
本文作者提出了可组合扩散模型(CoDi)。这是一种新的生成模型,能够处理任意组合模态输入,如语言、图像、视频和音频,进而生成任意组合模态输出。不同于先前已有的生成式AI系统,CoDi可以并行生成多个模态,并且它的输入不受像文本或图像一类的模态子集的限制。尽管缺乏多种不同模态组合下的训练数据集,作者提出了在输入和输出空间上对齐模态的方法,这使得CoDi可以自由地处理任意组合模态输入并生成任意组合模态输出,即使它们不存在于训练数据中。CoDi采取了一种新颖的可组合生成策略。这一策略通过在扩散过程中桥接对齐来构建一个共享的多模态空间,从而能够同步生成相互交织的模态,例如暂时对齐的视频和音频。文中证明,CoDi高度可定制且高度灵活,实现了强大的联合模态生成质量。
题目: CoDi:Any-to-Any Generation via Composable Diffusion
作者: Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, Mohit Bansal
来源: NeurIPS 2023
项目链接: https://codi-gen.github.io/
内容整理:张俸玺
引言
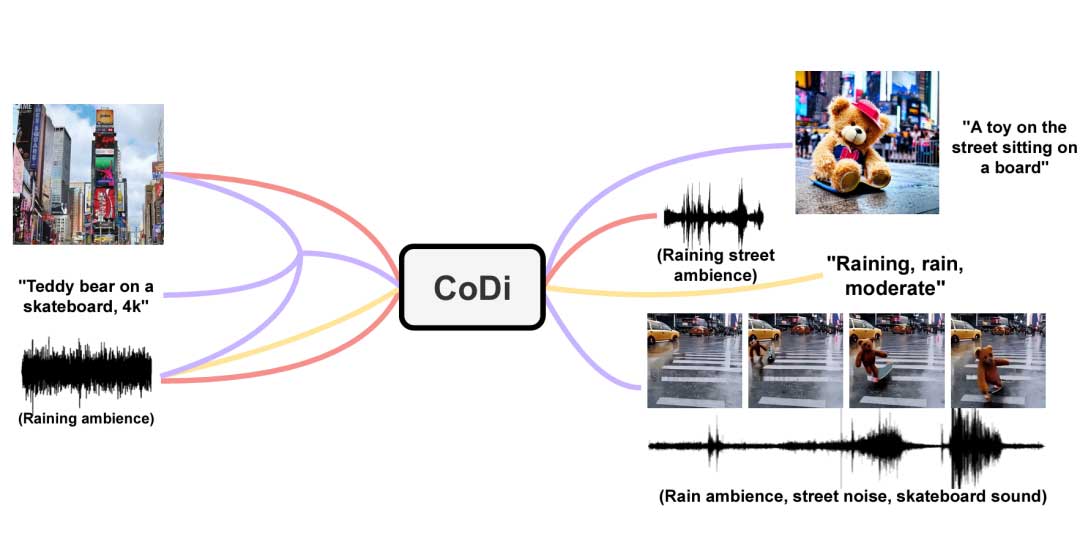

近年来,强大的跨模态模型兴起,这些模型可以实现从一种模态到另一种模态的生成,如文本到文本、文本到图像、文本到音频等。然而,这些模型在多种模态共存和相互作用的现实世界中的适用性具有局限性。尽管可以在多步生成设置中将特定模态的生成模型链接在一起,但每一步的生成能力依然有限,并且串行的多步处理可能是繁琐且缓慢。此外,当以后处理的方式拼接在一起时,独立生成的单模态流将无法一致和对齐(例如同步的视频和音频)。由于输入输出模态组合数量的呈指数级增长,训练一个可以处理与生成任意组合模态的模型需要海量的数据与计算。并且许多模态组合的对齐训练数据很少或不存在,这使得对所有输入输出模态组合进行直接训练的想法变得不可行。
因此,在本文中,作者提出了一种新的可组合扩散模型CoDi。这是第一个能够同时处理和生成任意模态组合的模型。总的来说,本文主要有以下两点贡献:
- 作者提出了一种面向对比学习的“桥接对齐”策略,使得模型能够有效地利用线性数量的模态训练目标对指数数量的输入输出模态组合进行处理和生成,进而成功实现了首个能够处理和生成任意组合模态的SOTA模型。
- 作者首次提出了通过多模态特征在同一空间进行特征对齐从而实现模型对任意模态组合的处理和生成,为任意模态的信息融合与语义对齐提供了一个极为重要的思路。
方法
Composable Multimodal Conditioning
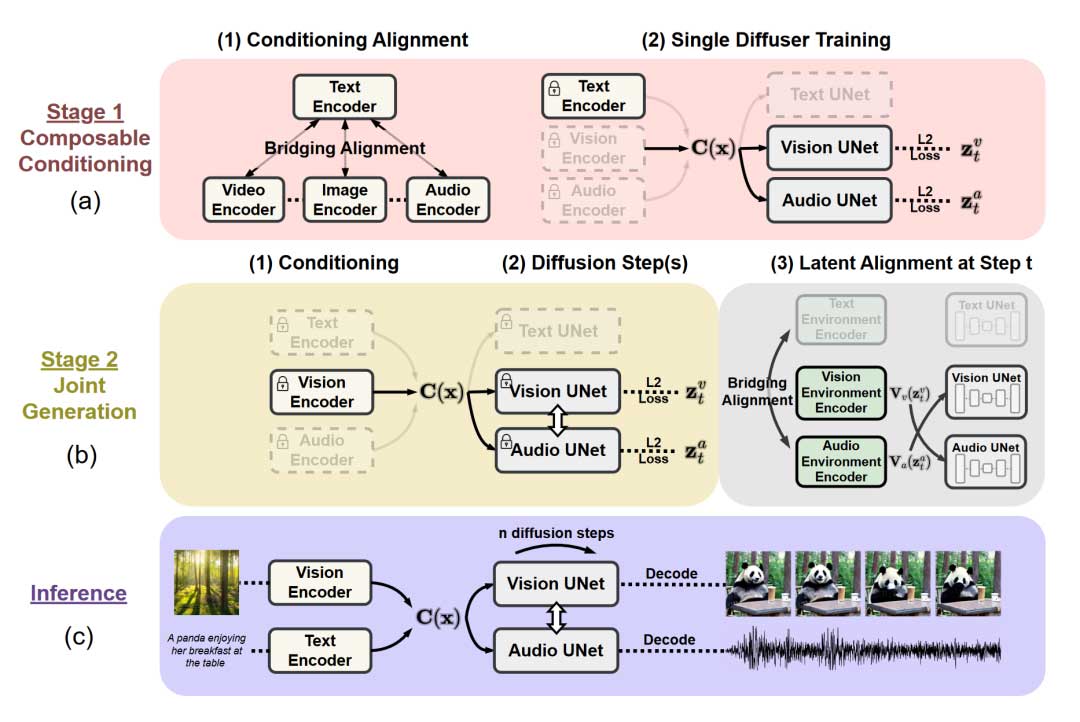

