
本文介绍了神经网络编码 (NNC) 标准 (ISO/IEC 15938-17) 的第一个开源和符合标准的实现 NNCodec,并描述了其软件架构和主要编码工具。编码引擎的核心是上下文自适应算术编码器,可动态调整其二进制概率模型以适应权重统计。作者表明,NNCodec 实现了比常用于神经网络压缩的霍夫曼代码更高的压缩,而且 NNCodec 的平均码字长度通常低于香农熵界。该软件和演示可以在 https://github.com/fraunhoferhhi/nncodec 上获得。
题目:NNCodec: An Open Source Software Implementation of the Neural Network Coding ISO/IEC Standard
作者:Daniel Becking, Paul Haase 等
来源:ICML 2023
文章地址:https://openreview.net/pdf?id=5VgMDKUgX0
内容整理:杨晓璇
引言
人工智能方法在信号处理许多领域的普遍应用导致对底层神经网络(NN)的高效分配、训练、推理和存储的需求不断增加。为此,需要寻求有效的压缩方法,提供最小的编码率的同时,神经网络性能指标(例如分类精度)不会降低。
如果数据源包含可以利用的依赖性或统计特性,熵编码可以有效地压缩原始数据。它能将输入元素序列 ω压缩成长度约为 -log2P(ω)比特的输出码字。这样,出现频率较高的元素就可以用较少的比特来表示。这种可变长度编码方案可用于进一步压缩已经量化的 NN。哈夫曼编码(Huffman)就是这样一种可变长度熵编码策略。然而,在实践中,哈夫曼编码可能需要庞大的编码词表,计算复杂,会产生的比特流冗余。算术编码是一种改进的熵编码策略。由于输入元素序列ω的算术编码是迭代构建的,因此不需要存储编码字表。对于图像或视频等经典源信号,自适应算术编码方案的优越性已得到证实。最近,它对 NN 源数据的高效适用性也得到了证实。因此,DeepCABAC 的上下文自适应二进制算术编码器成为最近发布的 NNC 标准(ISO,2022)的编码核心,本文介绍了该标准的开源软件实现。主要贡献如下:
- 高级 NNCodec 架构说明。
- 完全符合 ISO/IEC 神经网络编码 (NNC) 标准的实现。
- 特定 NNC 工具的功能说明,这些工具利用信号统计实现高压缩增益。
- 对编码工具效果的信号统计分析。
- 完整编码工具组合的广泛编码结果,以及与其他熵编码方法的比较。
NNCodec:NNC 标准软件实施和架构概述
