
1 前言
随着人工智能技术的快速发展,B站已经有非常多的AI算法可以用来助力多媒体业务,诸如超分辨率、人脸增强、视频插帧、窄带高清等等。如今,以扩散模型(Stable Diffusion)和大语言模型(LLM)掀起的生成式AI浪潮又给多媒体业务带来了更多技术可能。相对于各类AI算法模型的研发,模型推理与视频处理框架在多媒体业务部署中的重要性更为凸显,是工程化”基座“的存在。一个优秀的多媒体AI算法工程化框架,不仅可以提供更高的运行性能、异构计算及多平台支持等功能,同时也增加代码复用率,提升开发效率,加速了业务部署上线。为此,我们研发了一套多媒体业务算法工程化SDK,Bilibili Vision Toolkit (简称BVT),为B站的各类点/直播业务提供AI算法支撑,已在线上提供了上亿量级的视频稿件处理。另外,BVT是对之前同样也是我们研发的一款视频处理引擎BANG做了重新设计和全面的改进升级,集成了更多的算法,提供更广泛的推理引擎支持,改善多平台兼容性,以及增加可自定义任务流等特性。
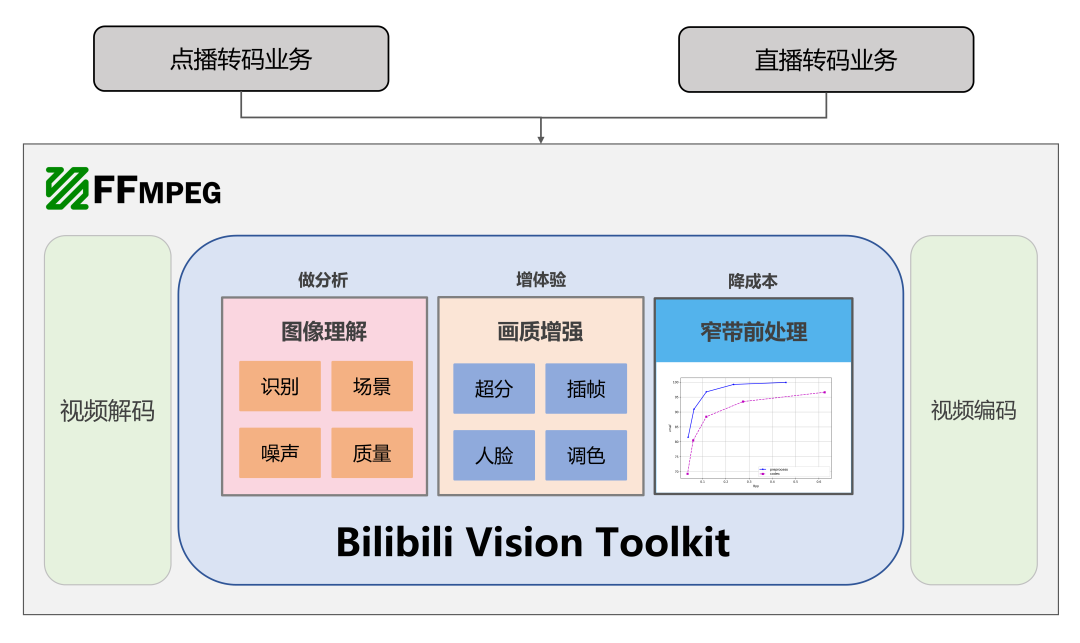

2 BVT技术解析
BVT是一套C++语言实现的SDK库,其中集成了多种多媒体AI算法实现,对外提供统一的API接口,后端接入多种推理引擎支持。BVT的典型应用场景通常为视频处理,比如在B站的点播视频转码服务中接入转码的前处理,包括超分辨率、窄带高清等算法。当然,BVT也支持图像-数据的任务(如检测),同样也支持其他多媒体数据类型输入(如音频)。不仅如此,BVT在设计之初考虑到为了便于多平台部署和多推理引擎支持,采用了低耦合的设计,划分成”核心层”和“模块层“,具备不同算法原子能力和不同推理引擎依赖的模块层与具有任务调度能力的核心层进行了解耦,大大增加了工程化的灵活性。