
基于文本的扩散模型在生成和编辑方面取得了显著的成功,显示出利用扩散模型先验生成性增强视觉内容的巨大前景。然而,由于对输出保真度和时间一致性的高要求,将扩散模型应用于视频超分辨率仍具有挑战性。本工作提出了 Upscale-A-Video,利用文本引导的潜在扩散框架,用于视频超分。该框架通过局部和全局机制确保时序一致性。由于采用了扩散先验,本模型还提供了更大的灵活性,允许文本提示来引导纹理创建,以及可调节的噪声水平来平衡修复和生成,从而实现保真度和质量之间的权衡。
来源:arxiv
作者:Shangchen Zhou 等
论文题目:HUpscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution
论文链接:https://arxiv.org/pdf/2312.06640.pdf
项目主页:https://shangchenzhou.com/projects/upscale-a-video
内容整理:汪奕文
引言
真实世界场景中的视频超分辨率(VSR)是一项具有挑战性的任务,其目的是提高低质量视频的质量,从而产生高质量的结果。
虽然最近基于卷积神经网络(CNN)的网络在减轻多种形式的退化方面取得了成功,但由于其生成能力有限,在生成逼真的纹理和细节方面仍有不足,经常导致过度平滑。
扩散模型在生成高质量图像和视频方面表现出令人印象深刻的能力。利用扩散模型的生成潜力,可以有效地缓解基于 CNN 的模型中经常出现的过度平滑问题,得到的结果具有更逼真的细粒度细节。然而,将这些扩散先验适应于 VSR 仍然是一个非同小可的挑战。这种困难源于扩散采样固有的随机性,它不可避免地会在生成的视频中引入意想不到的时间不连续性。这一问题在 SD 中更为明显,VAE 解码器会进一步引入纹理细节的闪烁。
最近,人们通过引入时间一致性策略,使图像扩散模型适用于视频任务,这些策略包括
- 利用 3D 卷积和时空注意力等对视频模型进行微调;
- 在预训练模型中采用跨帧注意力和光流引导的注意力等 zero-shot 机制。
虽然这些解决方案大大提高了视频的稳定性,但仍存在两个主要问题:
- 目前在 U-Net 空间或隐空间中操作的方法难以保持低层次的一致性,纹理闪烁等问题依然存在;
- 现有的时间层和注意力机制只能对较短的局部输入序列施加约束,从而限制了它们在长视频中保证全局时间一致性的能力。


为了解决这些问题,本方法采用了一种局部-全局策略来保持视频重建中的时间一致性,同时关注细粒度纹理和整体一致性。此外,本方法进一步研究了如何通过文本提示指导纹理创建来提高多功能性,并提供了对噪声水平的控制来平衡修复和生成,从而实现保真度和质量之间的权衡。
