
语音增强是指当语音信号被各种各样的噪声干扰、甚至淹没后,从噪声背景中提取有用的语音信号,抑制、降低噪声干扰的技术。
它的主要目标是从带噪语音中提取尽可能纯净的原始语音,提高语音质量和可懂度。
深度学习是实现语音增强最主要的方法之一,帮助我们从带噪语音中提取尽可能纯净的原始语音,提高语音质量和可懂度。
该技术在语音连麦、实时语音通信等场合有应用前景。
整体架构


整体架构简述:
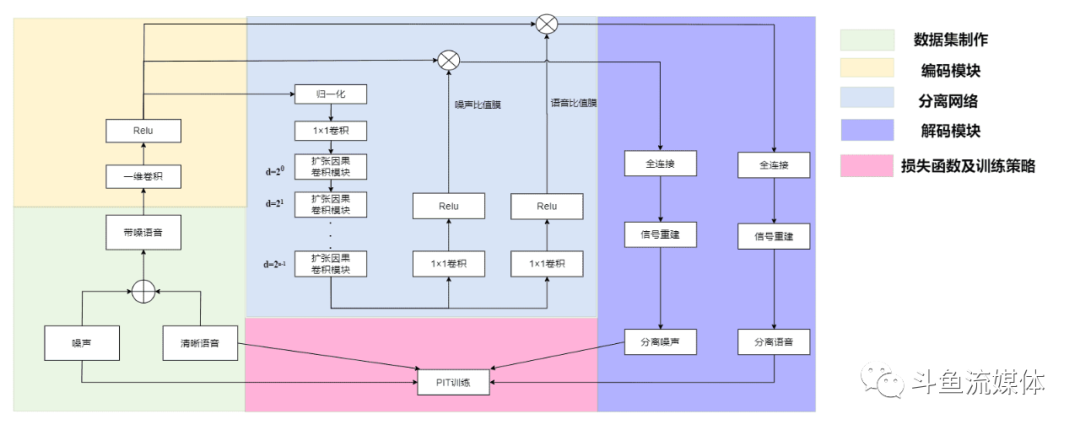
•整体架构为端到端训练框架,分为三大部分:特征提取(编码),分离网络,解码•特征提取:含噪声信号直接从原始时域信号提取特征,采用卷积进行线性编码•分离网络:采用全卷积的网络架构,生成语音和噪声对应的嵌入向量•解码:与编码类似,采用线性解码将编码信号映射回时域信号
详细方案设计
详细方案如下图所示,可分为:数据集制作,特征提取(编码模块),分离网络,解码模块,损失函数的训练策略.
数据集制作
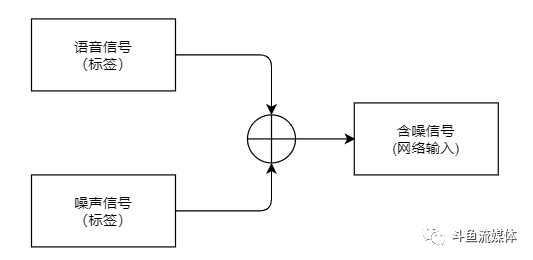
清晰语音数据:约20000条4s音频,10000条中文数据,10000条英文数据•噪声数据:约3000条4s不同种类噪声音频•采用 -10~10dB 信噪比将两路声进行混合•数据增广:翻倍•数据集总时长:约44h•生成数据维度:(32000,1)•生成数据格式:将训练数据转化为tfrecord格式,加快训练。
频域特征及其局限性
传统深度学习网络的输入特征,一般为频域特征(STFT,MFCC,……),采用频域特征局限性如下:
•STFT的准确性随着所加窗大小而变化的。小的时间窗,可以得到更加精确的时间信息,但频率信息分辨率降低。•大的窗,频率分辨率大,而无法获取精确的时间上的变化信息。•一般采用的窗长512,256(窗长太短,会影响频域分辨率),算法延时大小。•部分网络架构采用对频域的幅度进行分离,用含噪信号的相位,进行时域信号合成。错误相位信息影响语音分离性能。
原始时域信号特征提取及其优点
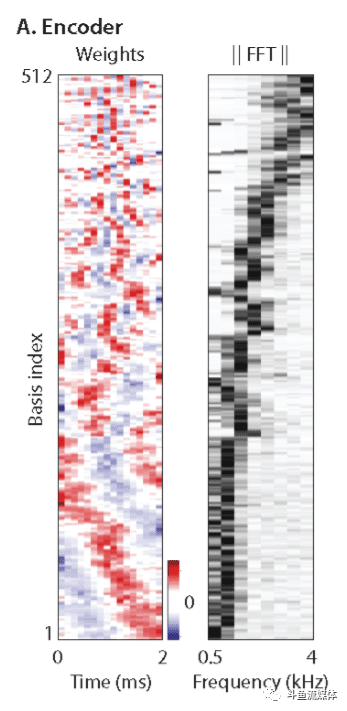
Encoder是一个线性的转换器(1维卷积,滤波器长度16,stride为8,通道数为512)。它就是一个权重矩阵。输入是一段非常短的声音信号,只有16个采样,即16维的向量。通过 Encoder 之后,会产生一个 512 维度的向量(3999,512)•相当于窗长16个点,远小于频域特征提取选用的窗长,对于8K采样,可以做到小于4ms的理论延时•采用时域信号作为输入特征,不涉及到相位问题,不存在错误信息•上图为训练后,Encoder滤波器系数的时域和频域分布情况:Encoder 矩阵每个维度的权重向量实际上是一个个滤波器。它们会编码不同频率的信号。低频的权重相对较多,因为人声在低频部分比较多。模型能自动学到要怎样来编码人声特征
分离网络
Encoder 输出向量,会喂给分离网络,让它产生两个 MASK,分别对应语音和噪声的概率。
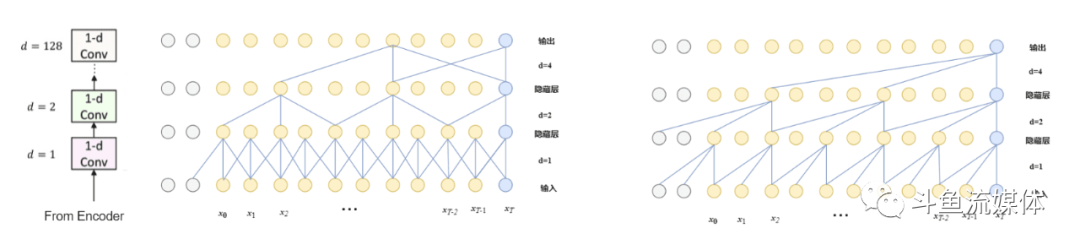