另外,BVT还支持自定义任务Graph/Pipeline调度,在运行时通过配置文件配置任务流,将不同算法模块进行组合运行,这大大降低了代码的重复开发,提高了模块的复用性。
下面,我们将一一介绍这些功能特性。
2.1 整体架构与流程
BVT的整体架构主要分为核心层和模块层,其下由后端引擎层支撑,向上服务于外部应用层,如下图:
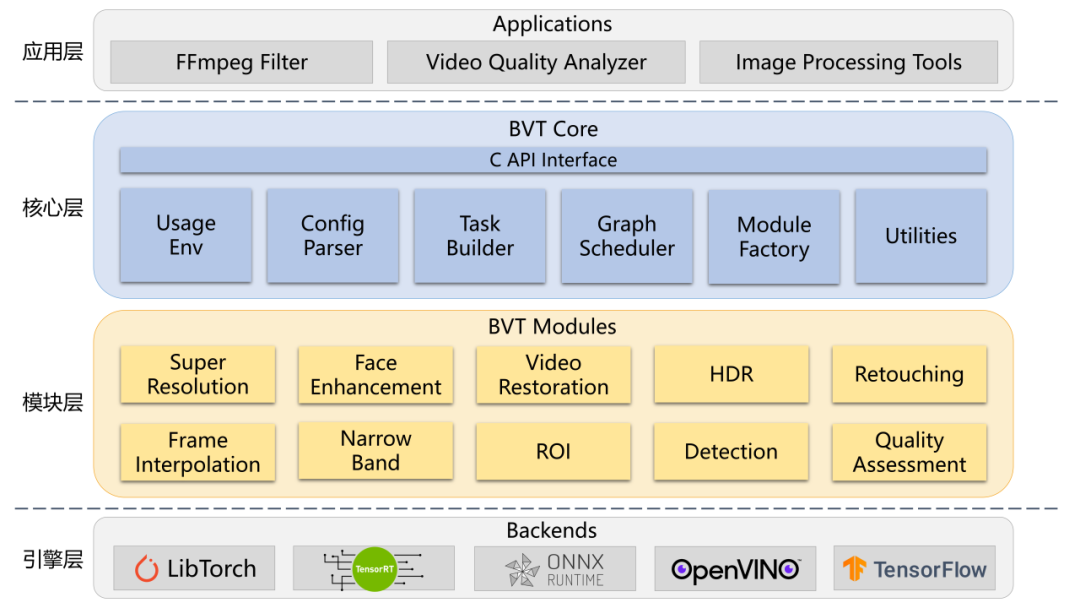
应用层为外部服务应用,通过BVT的API接口来实现相应的业务需求,其中最主要的实例是,我们实现了一个基于BVT的FFmpeg filter来对视频进行处理,包括超分辨率、人脸增强、插帧、调色、窄带高清前处理等功能。- 核心层的功能是实现与具体算法无关的任务调度,并提供对外的C API接口,以一个静态库的形式存在。其中组件包括环境检测、配置解析,任务组装,任务调度,模块工厂等。
- 模块层的功能则是实现具体的AI算法逻辑,并接入相应的推理引擎支持。模块层可根据所包含算法和依赖的不同封装成不同的动态库,由核心层动态加载并调用运行。
- 引擎层作为模块层的后端,封装了当下常见的深度学习模型推理引擎库(如TensorRT等),同时也对一些高性能计算库(如CUDA)与张量计算库(如Eigen等)做了集成。
通常来说,BVT典型的执行流程如下图所示:
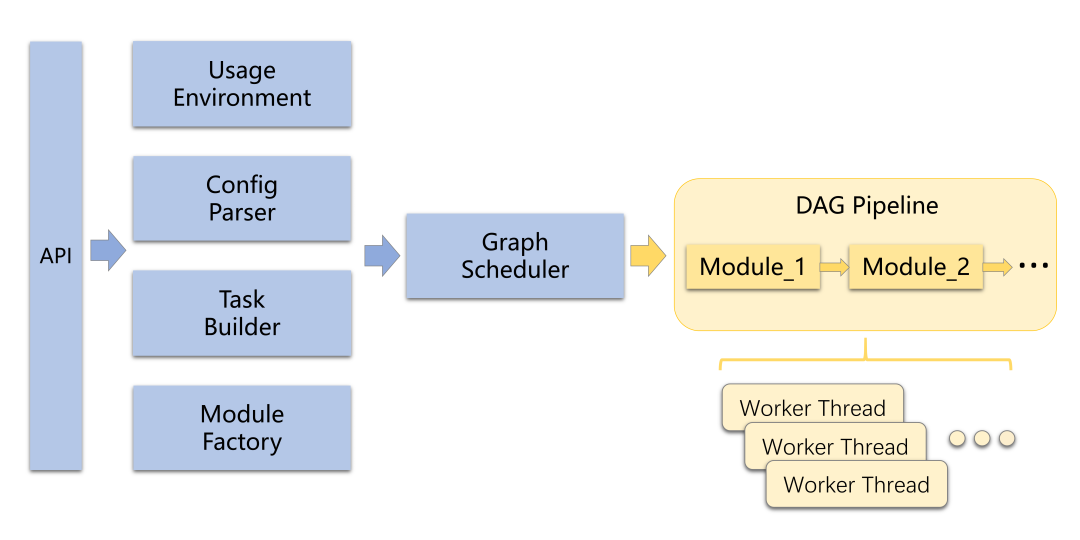