NNCodec 是 NNC 标准的首个公开实现方案。它提供了一个布局清晰的用户界面(参见图 1),从而帮助机器学习(ML)社区在各种 ML 场景中对 NNs 进行高效压缩。NNCodec 内置支持 TensorFlow 和 PyTorch 等常用框架,可广泛适用于各种应用中的各种 NN。此外,NNCodec 还支持数据驱动的压缩方法(见第 3 章),例如基于 ImageNet 数据集的分类模型的局部缩放适应(LSA)。不过,其模块化架构设计允许扩展到任意模型和数据集。NNCodec 软件结构如图 1 所示,是一个 python 软件包,包括三个模块:nnc_core、framework 和 nnc,以及与之直接相连的基于 C++ 的 DeepCABAC 快速编码引擎扩展。在这里,nnc_core 模块提供了核心编码和压缩功能,为参数近似(量化)和熵编码提供了高级语法(hls)信号,并为模型处理和数据驱动方法提供了数据结构(nnr_model)和接口规范(ModelExecute)。它以通用形式实现压缩,以便不受任何外部框架的影响。对 PyTorch、TensorFlow 和 ImageNet 的支持由框架模块处理,该模块定义了从通用数据结构(nnc_model 和 ModelExecute)派生的框架特定数据结构。这确保了 nnc_core 的正确处理,同时在更高层次上实现了框架的特定功能。下一小节将介绍主要的编码工具。
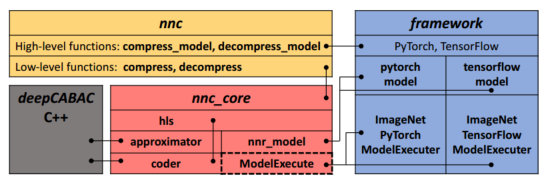

NNC 相关技术
NNC 编码流程包括三个阶段:预处理、量化和熵编码。首先,量化和熵编码这两个核心编码阶段将分别在 3.1 和 3.2 小节中介绍。经典的 NN 数据缩减方法,如稀疏化、剪枝或低秩分解,可在核心编码之前应用。作为预处理阶段的一部分,批量标准化折叠和局部缩放适应是修改信号统计量的具体方法,分别在第 3.3 和 3.4 小节中介绍。
量化
与其他编码标准类似,NNC 也有一个参数量化阶段,可提供:
- 进一步压缩
- 可进行无损熵编码的整数量化索引。
为此,NNC 规定了使用均匀重构量化器(URQ)进行标量量化的方法和使用依赖量化(DQ)进行矢量量化的方法,DQ 也称为 Trellis-coded 量化(TCQ),通常可在相同模型性能水平下实现更高的压缩效率。标量量化方法使用一个具有均匀间隔重构级别的 URQ。相比之下,DQ 采用两个标量量化器,具有不同的重构级别和可切换的程序。对于这两种方法,重构级别都可以由整数量化指数决定,而对于 DQ,还可以由应用的量化器决定。NNC 规定传输整数编码本,该编码本可从任意量化方法(如 K-means 聚类)的输出中导出。在所有情况下,量化步长△ 都来自整数量化参数 qp,它提供了一种速率-性能的权衡机制。NNC 允许为每个模型参数(张量)指定一个单独的 qp 值。优化这些 qp 值可以显著提高压缩效率。为此,NNCodec 提供了无数据 qp 优化技术(通过“–opt qp”启用),该技术基于张量统计,如标准差或权重。