方法
本方法的目标是针对真实世界 VSR 开发一个文本引导的扩散框架。其挑战包括时间不一致性和闪烁伪影的出现,尤其是对于长视频序列的 VSR 任务。这些任务的复杂性不仅在于实现局部片段的时间一致性,还在于保持整个视频的一致性。
本方法的框架在潜在扩散模型(LDM)中加入了局部和全局模块,以保持视频片段内和视频片段间的时间一致性。在每个扩散时间步长 (t = 1,2,…,T) 内,视频会被分割成不同的片段,并用 U-Net 进行处理,U-Net 包括时间层,以确保每个片段内的一致性。如果当前时间步长在用户指定的全局细化步长 T* 范围内,则会使用循环潜码传播模块来提高推理过程中各视频片段之间的一致性。最后,微调 VAE 解码器用于减少剩余的闪烁伪影。
由于采用了扩散先验,本方法具有显著的多功能性:
- 输入文本提示可以进一步提高视频质量,改善逼真度和细节。
- 用户指定的噪声水平可控制质量和保真度之间的权衡。
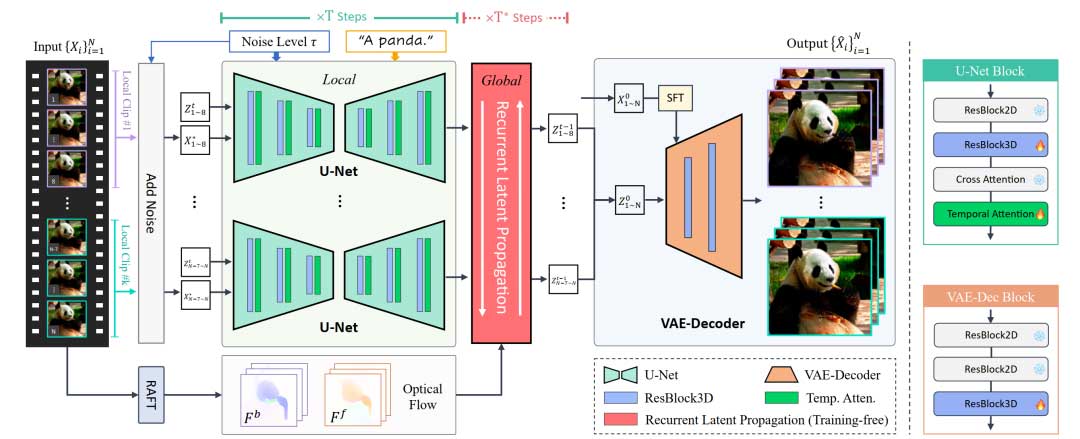
扩散模型先验
预训练的 SD 图像超分
Upscale-A-Video 建立在预训练的文本引导 SD 图像超分之上。
扩张 2D 卷积
在将预训练的 2D 扩散模型应用于视频任务时,通常会将其 2D 卷积扩张为 3D 卷积。在扩散模型中加入新的时间层,使其能够捕捉和编码预训练模型中的时间信息。
为了处理视频数据,本方法首先通过将预训练模型中的 2D 卷积扩张为 3D 卷积来修改网络结构,然后用它初始化网络。本方法的目标是将从图像超分中学到的知识迁移到视频超分中,从而实现更高效的训练。
视频片段内局部一致性
微调 U-Net
本方法在预训练图像超分模型中引入了额外的时间层,以实现视频片段内的局部一致性约束。在修改后的时间 U-Net 中,选择时间注意力和基于 3D 卷积的 3D 残差块作为时间层,并将它们插入预训练的空间层中。时空注意层沿时空维度执行自我注意,并关注所有局部帧。此外,本方法还在时间层中添加了旋转位置嵌入(RoPE),为模型提供时间位置信息。
重要的是,本方法在训练过程中保持预训练的空间层固定不变,仅插入的时间层进行优化。这种训练策略的好处是可以利用从大量高质量图像数据集中学习到的预训练空间层。
微调VAE Decoder
即使在视频数据上对 U-Net 进行了微调,LDM 框架内的 VAE-Decoder 在解码时仍会产生闪烁伪影。为了缓解这一问题,本方法在 VAE-Decoder 中引入了额外的时空 3D 残差块,以增强低层次的一致性。