API接口接受用户输入的任务配置、任务数据等信息,然后在运行时动态地加载模块库,并从模块库中实例化出需要的算法对象组装成任务,交由调度器调度运行,最终返回用户结果。可以看到,这样的架构和流程的好处在于遵循了“低耦合高内聚”的软件工程设计思想,将不同算法模块之间的具体实现分开,将算法的执行与任务调度分开,使得代码的可重用性、可扩展性大大增强。
2.4 自定义任务流
自定义任务流是BVT的一个重要特性,能够将多个不同AI算法通过任务配置描述,组装成一个任务Pipeline,实现算法的多元搭配,丰富算法部署自由度。本质上,实现这个任务Pipeline是实现一次对有向无环图(Directed Acyclic Graph,DAG)的遍历,这里我们借鉴了taskflow、MediaPipe等开源项目,在BVT里实现了一个Graph引擎来实现任务的组装与调度,同时配合一个线程池来实现算法并行执行。
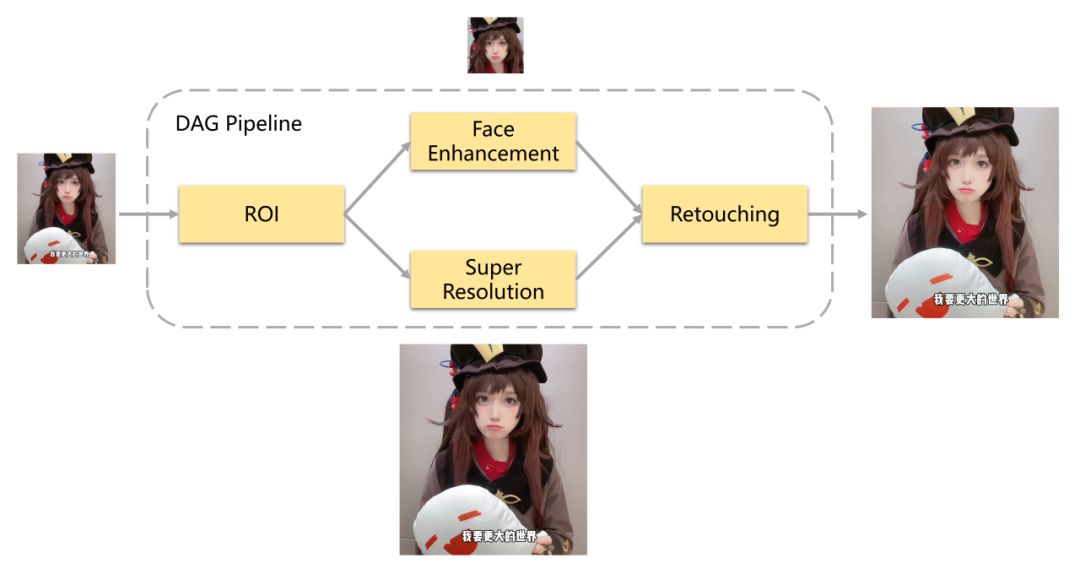
举个例子,如图所示,输入一张图片,首先通过ROI算法,将图片中关注区域检测出来(如人脸),然后将人脸区域交给人脸增强算法和将整张图片交给超分辨率算法分开并行处理,结果再融合成一张图片,最后经由调色算法模块处理,输出最终结果。这其实是多媒体业务中非常常见的需求,对于业务方有一些组合算法的想法,可以快速的通过配置来解决需求,而无需重新开发任务底层逻辑。
2.3 数据表示
由于BVT设计之初,考虑到多平台部署的需求,在模块层之间做了解耦设计,其中最重要的一环是对模块和模块间的传输数据进行封装抽象。我们将模块和模块之间传输的基本数据单元称为Packet,Packet中主要载荷的数据类型是张量即Tensor,我们认为任何AI算法输入输出的数据都可以表征成Tensor,而Tensor之下实际数据内容则是由对应不同设备的Buffer对象来保存。