熵编码
对于熵编码,NNC 采用基于上下文的自适应二进制算术编码 (CABAC) 方案的改编版本。它由三个阶段组成:二值化、上下文建模和二进制算术编码。
二值化阶段将每个要编码的符号(例如量化权重)映射到二进制符号序列(bins)。上下文建模阶段将每个二进制符号与上下文模型联系起来,该模型将概率估计值与二进制符号联系起来。二进制算术编码阶段利用上下文模型提供的概率估计值对二进制符号进行编码(或解码)。每个上下文模型都实现了后向自适应概率估计器,该估计器会保持一个代表概率估计值的内部状态。在编码(或解码)一个 bin 后,状态会被更新。如果处理了一个值为 1 的 bin,则 bin = 1 的概率估计值会增加;如果处理了一个值为 0 的 bin,则 bin = 1 的概率会降低。概率估计值的增减程度可以通过自适应速率参数来控制。
NNC 支持每个上下文模型的自适应速率设置的前向信号,即编码器可以优化每个上下文模型的自适应速率(和初始概率)并在比特流中传输这些优化的参数。对于(量化整数)权重的二值化,截断一元码与符号标志和指数哥伦布码组合。这确保了较小量级的权重由较少的二进制符号表示。此外,复杂的上下文建模确保 DeepCABAC 能够适应各种不同形状的权重分布。
批量标准化折叠
批量标准化(BN)是一种对每个数据批次的 NN 层输入激活进行归一化的技术,以获得更稳定的训练。批量标准化折叠(BNF)是一种将 BN 乘法部分 α “折叠”到前一个 NN 层权重 W 中的技术,即 wfold = αW,并用 δ 替换该层的偏置b:
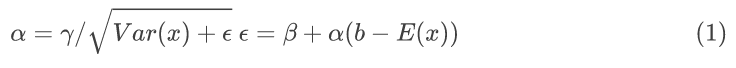
在解码器中,δ 参数可以加载到权重模块的偏置缓冲区b中(这样可以从计算图中移除相关的 BN 模块,以提高模型速度),或者加载到 BN 模块的 β 缓冲区中,同时将其余 BN 参数设置为默认值,即 E =0、 Var = 1和 γ =1。
局部缩放自适应
局部缩放自适应(LSA)为每个输出元素的 NN 层配备了额外的可训练缩放因子 。具体来说,每个张量行分配一个缩放因子,而张量行又可以代表一个卷积滤波器或单个输出神经元。量化后,除缩放因子外的所有模型参数都是固定的。这样,NNCodec 编码器就能在一定程度上补偿可能产生的量化误差,从而通过更粗的量化支持更高的压缩率。随后,缩放因子可以通过乘法与 α 合并,即 α:=αs,这样 LSA 与 BNF 结合使用时就不会引入额外的编码参数。最后,NNCodec 的解码器将 α 向量与 W 的相乘。
神经网络参数统计
一个 NN 的权重统计是不对称的单调递减分布,其平均值接近零(类似高斯或拉普拉斯)。为了利用大量的零值,DeepCABAC 在第一个二值化步骤中确定权重元素是否为“重要的”非零元素,或者是否量化为 0。该 SigFlag 的上下文模型初始设置为 50% 的概率,但会根据统计数据自动调整。
