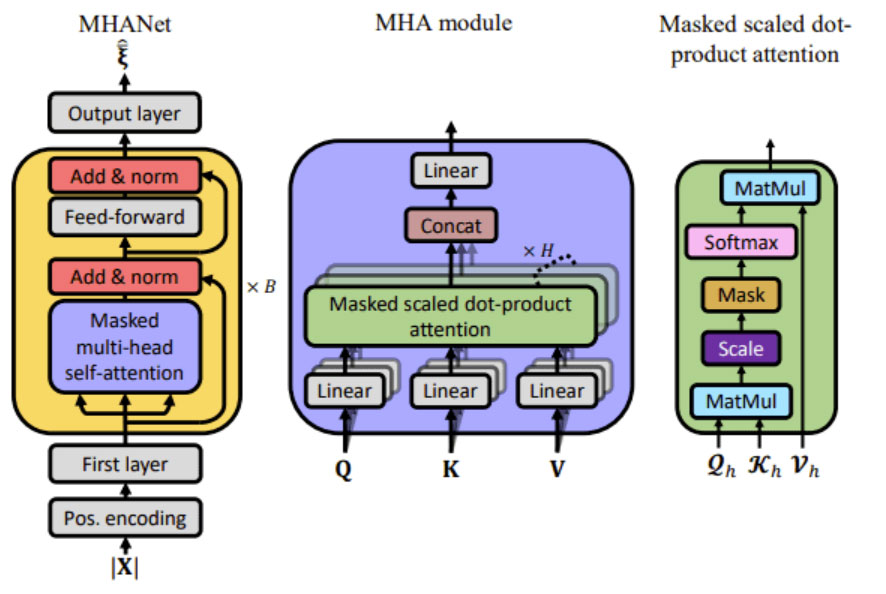
1. MHANet:输入噪声语音幅值谱|X|,添加位置编码用于获取序列中的顺序信息,First layer用于将输入投影到dmodel的大小,级联B个block后,输出层输出映射的先验信噪比。每个Block包括一个MHA模块,一个两层FNN,残差连接,以及帧方向的归一化。
2. MHA module:MHA module输入为一组帧长为L的请求(Q:queries)、键(K:keys)和值(V:values)。输出是values的加权求和,其中分配给每个values的权重是通过一个相关函数计算query与当前key的相关程度。每个MHA模块共使用H个Masked scaled dot-product attention,其中和h ={1,2,···,H}为Head索引。对于每个h,输入均为:
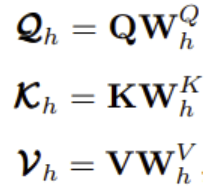
其中W为权重矩阵, Qh ,Kh 的大小为dk,Vh 的大小为dv。这允许不同的Head可以对不同的Qh,Kh , Vh进行操作,为了控制每个Head的输入向量大小,dk = dv = dmodel/H。
MHA的输出可以表示为:
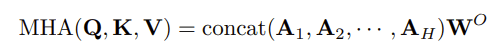
其中Ah是第h个Head的输出。
3. Masked scaled dot-product attention(掩蔽缩放点乘积注意力):通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention。其实scaled dot-Product attention就是我们常用的使用点积进行相似度计算的attention,只是多除了一个dk起到调节作用,使得内积不至于太大。
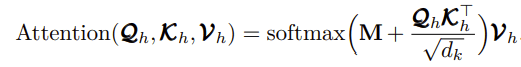
这里经过一个可选的Mask,再经过softmax之后,与Vh相乘。由于后面的操作是softmax函数,所以通过添加−∞实现屏蔽。掩蔽后,序列相似性矩阵的每一行使用softmax激活函数归一化为概率分布。最后,利用归一化相似矩阵与Vh的点积计算出带注意力信息的values。
训练策略
- 使用交叉熵函数作为Loss Function