我们对Tensor类型进行了接口抽象,让其方便接入多种张量计算库(如LibTorch、Eigen等)来进行张量操作,底层的Buffer由不同的设备对象(如CPU、CUDA等)来做内存管理。值得一提的是,内存管理使用了内存池和引用计数,前者减少了内存的重复申请和释放,避免内存碎片的产生,而后者则是尽量减少模块间数据内存拷贝带来的开销,提升性能。这样,BVT通过使用统一的数据表示,不仅保证模块间的数据传输和衔接变得平滑,还兼具高效的数据处理效率,使得开发者可以更轻松地进行跨平台、跨设备的多媒体业务开发。
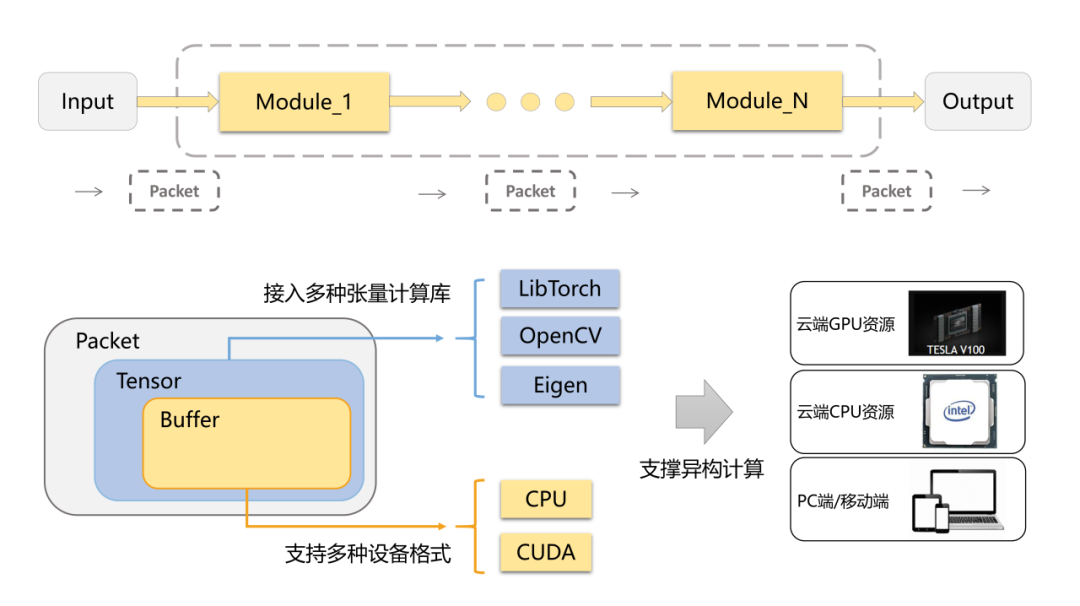
2.4 多推理引擎
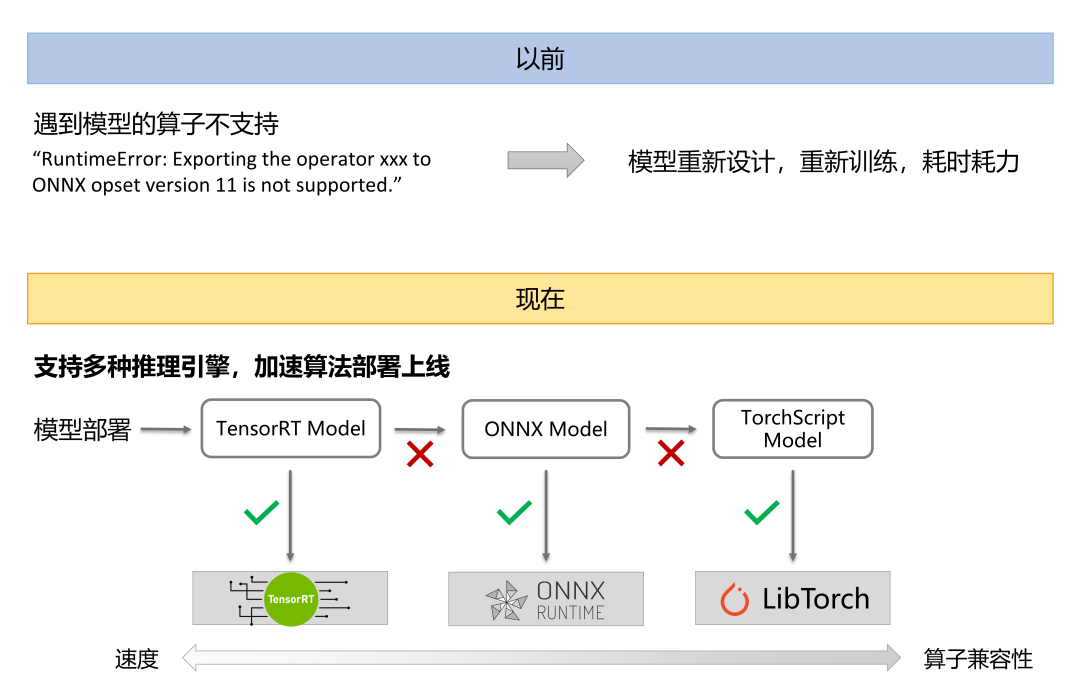
算法研发同学在做算法demo验证的时候,往往不会考虑算法部署的工程化难度,诸如,为了模型实现方便会用到一些推理引擎暂不支持的算子。为此,BVT通过抽象出统一的推理接口,后端接入了多种推理引擎,从性能高的TensorRT到算子兼容性好的LibTorch都予以支持。在部署算法落地时,可以根据算法特性使用不同的推理引擎推理,最大化性能的同时保证算法快速落地支持。在设计上,同一个算法模块的实现应是无关于具体的推理引擎的,我们将算法模型文件和模型描述文件(model.json)进行打包,该描述文件描述了模型文件所使用的推理引擎种类、推理引擎的具体版本以及输入输出等信息,在运行时加载算法模型后可动态地识别并调用对应的推理引擎去执行推理,这使得算法实现与推理引擎得到解耦。另外,BVT也可以在引擎层做一些自定义插件支持(如TensorRT Plugin),来增加特定的功能。