图 2 展示了一个编码数据单元(由卷积层及批量标准化折叠模块组成)的参数分布情况。根据公式(1),图 2 左侧的原始 BatchNorm 参数被折叠成各自的乘法(α)和加法(δ)混合。然后,α、δ 和权重 W被均匀量化(参见图 2 中间)。此外,还可选择应用 LSA 来训练缩放因子 s,将其与 α 相乘,然后与 β 和 W一起在一个编码单元中进行编码。在解码器中,通过将整数表示与其相关的 qp 值相乘、将 α 与 W 合并以及将 δ 载入 BatchNorm 模块的 β 参数来重构参数;其余 BN 参数设置为默认值(参见图 2 右侧)。
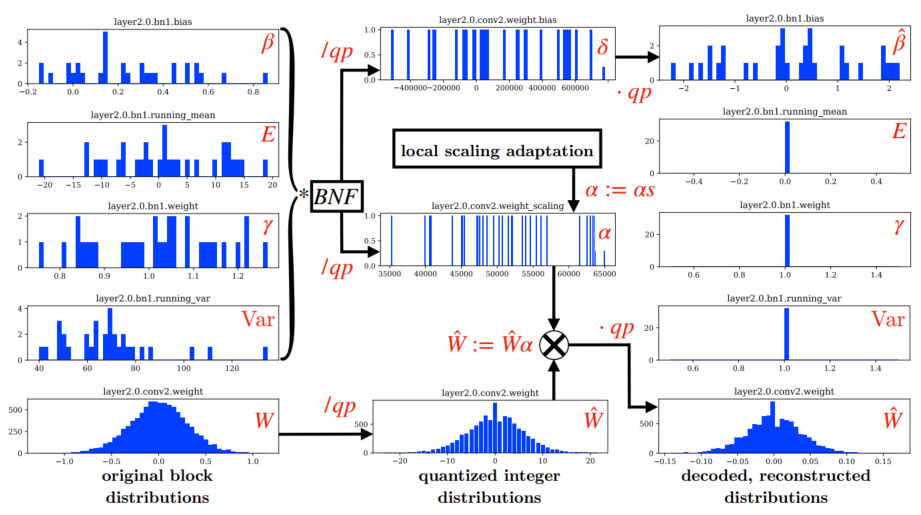
编码结果
编码工具配置分析
图 3 描述了 ResNet-56 的编码结果,在 CIFAR-100 上预训练达到 66.79% top-1 准确率。图 3 中的左表列出了启用工具的 16 种组合。然后,左侧矩阵显示对于每个组合生成的比特流大小以及重构解码的神经网络后所达到的精度。在 x 轴上,基础 qp 包含一系列不同的量化步长 △,从精细 (qp = −36) 到粗略 (qp = −10)。每个参数的实际 qp 可能会偏离基本 qp,例如,对于非权重参数或者如果启用了 opt_qp。右侧的矩阵显示反转的结果,即文本的准确性和比特流大小。左侧矩阵使所有没有精度下降的编码神经网络都以黄色突出显示。这种基于颜色的行边界可以更轻松地识别所有组合中的适当率失真结果,例如,使用工具组合 15 和 qp = −16 编码的 NN(在图 3 中以红色补丁突出显示)。
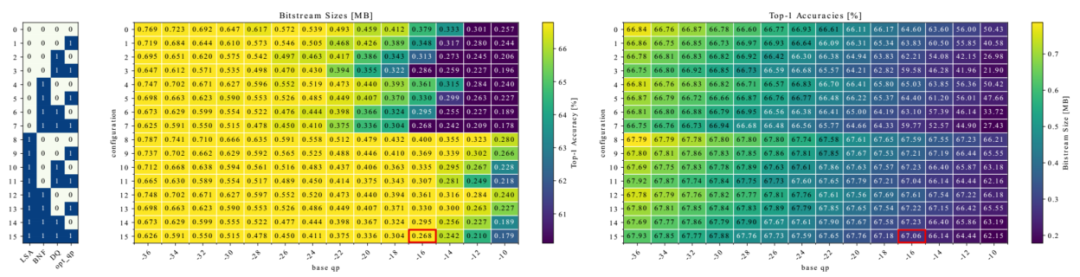
比较结果

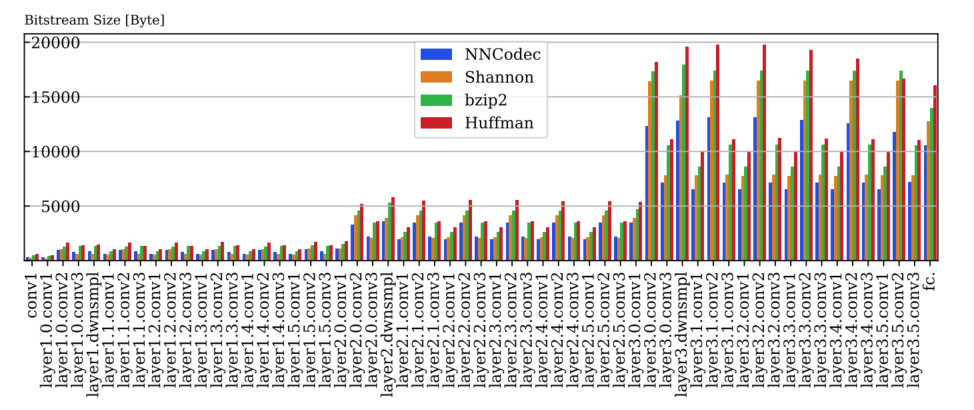
结论
本文介绍了 NNCodec,这是最近发布的 ISO/IEC NNC 标准的第一个开源软件实现。本文概述了软件架构和工具。文章分析了整个编码过程中的 NN 数据分布,结果表明 NNCodec 的平均码字长度通常低于香农熵界,因此优于用于 NN 压缩的其他常见 NN 编码策略。作者探索了 NNCodec 的超参数空间以及不同 NN 架构的压缩比。将为 ICML 神经压缩研讨会准备 NNCodec 演示。
通过这项工作,作者希望鼓励机器学习社区在其 AI 中使用这款符合 ISO/IEC 标准的压缩软件。NNC 标准的第二版正在进行中,另外还针对分布式场景中差分 NN 的编码进行更新。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。