


研究意义
随着深度学习应用的快速发展,神经网络模型的参数量变得越来越大,这意味着训练一个可用的神经网络模型需要更多的算力和更长的计算时间,因此如何提升神经网络训练的效率至关重要。然而训练效率在很大程度上取决于硬件后端和编译器。为了提升神经网络训练的性能,编译器的效率亟待提升,而这主要取决于计算图的优化、算子级别的优化和代码生成。主流的神经网络训练框架(如 TensorFlow、Pytorch)使用了供应商特定的、通过手工设计算子获得的算子库。然而,手工设计算子浪费了大量的算子级别的优化空间,因此研究人员提出了 TVM。作为一个端到端的编译器,TVM 实现了算子级的自动优化,因此比现有框架进一步提高了性能。此外,TVM 支持从多种神经网络框架中导入神经网络模型,并在不同主流硬件后端上部署。然而,TVM 的注意力集中于提升神经网络推理任务的性能,并不支持神经网络的训练,这导致TVM对于神经网络推理卓越的优化能力,无法移植到神经网络训练中。
本文工作
本文提出了TVM_T,第一个基于TVM、支持神经网络训练的端到端编译器。为了支持神经网络训练,本文提出如下三个创新点:(1) 合并损失函数到现有的计算图中,以支持前向和后向传播;(2) 在训练过程中采用设备到主机的机制来更新权重参数;(3) 集成了最先进的张量程序调优器,以自动优化神经网络训练程序。
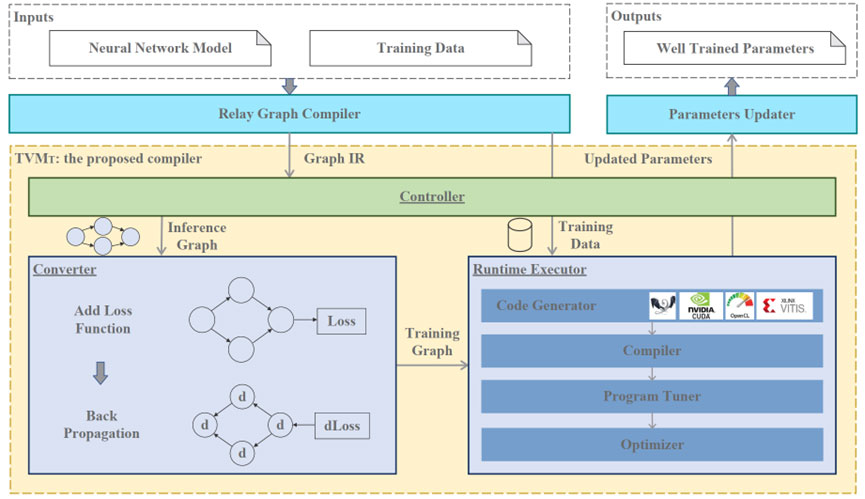
TVM_T的系统概览如下图所示。TVM_T 由三个主要模块组成。(1) 控制器, 负责整合训练的编译和执行任务;(2) 转换器, 负责将给定的推理模型转换为训练模型;(3) 运行时执行器, 负责编译、优化和执行训练模型。