此外,U-Net 中的扩散去噪过程经常会引入色彩偏移。为了解决这个问题,本方法在输入视频中加入了空间特征变换层(SFT),利用输入视频来变换 VAE 解码器第一层的特征。这允许输入视频提供颜色等低频信息,以加强输出结果的颜色保真度。
与时间 U-Net 的训练类似,保持预训练的空间层不变,只训练新添加的时间层。这些时间层使用混合损失对视频数据进行训练,包括 L1 损失、LPIPS 感知损失和时间 PatchGAN 判别器的对抗损失。
视频片段间全局一致性
LDM 中的时间层仅限于处理局部序列,因此无法在视频片段之间的全局一致性约束。之前的研究已经展示了光流引导的长期传播在视频增强任务的时间一致性方面的优势。
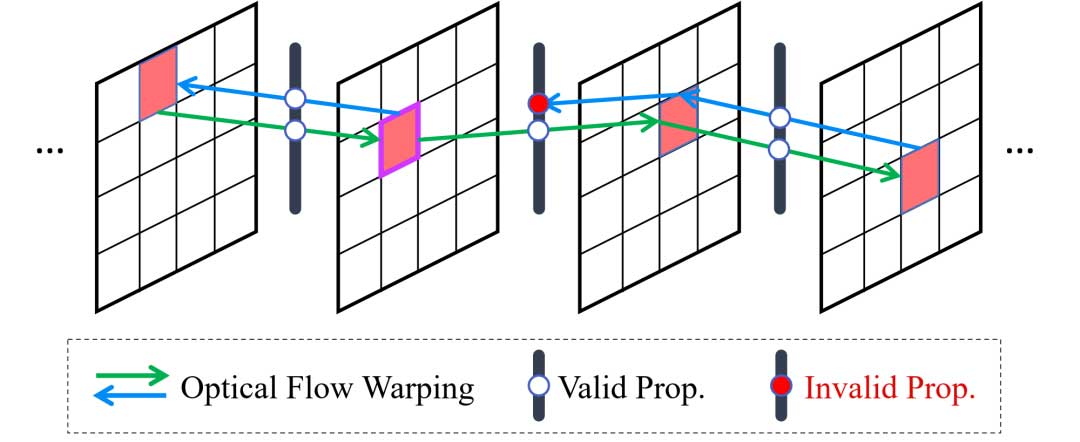
循环潜码传播
本方法在隐空间中引入了一个免训练的光流引导的循环传播模块。该模块可确保长输入视频的全局时空一致性,涉及前向和后向的双向传播。
对于输入的低分辨率视频,本方法首先采用 RAFT 来估计光流,其分辨率与隐空间特征的分辨率完全匹配,因此无需调整大小。然后,通过评估前后一致性误差来检查估计光流的有效性。

在推理过程中,不是在每个扩散步骤中都应用该模块,而是金对于用户选择的 T* 步进行循环潜码传播和聚合。在处理轻微的视频抖动时,可以选择在扩散去噪过程的早期集成该模块,而对于严重的视频抖动(如 AIGC 视频),最好在去噪过程的后期执行该模块。
附加条件推理过程
本方法可以进一步调整 Upscale-A-Video 中的文本提示和噪声水平等附加条件,以约束扩散去噪过程。文字提示可以引导生成纹理细节,如动物皮毛或油画笔触。此外,通过调整噪声水平,可以平衡模型的还原和生成能力,数值越小越有利于还原,数值越大越有利于生成更多细节。在推理过程中,本方法还采用了无分类指导(CFG),可以显著增强文本提示和噪声水平的影响,帮助生成具有更多细节的高质量视频。
实验
数据集和实验细节
训练集本方法使用以下数据集训练我们的 Upscale-A-Video 模型:
- WebVid10M子集,包含约 335K 个视频-文本对,每个分辨率约为 336 x 596,常用于训练视频扩散模型;
- YouHQ 数据集。由于缺乏用于训练的高质量视频数据,本方法另外从 YouTube 上收集了一个大规模的高清(1080 x 1920)数据集,其中包含约 37K 个视频片段,场景多种多样,如街景、风景、动物、人脸、静态物体、水下和夜景等。按照 RealBasicVSR 的退化方法,生成 LQ-HQ 视频对进行训练。