- 每次训练迭代使用10个小批量的噪声语音信号,mini-batch = 10。迭代次数设置为200
- 每个mini-batch的输入信号的计算过程如下:每个干净的信号与随机选择的噪声输入,在随机的起点,用随机选择的信噪比(-10到20 dB,以1 dB增量)混合
- 对于每次迭代,干净的语音的选择顺序是随机的。
- 选择Adam作为优化器,β1 = 0.9,β2 = 0.98,ε = 10 -9 用于训练MHANet。
- 其中学习率α在训练过程中为:
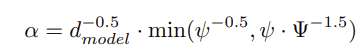
ψ为训练steps,Ψ为预热steps。学习率首先随训练steps增加而线性递增,直到训练steps >预热steps,然后以训练steps的平方根反比递减。这个策略用在训练的初始阶段,进行稳定学习。
改进策略
由于Transfermer 结构模型过大,不利于端侧部署。采用GRU网络对其进行优化。
模型调优
- 将原有Transformer架构改为GRU架构,参数量达到由480万减少到30万
- 通过更改网络架构,将模型大小限制在1M以内
- 采用加混响等数据增广方法对算法效果进行了调优
部署方案攻克
- 解决了部署过程分段处理带来的数据衔接问题
- 调研并采用了TFlite作为整体部署框架
- 部署过程重点解决了算法中逆误差、积分等算子的高效实现
成果
打通整个部署流程,生成了算法库,满足客户端落地要求。
算法参数量、模型大小、内存消耗、延时见下表:
| 参数量 | 内存 | 延时 | 算法库大小 |
| 30万 | 10M以内 | 16ms | 2M以内 |
效果展示
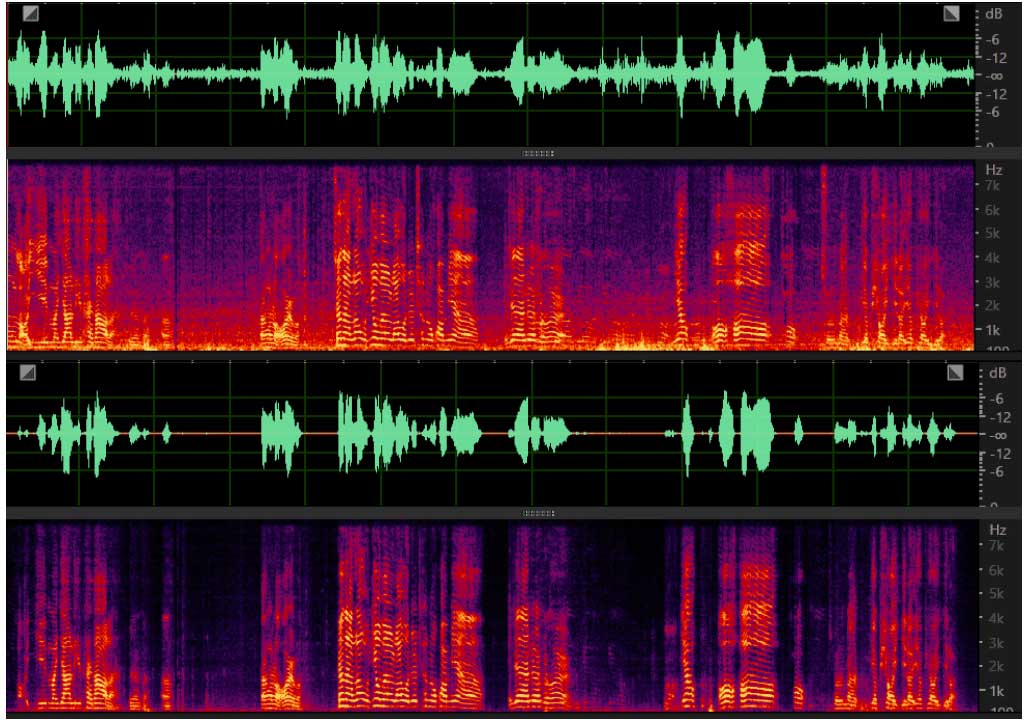
本算法采用传统算法和深度学习相结合的方案,降噪同时完好的保留了语音,部分降噪效果如下所示:
键盘噪声
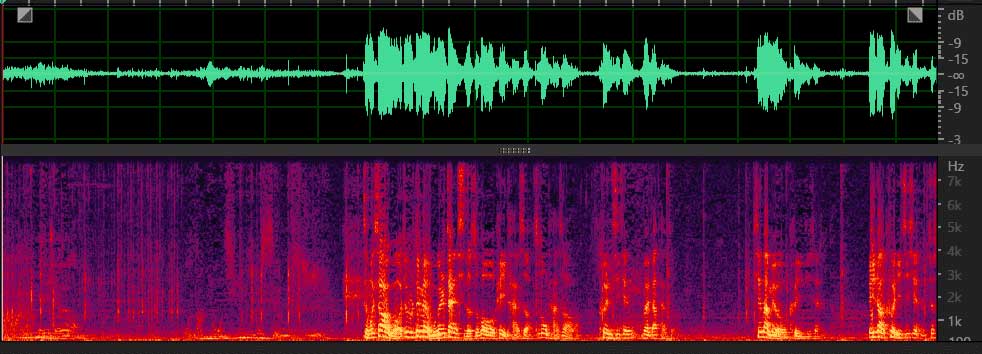
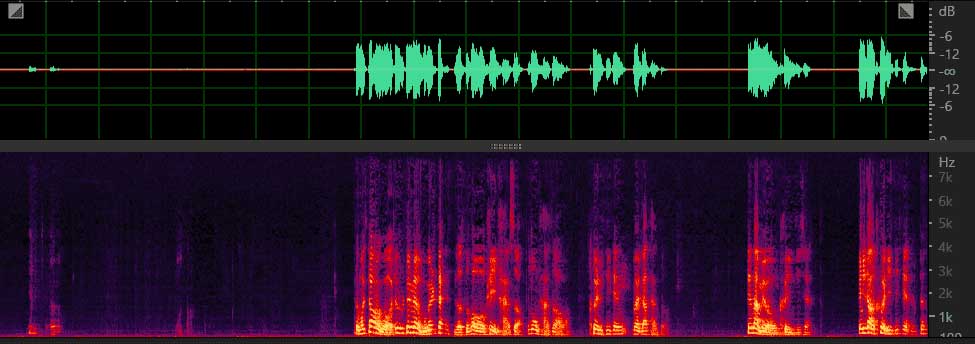
风噪路噪:
作者:毛鑫 蔡巧巧
审稿:何绍富 斗鱼流媒体技术委员会
原文:https://mp.weixin.qq.com/s/RKFZ9wnMPwv_ecN9GHJT2w
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。