当前BVT已支持引擎包括TensorRT、LibTorch、OpenVINO、OnnxRuntime、TensorFlow等,后续还将集成MNN、ncnn等推理引擎来支持移动端部署。
2.5 模块解耦
BVT中,模块层与核心层是解耦的,模块与模块间也是解耦的,可以根据不同业务需要和运行环境,构建不同的模块动态库。这是由于,1)有的推理引擎库或高性能计算库文件体积过大或其依赖关系复杂,不利于直接链接到目标应用中去;2)模块库所包含的算法可以进行更细粒度的切分,更定制化的封装。BVT可以让目标应用只需链接核心层的静态库,这个静态库体积小且无额外依赖,在运行时,核心层动态的加载模块库,注册相应算法实现,加载推理引擎,这样在不同设备不同平台部署时更具灵活性。
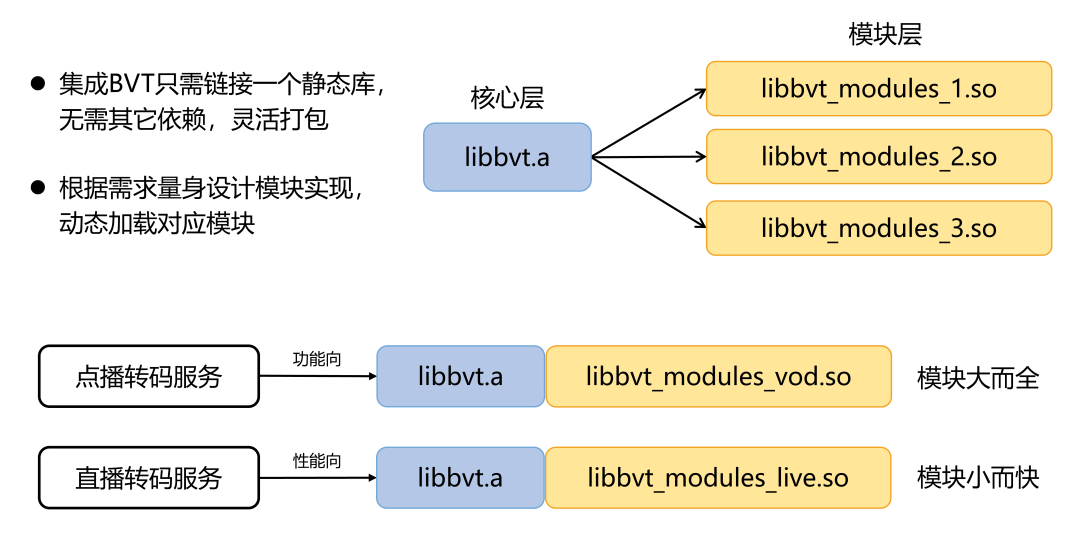
如图所示的例子,在点播业务中,加载功能大而全的模块库libbvt_modules_vod.so,而在直播业务中,有实时性要求,加载小而快的模块libbvt_modules_live.so。
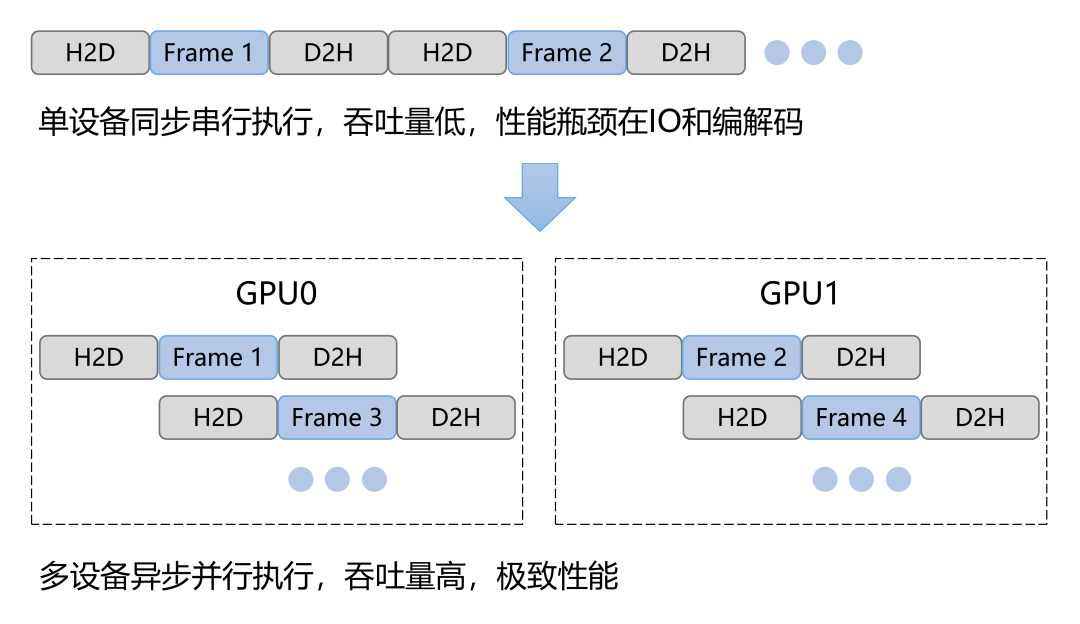
2.6 异步并行
相对于以前我们的视频处理算法工程化中的同步实现即一帧输入,进行算法计算,输出一帧结果,然后迭代到下一帧,而BVT是异步并行的实现,可以大大提升性能吞吐,减少了IO等待耗时。异步实现在API接口上体现为轮询(Poll),假设一次任务会话有若干次请求,每次请求都是非阻塞的,即函数调用完立即返回,下一帧请求的提交无需等待上一帧请求的完成,用户需要不断的轮询每个请求状态来获取结果,一旦请求完成用户则可立即拿走结果进行后续处理。另外,BVT还支持在不同设备(如GPU)上的推理并行,内置一个设备调度器,可根据设备利用率将不同线程调度到不同设备上执行算法,从而实现多设备并行。