1.分离网络采用类似WaveNet的架构。如上图所示,由很多层的 1-D CNN构成。以图中三层 1-D CNN举例:第一层 CNN 会把相邻三个输入,用 filter 变成一个输出。第二层 CNN 会把跳格相邻的三个输入变成一个输出。第三层 CNN 则是把跳4格相邻的输入,用 filter 变成一个向量….这样第三层得到的向量视野范围就有 12 个sample的向量的信息。
2. 分离网络中的卷积选择可以分为两种:常规卷积,因果卷积。常规卷积需要依赖未来帧信息。降噪效果好。因果卷积仅需要利用历史和当前帧信息,降噪效果不如常规卷积,低延时,适合实时通话场景
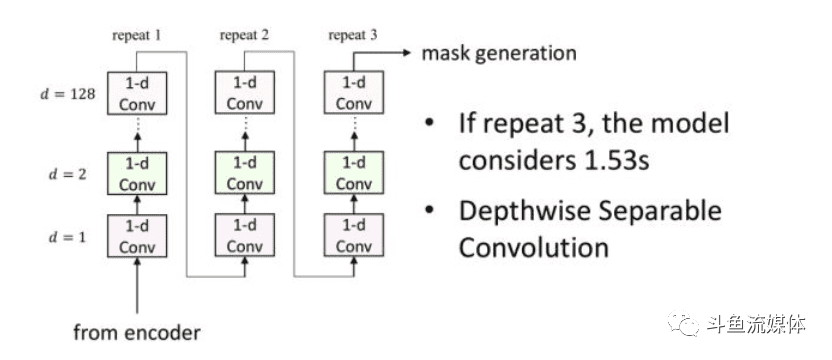
3. 往后再循环三遍这样的过程,再生成 MASK。为什么需要反复用这么多的 CNN 呢?因为如果 CNN 能反复更多次,就可以看到更长的信息。比较 12 个 sample 对一段波形语音来说,实在太少了。但如果我们像这样重复很多次,仅仅3遍流程,模型就可以看到 1.53s 的波形语音了。在每一层的卷积中,TasNet 采用了一个叫作 Depthwise Separable Convolution (DSC) 的技巧,卷积对各通道数据是解耦的,在通过1×1卷积将各通道的耦合找回来。它是一种可以让 CNN 参数减少的方法。
4. 第3步的输出,再通过1×1卷积,relu 得到两个 MASK。接下来我们再把这两个 MASK 分别和 Encoder 的输出相乘得到两个(3999,512)的向量,喂给解码器。
