


论文摘要
在数字世界里,很多常见的数据类型都可以看作是一种特殊的连续函数形式,表征为隐式表征。例如,图像可以表征为将每个像素位置映射到对应RGB色值的连续函数。从这个角度出发,我们可以通过让一个紧凑的神经网络拟合这种函数表示形式,接着对网络权重进行编码,来实现数据压缩。然而,目前大多数的方法在这一过程中效率并不高。原因在于,将网络权重量化到低比特精度会严重影响重构质量。为了解决这个问题,我们提出了一个新颖的思路:利用变分贝叶斯神经网络对数据进行连续函数拟合,然后通过相对熵编码对近似后验权重样本进行压缩,而不是采用传统的量化和熵编码方法。这种策略使我们能够通过最小化-证据下界(-ELBO)直接优化压缩的率失真性能,并且通过调整值,针对给定的网络架构实现不同的率失真权衡。此外,我们还引入了一种迭代算法来学习先验权重分布,并采用了一种逐步精细化的变分后验处理过程,显著提升了性能。实验表明,我们的方法在图像和音频压缩方面都取得了出色的性能,同时保持了方法的简洁性。
论文简介
近年来,深度学习的发展带来了数据压缩领域的显著发展,特别是在有损图像压缩领域。受到深度生成模型,尤其是变分自编码器(VAE)的启发,深度图像压缩模型在客观指标(如PSNR和MS-SSIM)和感知质量上均超越了最佳手工设计的图像压缩方案。然而,这些方法的成功很大程度上归功于它们为特定数据模态设计的复杂架构。然而,这使得将它们转移来压缩不同数据模态变得具有挑战性。为了解决这一问题,近期的研究 [1] 提出了将单个数据视为映射坐标到值的连续信号,并通过过拟合小型神经网络,即隐式神经表示(Implicit Neural Representations, INRs),来压缩它们的权重。尽管INR在灵活性上有优势,但现有的基于INR的压缩方法与针对特定模态的神经压缩模型相比仍存在显著的性能差距。
在这篇论文中,我们提出了一种简单却通用的方法,通过将INR扩展到变分贝叶斯形式(variational Bayesian INRs)来解决这一问题。我们将数据比如单张图像拟合成一个变分后验分布(variational posterior)的贝叶斯网络(Bayesian Neural Network),而不是一个点估计。然后,我们使用相对熵编码(Relative Entropy Coding, REC)算法 [2] 来压缩INR的分布的一个采样。这样,我们可以直接优化INR的rate-distortion tradeoff这一有损压缩中最重要的目的。我们将这套新的框架称为COMBINER(Compression with Bayesian Implicit Neural Representations),如下图所示。
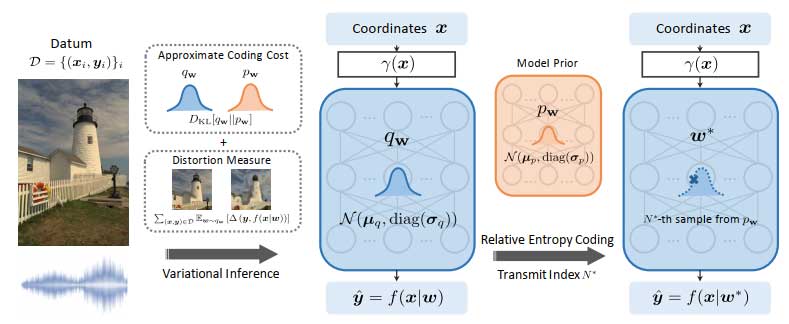
基于这套我们新提出的框架,我们还引入了两个重要的技术改进。首先,我们提出了一种学习网络权重先验分布(model prior)的迭代算法,给出了通过一组后验分布来估计先验分布的解析解。其次,我们还提出了一种逐步细化后验分布的渐进策略,可以不断修正相对熵编码所带来的损失。具体方法如下一节所述。
方法介绍
(1) A* Coding / Relative Entropy Coding
为了实现码率失真联合优化,我们将数据的信息编码(encode)为贝叶斯网络的高斯参数分布,但是我们知道分布的无损传输是非常困难的,比如对于高斯分布我们需要分别用足够的精度传输分布参数mean和scale。事实上,我们可以通过相对熵编码(Relative Entropy Coding, REC),在这里也是A* Coding [2],来实现分布的一个近似采样(a sample from the posterior distribution)的传输。A* Coding的具体算法流程如下:

可以看到A* Coding需要在编解码端维护一个相同的随机数发生器,以及共享一个对于不同压缩数据都一样的model prior。这充分说明了model prior对于网络的重要性。需要指出的是,另一方面model prior还直接影响了rate-distortion tradeoff中的rate值。
(2) Model Prior
为了得到尽可能好的model prior,我们提出了一种迭代式的策略配合解析解来高效的学习。给定一组图像,我们可以先随机初始化一个model prior,然后“稍微”用这个model prior来优化一下这组图像中每一张图像对应的model posterior,然后可以用这里算法中提到的Equation (5)来用解析解更新一下model prior,然后再迭代式的优化posterior。
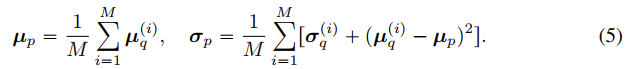
如上图所示,我们在这里也给出了如何从一组posterior distribution中来更新prior distribution。
整个学习model prior的算法如下所示,我们通常在实验中会进行64到256轮迭代,每轮迭代会梯度下降优化约30-100次model posterior distribution,然后会利用上(5)式来更新一次model prior。