2.7 API设计
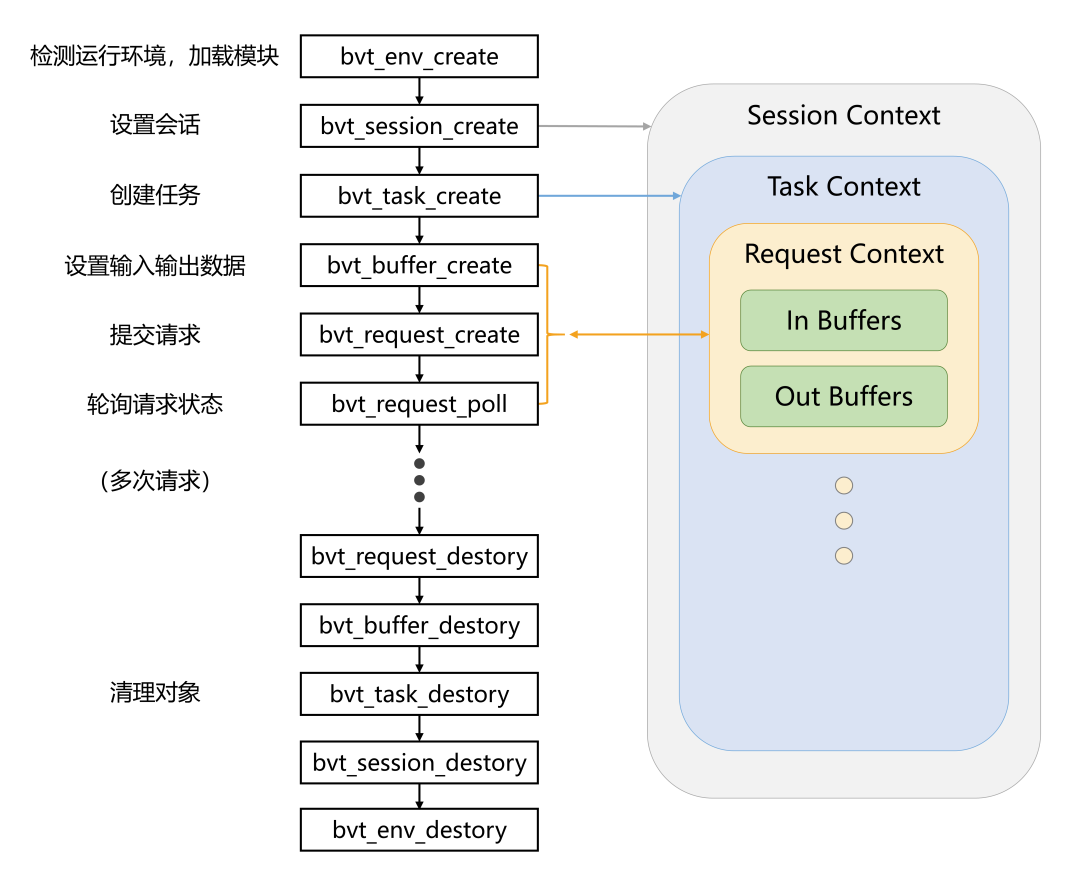
BVT提供了一套简洁的C语言API函数接口,一次典型的API使用过程如下图所示,其中包含会话、任务和请求三个概念。一个会话可以包含若干任务,每个任务组装了具体算法模块的执行管道;一个任务可以提交若干次请求,每个请求包含输入输出数据Buffer对象,且请求的调用是非阻塞的,需要轮询请求的状态;当请求状态为完成时,即可从Buffer对象中取走数据,继续迭代请求,直到任务完成。在会话、任务和请求的三种上下文中,保存了不同层级可以共享的数据,这使得与BVT的交互是有状态的,便于处理像视频这样的连续数据。同时,这样的API设计在实践中也足够通用,可以支持各种多变的应用开发场景。未来,我们还将提供多语言的接口支持,如Python Bindings。
2.8 FFmpeg Filter实现
这里我们介绍如何使用BVT来实现一个FFmpeg Filter,作为常见的视频处理应用示例。FFmpeg Filter实现一般有两种方式:filter_frame()回调和activate()回调,这里为了方便实现异步,我们使用activate()方式来接入BVT。因此,实现该Filter的一般流程如下:
- init() 初始化各类资源,包括调用bvt_env_create()来初始化BVT,检测运行环境、设备资源,解析filter参数来加载指定路径的模块库so;
- query_formats() 主要是协商输入输出的像素格式,如YUV420P,RGB24等;