测试集在合成测试数据集方面,本方法构建了四个合成数据集(即 SPMCS、UDM10 、REDS30 和 YouHQ40),这些数据集在训练中采用相同的退化方法生成相应的 LQ 视频。此外,本方法还在真实世界数据集 (VideoLQ) 和 AIGC 数据集 (AIGC30) 上对模型进行了评估。
训练细节
Upscale-A-Video 在 32 张 A100 80G GPU 上进行训练,批量大小为 384。训练数据裁剪为 80 x 80,长度为 8。
使用 Adam 优化器,lr 设置为 1 x 10-4。首先在 WebVid10M 和 YouHQ 上对 U-Net 模型进行 70K 次迭代训练。然后,仅在 YouHQ 上再训练 10K 次迭代。由于 YouHQ 没有文本提示,因此在训练中使用空提示。这样,本模型既可以处理具有 LQ 输入和提示的 VSR,也可以处理只有 LQ 输入的 VSR,从而在实际应用中更加灵活。至于 VAE-Decoder 的微调,本方法遵循 StableSR,首先在 WebVid10M 和 YouHQ 上生成 100K 个合成的 LQ-HQ 视频对,然后采用微调后的 U-Net 模型为 LQ 视频生成相应的隐空间特征。
评估指标
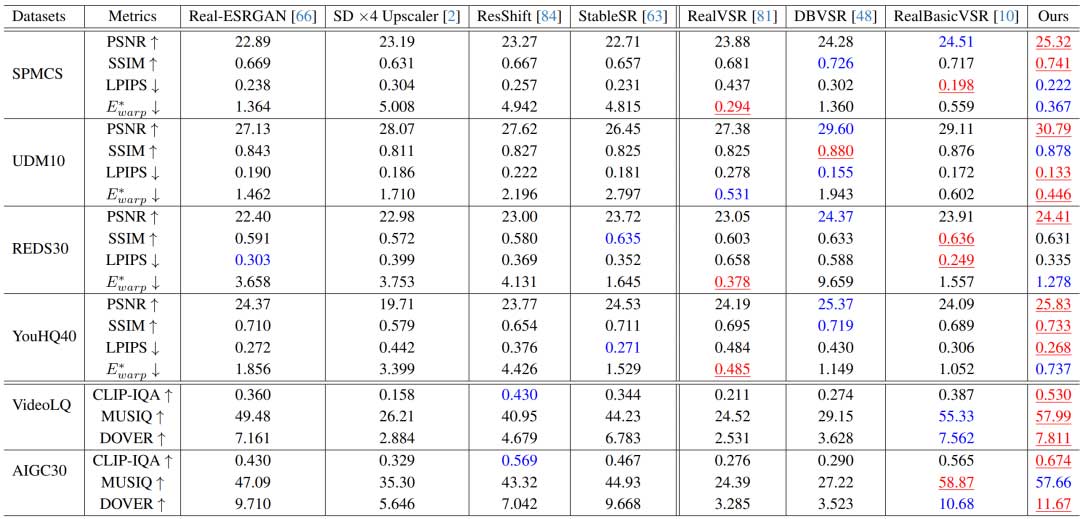
本方法采用不同的指标来评估生成结果的帧质量和时间一致性。对于具有 LQ-HQ 对的合成数据集,采用 PSNR、SSIM、LPIPS 和 flowwarping error E*warp 进行评估。对于真实世界和 AIGC 测试数据,由于没有 GT 视频,采用常用的非参考指标进行评估,即 CLIP-IQA、MUSIQ 和 DOVER。
定量和定性比较
定性比较
下图分别为合成视频和真实世界视频的超分结果。可以看出,Upscale-A-Video 在去除伪影和生成细节方面明显优于现有的基于 CNN 和扩散的方法。
Upscale-A-Video 有效地利用了扩散先验在生成高质量结果方面的优势。与下图中的其他方法相比,Upscale-A-Video 能够生成更多考拉的自然细节。

与现有方法相比,Upscale-A-Video 在恢复能力方面表现突出,成功恢复了广告牌上的单词 “EAT IN or TAKEAWAY”,而其他方法则会生成模糊或扭曲的结果。尤其是在文本提示的引导下,Upscale-A-Video 可以展示出具有更多细节和更高真实度的增强效果。

定量比较
Upscale-A-Video 在所有四个合成数据集上都获得了最高的 PSNR,这表明它具有出色的重建能力。此外,在 UDM10 和 YouHQ40 上都获得了最低的 LPIPS 分数,这表明我们生成的结果具有很高的感知质量。
