
本工作是由上海交通大学宋利教授带领的 Medialab 实验室与华为诺亚实验室合作产出,并被 ECCV2022 录用。该工作提出了一种利用视频的编解码信息来提升压缩视频超分辨率算法效率的框架。该框架重用运动向量(Motion Vector)建模相邻帧之间的时间关系,以此来代替目前视频超分辨率算法中复杂的运动估计。其次,通过进一步利用残差(Residuals)信息来指导稀疏卷积跳过对冗余像素的计算,节省运算量。实验证明通过重用运动向量和残差信息可以有效的提高压缩视频超分辨率算法的效率。
背景
目前网络上的电影、网络广播、自媒体视频等大部分是分辨率较低的压缩视频,而智能手机、平板电脑、电视等终端设备正逐渐配备 2K、4K 甚至 8K 清晰度的屏幕,因此端侧的视频超分辨率(VSR)算法引起越来越广泛的关注。与图像超分辨率(SISR)相比,视频超分辨率(VSR)可以通过沿视频时间维度利用邻近帧的信息来提高超分辨率的效果。视频超分辨率算法大致可以分为两类:基于滑窗的视频超分算法(Sliding-window)和基于循环神经网络的视频超分算法(Recurrent VSR)。基于滑窗的视频超分算法会重复的提取邻近帧的特征,而基于循环神经网络的视频超分辨率算法避免了重复的特征提取,还可以高效的传递长期时间依赖信息,鉴于端侧运算单元和内存有限的情况来说是一个更具潜力的方案。在视频超分中,视频帧之间的对齐对超分辨率性能有着重要的影响。目前的视频超分算法通过光流估计、可形变卷积、注意力和相关性机制等方式来设计复杂的运动估计网络来提升视频超分的性能。而目前商用终端设备很难为视频超分辨率算法提供足够的计算单元和内存来支撑视频帧之间复杂的运动估计以及大量的冗余特征计算。
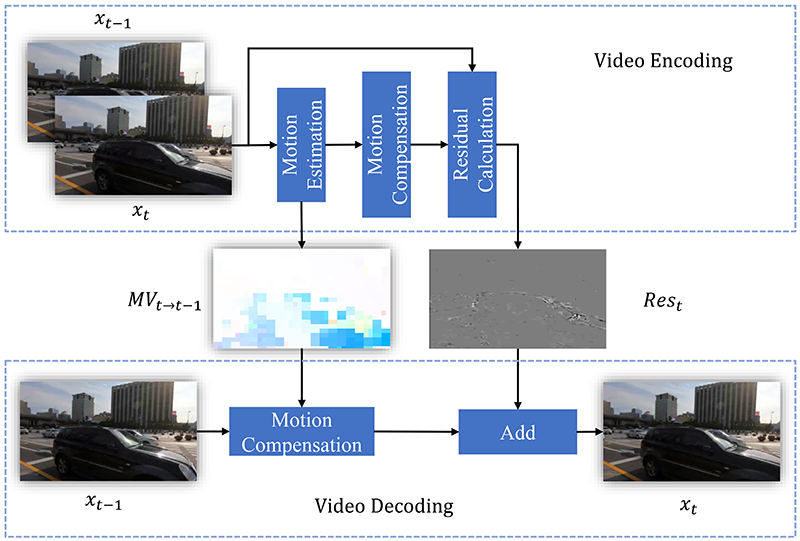

另一方面,与原始视频相比,压缩视频具有一些不同的特点。如图1-1所示,在视频编码时,当前帧与参考帧(例如前一帧)的运动关系被计算为运动矢量。然后根据运动矢量扭曲参考帧以获得预测的当前帧。预测的当前帧与真实当前帧之间的差异计算为残差。运动矢量和残差是编码在视频流中,运动矢量提供视频帧的运动线索,残差表示帧之间的运动补偿差异。解码时,我们首先使用解码后的参考帧和运动矢量生成预测图像,然后我们将解码后的残差添加到预测图像中获取目标帧。很明显,这些信息对视频超分有潜在的帮助。而目前的视频超分辨率算法大多没有考虑视频的压缩特性,将视频超分辨率作为视频解码后的后处理。而本文通过重用压缩视频中的运动矢量和残差信息来提升视频超分辨率算法的效率,来实现端侧的视频超分。
方法