同时优化全部四个Prompt编码器的计算量过大。此外,某些特定的双模态缺少或者没有良好对齐的配对数据集。因此,作者提出了一种简单有效的”桥接对齐”策略,从而可以有效地对齐条件编码器。如图2中(a)(1)部分所示,本文选择了文本模态作为”桥接”所使用的模态。作者从一个预训练的文本-图像配对编码器(即CLIP)开始,随后使用对比学习的方式在音频-文本和视频-文本配对数据集上训练音频和视频Prompt编码器,并在此过程中冻结文本和图像编码器的权重。通过上述这种方式,文本、图像、视频、音频四个模态在特征空间中对齐。
Composable Diffusion
训练端到端的可以处理和生成任意组合模态的模型需要对各种数据资源进行广泛的学习。模型还需要维持所有合成流的生成质量。为了这些问题,CoDi被设计成为一个可组合的集成模型。在该模型的支持下,可以首先独立构建特定于单个模态的模型,然后再流畅的集成为一个最终的大模型。
具体来说,作者首先开始独立训练图像、视频、音频和文本的潜在扩散模型(LDMs)。然后再将这些扩散模型通过一种名为”潜在对齐”(Latent Alignment)的新机制有效地学习和参与跨模态的联合多模态生成。
Joint Multimodal Generation by Latent Alignment

实验
训练集
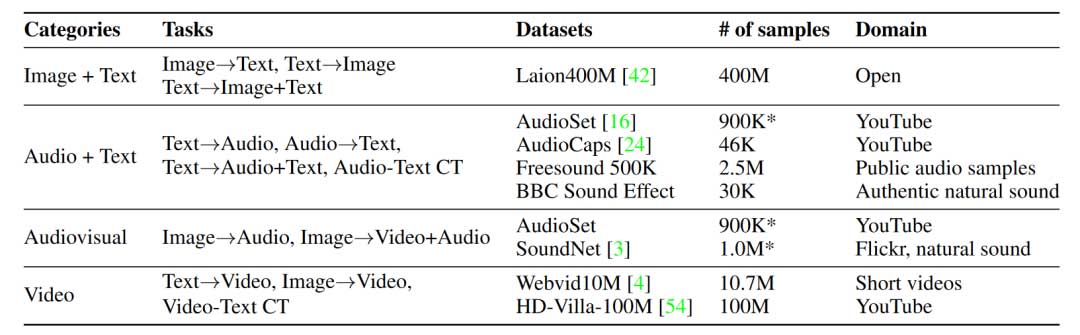
针对不同的模态组合,作者采用了不同类型的数据集进行训练,具体对应关系如表1所示。
单模态生成结果

单模态生成实验表明,CoDi在音频字幕生成和音频生成方面实现了SOTA;CoDi是第一个可以进行视频字幕生成的扩散模型;CoDi在图像字幕生成表现出与Autoregressive Transformer相当的SOTA性能;在图像生成与视频生成方面表现出来与最先进技术相当的性能。这表明该模型首先在单模态生成方面体现出优于或者与当前先进模型相当的性能。
多条件生成结果

多条件生成实验表明,CoDi在给定各种输入模态组合的情况下,能够实现较高的图像生成和视频生成性能。得益于作者提出的桥接对齐与可组合多模态推理方案,该模型仅在单一条件训练后就能实现对多条件的零样本推理。
多输出联合生成结果

作者在此首次提出了关于多模态输出联合生成的定量评估指标SIM,通过余弦嵌入相似度来量化两种生成模态之间的连贯性与一致性。具体公式如下:
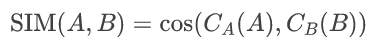
此处 A,B指生成的模态; CA,CB 是将 A 和 B投影到同一空间的对齐编码器。该指标旨利用对比学习的提示编码器来计算两种模态的余弦嵌入相似度。因此,指标数越高,代表生成模态越一致和相似。
结论
本文提出了一种具有开创性的多模态生成模型:可组合扩散模型(CoDi),它能够处理和生成由文本、图像、视频和音频组成的任意组合模态。文中提出的方法能够有效地利用各式各样的组合模态输入生成高质量且连贯的跨各种模态的输出。实验表明,CoDi在灵活利用广泛的多种模态组合输入生成单一或多种组合模态输出方面具备卓越的能力。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。