除了在合成视频上的良好表现,Upscale-A-Video 在真实数据集和 AIGC 视频上也获得了最高的 CLIP-IQA 和 DOVER 分数。在不同来源的数据集上都取得了优异的成绩,这证明了本方法是有效的。
时间一致性
由于本方法的局部-全局时间策略,Upscale-A-Video 在 UDM10 上获得了最佳优化光流误差分数,在 REDS30、SPMCS 和 YouHQ40 上获得了次佳分数,显著优于其他基于扩散的方法,甚至击败了基于 CNN 的 VSR 方法。
通过下图直观的时间曲线可以看出,本方法实现了更出色的性能,过渡更无缝、更平滑。

消融性实验
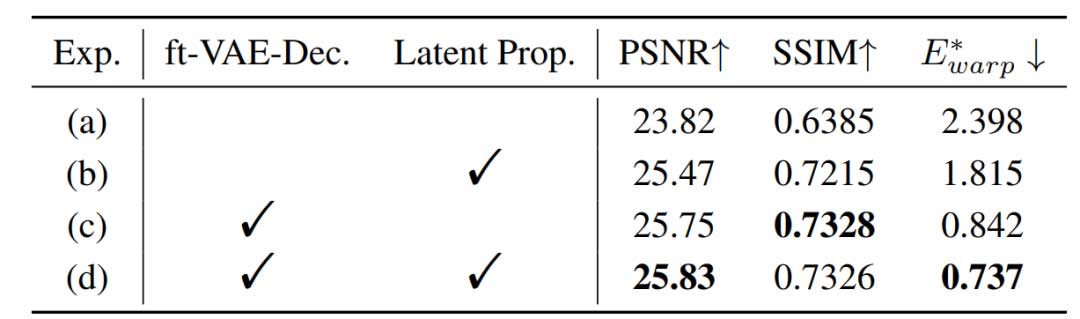
微调 VAE 解码器的有效性
首先研究了微调 VAE 解码器的重要性。用原始解码器替换我们的微调 VAE 解码器会导致更差的 PSNR、SSIM 和 E*warp。特别是,E*warp 从 0.737 增加到 1.815,表明时间一致性显著恶化。
循环传播模块的有效性
除了对 VAE-Decoder 进行微调外,光流引导的循环传播模块进一步增强了长视频的稳定性。采用传播模块可以进一步降低 E*warp 误差,在保持高 PSNR 的同时有效提高时间一致性。
文本提示
Upscale-A-Video 是在带有文本提示或空提示的视频数据上进行训练的,因此可以处理这两种情况。本方法研究了使用无分类器引导来改善采样期间的视觉质量。与空提示相比,采用适当的文本提示可以显著提高感知质量,使细节更加忠实。

噪声水平
据观察,输入中添加的噪声水平会影响我们方法的性能。当噪声水平较低时,生成的结果往往不够理想,细节模糊不清。但是,噪声水平过大可能会导致过度锐化。
结论
虽然扩散模型在各种图像任务中都取得了令人印象深刻的性能,但它们在视频任务中的应用,尤其是在真实世界的 VSR 中的应用,仍然具有挑战性且研究不足。在本文中,提出了 UpscaleA-Video 模型,这是一种利用图像扩散先验进行真实世界 VSR 的新方法,同时避免了采样过程中固有随机性带来的时间不连续性。具体来说,我们在 SD 框架内提出了一种新颖的局部-全局时间策略,从而增强了时间一致性。此外,还通过文本提示和噪声水平控制来实现纹理创建,在保真度和质量之间实现权衡,从而进一步促进在现实世界场景中的实际应用。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。