(3) Posterior Refinement
类似于基于VAE编码的自回归上下文模型[3],我们提出了在编码时候进行自回归微调,我们将INR网络参数按照固定的编码budget分为了数组,然后按照顺序一个一个的进行组的A* Coding。在编码完一个组之后,我们对剩下的所有未编码的参数按照率失真损失函数进行微调,这样可以一方面弥补前面实际编码参数组偶尔出现的坏的样本,另一方面可以通过微调后面的组来更好表征原始待压缩信号。通过我们提出的Posterior Refinement策略,我们可以在小数据集上大大提升压缩的率失真性能,但是会使得编码时间大大增长。
实验结果
我们首先在图像压缩任务上在小分辨率的CIFAR数据集上(如下图左)和大分辨率的Kodak上(如下图右)分别做了实验。实验结果与之前方法的比较如下图所示。
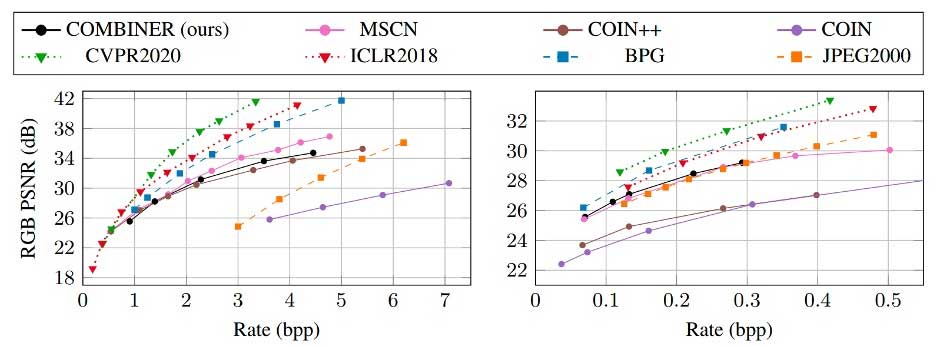
在上图中,我们比较了三类方法,分别有,传统编码方法包括BPG,JPEG2000,在图中用虚线来表示。基于VAE的编码方法包括ICLR2018 ,CVPR2020 ,在图中用点线来表示。基于隐式表征的编码方法,包括COIN [1],COIN++,MSCN 和我们提出的COMBINER,在图中用实线来表示。可以看到我们提出的COMBINER与之前的隐式表征压缩方法相比取得了最优的性能,但是仍然与现在流行的复杂的VAE框架下的图像编码方法的率失真性能有一些差距,特别是在高码率端。另一方面来说,基于隐式表征的图像编码方法在低码率端展现出超过VAE编码方法的潜能。
由于我们的方法在实际编解码图片时,编码的过程分为两步,分别是学习给定信号的对应隐式表征网络的后验分布,然后是渐进式的微调来提高编码的性能,所以可以想象编码的时间复杂度相较于之前的方法有不小的增加。另一方面来说,由于我们采用相对熵编解码REC来进行熵编解码,所以在解码端我们的方法能取得非常快的解码速度,我们统计了实际的编解码时间如下表所示。


从上面两个表格可以看出来,我们提出的COMBINER方法编码时间较长,但是解码时间可以非常的短。考虑到COMBINER是第一个可以支持隐式表征压缩率失真联合优化的探索性框架,我们希望也相信未来会有一些后续进展可以弥补编码时间较长的问题。
结论
在本文中,我们提出了COMBINER,一种新型的神经网络压缩方法。它首先将数据编码为变分贝叶斯隐式神经表示(INR),然后通过相对熵编码传递近似后验权重样本。与之前的基于INR的神经编解码器不同,COMBINER支持联合率失真优化,因此可以适应性地激活和剪枝网络参数。此外,我们还引入了一种迭代算法,用于学习网络权重的先验参数并逐步精细化变分后验。这些方法显著提高了COMBINER的率失真性能。特别是,COMBINER在低分辨率和高分辨率的图像及音频压缩方面都实现了强大的性能,展示了其在不同数据模态和场景下的应用潜力。
然而,正如我们原文中所讨论的,COMBINER也存在一些局限性。首先,尽管解码过程快速,但编码时间相对较长。优化变分后验分布需要数千次迭代,而逐步微调这些分布也非常耗时。其次,贝叶斯神经网络在本质上对初始化非常敏感。为了实现训练稳定性和优越的率失真性能,确定最佳初始化设置可能需要大量努力。尽管存在这些挑战,我们相信COMBINER为INR压缩的联合率失真优化铺平了道路。
参考文献:
[1] Compression with Implicit Neural Representations. Dupont et al., ICLR 2021 workshop.
[2] Fast Relative Entropy Coding with A* Coding. Flamich et al., ICML 2022.
[3] Joint Autoregressive and Hierarchical Priors for Learned Image Compression. Minnel et al., NeurIPS 2018.
论文地址:https://arxiv.org/pdf/2305.19185.pdf
【内容提供】 郭宗昱
【单位】中国科学技术大学智能媒体计算实验室
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。