实验结果
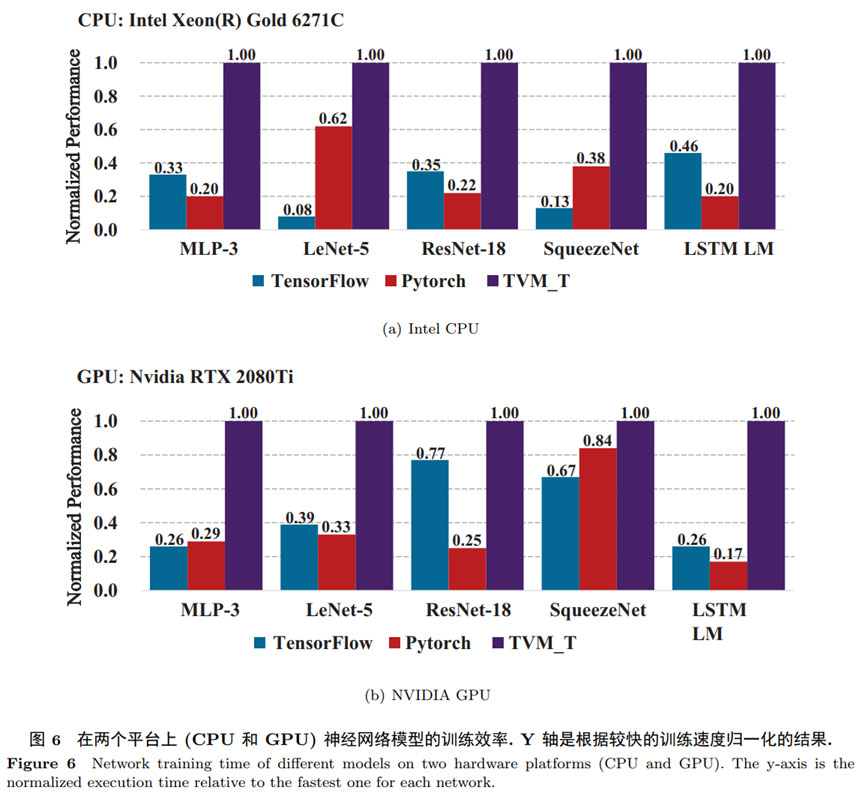
本文提出的方法在通用神经网络模型MLP、LeNet、ResNet、SqueezeNet以及LSTM上进行了验证。比较对象为Pytorch、TensorFlow,实验结果如下图所示,针对 Intel CPU,TVM_T在所有的基准神经网络模型上的训练性能都优于 Pytorch 和 TensorFlow,并且达到了最高 11.5 倍的性能提升. 如图 6(b) 所示,针对 NVIDIA GPU, TVMT 在基准神经网络模型上的训练性能都优于 Pytorch和 TensorFlow, 并且达到了最高 4.88 倍的性能提升。
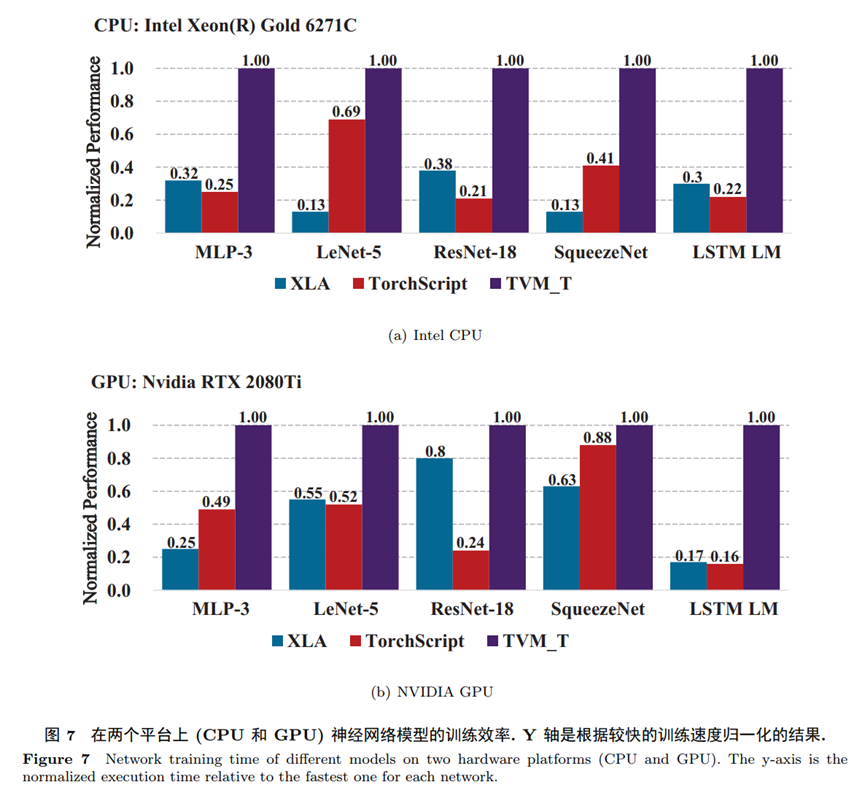
此外,XLA和 TorchScript分别是TensorFlow和Pytorch可以在训练过程中使用的神经网络编译器。针对XLA和TorchScript,我们在与TensorFlow和Pytorch相同的实验设置下测试了这两者的端到端训练性能。
下图显示了在 Intel CPU 和 NVIDIA GPU 上的实验结果。如图所示,针对 Intel CPU,TVM_T在所有的基准神经网络模型上的训练性能都优于XLA和 TorchScript,并且达到了最高6.7倍的性能提升。针对NVIDIA GPU,TVM_T在所有的基准神经网络模型上的训练性能都优于XLA和TorchScript,并且达到了最高5.25倍的性能提升。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。