- config_props() 获取输入和设定输出视频的媒体信息,解析filter参数来获取要执行任务的配置(例如超分辨率任务,有模型路径、倍率、输出宽高等),调用bvt_session_create()和bvt_task_create()创建一个BVT任务。任务可以是多个算法构成,此时BVT内部已经组装好当前任务流的管道,推理引擎加载了相应模型文件;
- activate() 视频帧处理的主要回调函数,实现具体如下:
- FF_FILTER_FORWARD_STATUS_BACK(outlink, inlink)转发状态;
- ff_inlink_consume_frame()从解码队列里读取解码输入帧,ff_get_video_buffer()准备输出帧,调用bvt_buffer_create()包装输入帧和输出帧数据;
- 对于每个输入帧,调用bvt_request_create()提交一次请求,将请求句柄放入请求处理队列;
- 轮询请求队列,按顺序bvt_request_poll()检查请求状态,若完成,将该输出帧通过ff_filter_frame()立即投递出去,并调用bvt_buffer_destory()和bvt_request_destory()清理中间数据;
- ff_inlink_acknowledge_status()检查EOF,如果到达视频流末尾,同步等待请求队列中所有剩余请求并投递结果;
- FF_FILTER_FORWARD_WANTED(outlink, inlink)请求更多。
- uninit() 最后调用bvt_task_destory()、bvt_session_destory()和bvt_env_destory()清理资源。
filter参数示例:
bvt=module={模块库路径}:task={任务名}:model={模型目录路径}:gpus={指定gpu设备列表}:cuda_in={是否cuda输入}:cuda_out={是否cuda输出}:task_opt='{具体任务私有参数}'至此,我们展示了BVT SDK的完整功能特性和技术细节。
3 总结
我们从提升多媒体算法部署开发效率,运行时性能以及多平台扩展性等出发点考虑,成功落地了这一套BVT解决方案,作为B站多媒体视频处理算法推理基座。当前BVT已经支持了多个点播和直播线上业务,包括点播视频增强、直播超分、游戏检测、窄带高清前处理等。另外,BVT提供了统一且简洁的API接口,对于上层不同的业务需求可快速集成;对于下层不同平台、设备和多种推理引擎依赖的支持也有极高的可扩展性,大大提高业务落地的自由度。在未来,BVT将会助力更多的多媒体算法落地,为B站多媒体业务打造更广阔的空间。
哔哩哔哩多媒体实验室是一支技术驱动的年轻队伍,具备完善的多媒体技术能力,以清晰流畅的极致视频体验为目标,通过对自研视频编码器、高效转码策略、视频图像分析与处理、画质评价等技术的持续打磨和算法创新,提出了画量可控的窄带高清转码算法、视觉无损视频前处理、超实时4K60FPS直播超分、视频画质评价、数字水印、自动提取高能看点等诸多高质量、低成本的多媒体解决方案,从系统尺度提升了整个转码系统的性能和效率, 助力哔哩哔哩成为体验最好的互联网视频社区。
作者:
张鹏伟:哔哩哔哩资深开发工程师
王沛洲:哔哩哔哩开发工程师
原文:https://mp.weixin.qq.com/s/Pw2oHLyCY6VqWzY-TmUCrg
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。