解码模块
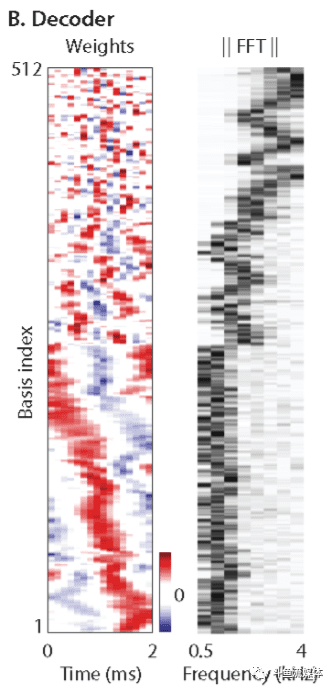
•解码模块将分离网络的输入,经过全连接的线性变换,生成维度(3999,16)的向量•上图中解码滤波器的频域分布有着相似的特性,低频的权重相对较多,能够更好的提取人声特性•在采用overlap-add的方法,得到最后的分离语音和噪声信号,维度均为(32000,1)
损失函数的训练策略
损失函数采用SI-SIR,训练策略采用PIT
•SI-SIR(尺度不变信噪比)是经常用于评估语音分离质量好坏的客观指标,其定义如下:
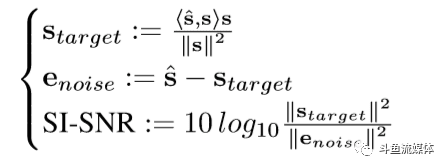
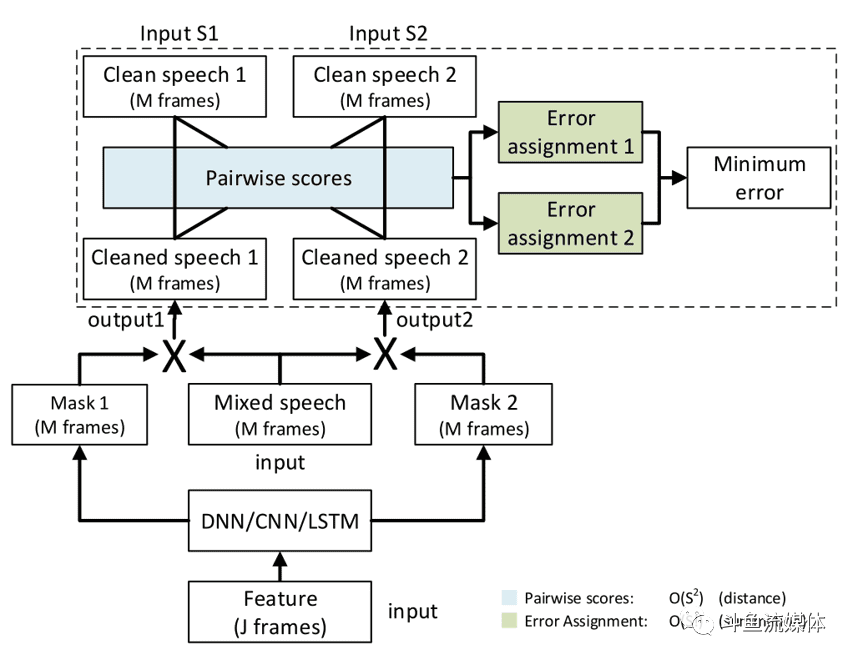
•PIT训练策略如下图所示,将生成两路音频信号,分别与标签求误差,考虑1:(生成1-标签1)+(生成2-标签2)、2:(生成1-标签2)+(生成1-标签2)两种损失函数,取较小的作为最终的损失。即采用更准确的损失函数调节网络。
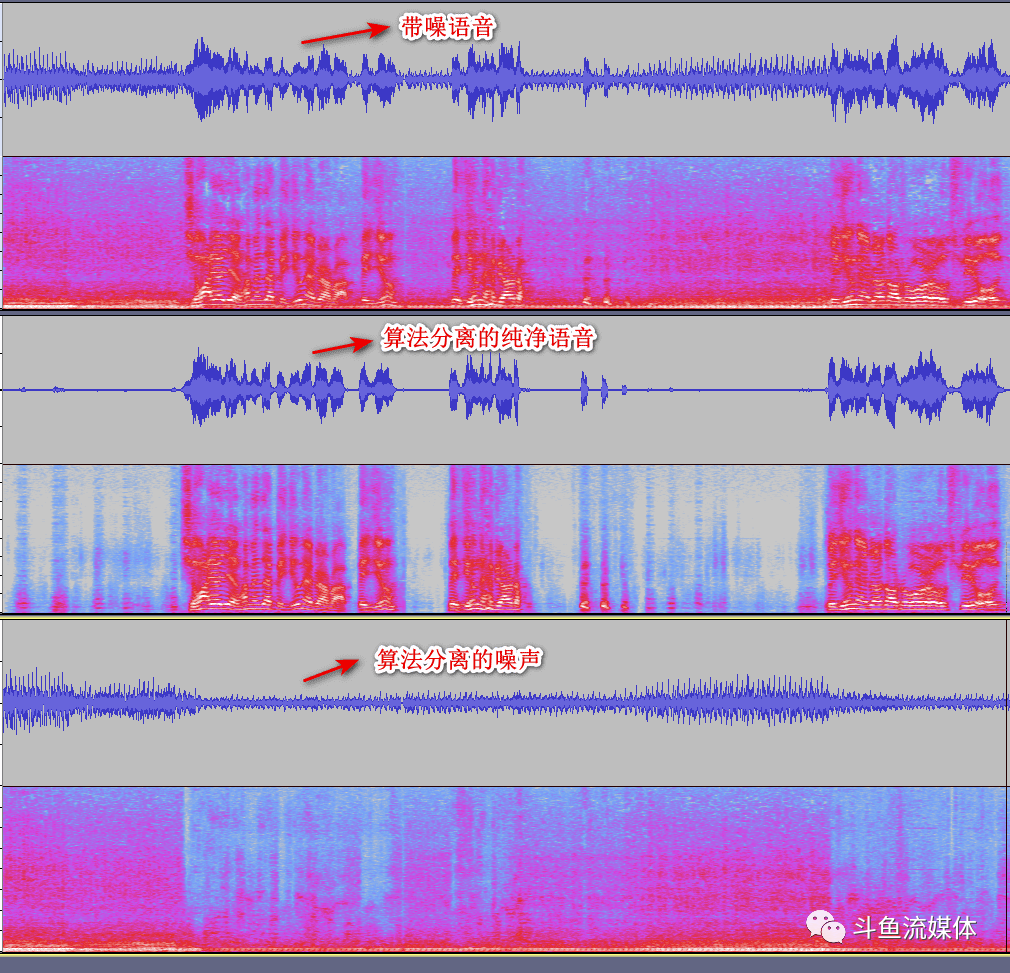
模型效果
模型最终的SI-SIR达到13dB,具体效果如下图所示:
作者:张李攀
审稿:斗鱼流媒体技术委员会
原文:https://mp.weixin.qq.com/s/MkfMvJaEFNuu6-KJdVUw9g
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。