本文提出的编解码信息辅助的高效压缩视频超分辨率算法框架包含两部分,基于运动矢量的对齐模块和残差指示的稀疏处理。由于我们旨在设计高效的在线视频超分框架,因此我们主要针对单向基于循环神经网络的视频超分(Unidirectional recurrent VSR)模型提升效率,双向信息传播网络(Bidirectional propagation)或者更复杂的网格信息传播网络(grid propagation)不适合设计高效的在线视频超分模型。
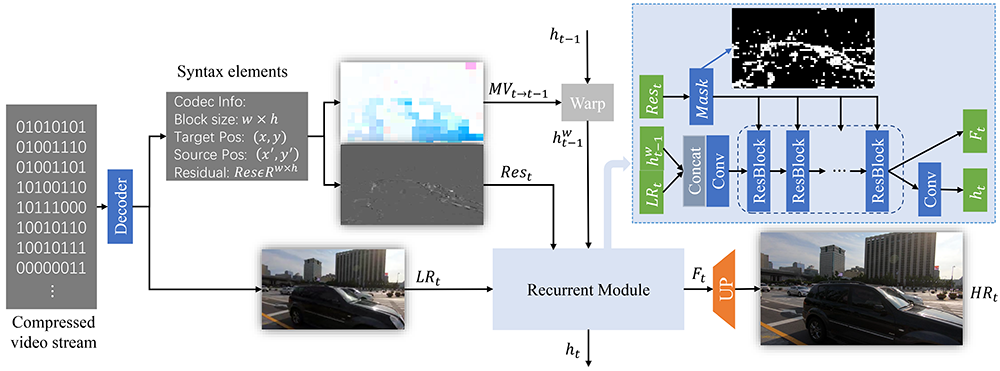
基于运动矢量的对齐模块
在视频超分辨率算法中,相邻帧之间的对齐对性能有着重要的影响。在本文中,我们用运动矢量扭曲上一帧的高分辨率信息来与当前帧对齐。与 H.264 中使用的插值滤波器不同,如果运动矢量不是整数,本文利用双线性插值滤波器以提高效率。当前后帧编码块之间没有很高的时间相关性时,视频编码器使用帧内预测模式。由于帧内块主要出现在关键帧(视频片段的第一帧)中,并且大多数帧中的帧内预测块很少,因此对于帧内预测的块,我们直接将上一帧相同位置的特征转移到当前帧中。因此,我们为帧内编码块设置运动矢量MV =(0,0) 。我们可以像光流一样设置大小为 H x W x 2 的运动场 MV,H 和 W 分别是输入低分辨率帧的高度和宽度,第三维用来指示当前帧和上一帧宽度方向和高度方向的相对位置。所以运动矢量是光流的近似替代。通过这样,我们绕过了复杂的运动估计。基于运动矢量的对齐可以提高现有的基于单向循环神经网络的视频超分辨率模型的性能,甚至可以达到与基于光流的对齐相当的性能。
残差指示的稀疏处理
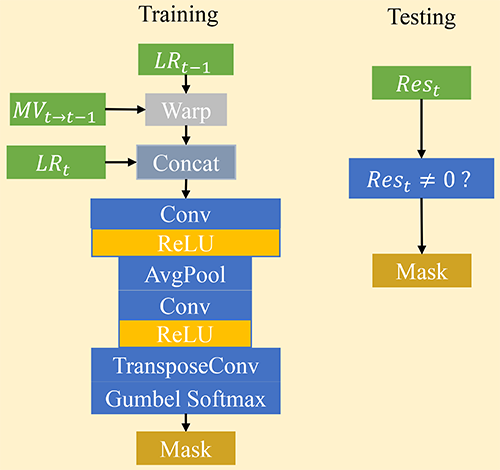
在本文中,我们设计了一个残差指示的稀疏处理框架来减少冗余计算。残差代表了根据运动矢量扭曲的上一帧和当前帧之间的差异。没有残差的区域表示当前区域可以通过共享来自参考帧的相应补丁来直接预测。因此,残差可以定位需要进一步增强的区域。在残差的指导下,我们只对重要的像素进行卷积,其余像素的特征通过与上一帧根据运动矢量扭曲后的特征进行聚合来增强。如图2-1所示,我们对网络的主体(Resblocks)采用这种稀疏处理,头部和尾部卷积层应用于所有像素。
得益于运动估计和运动补偿,我们可以很容易地根据相邻帧的内容预测当前帧平坦区域或具有规则结构区域的内容而不引入残差,而复杂的纹理区域更容易产生残差。因为平坦区域或具有规则结构区域占据了视频帧的大部分区域,所以残差在大多数场景中都很稀疏。基于这些特点,本文提出的基于残差指示的稀疏处理可以显着减少时空冗余计算,同时保持与基线模型相当的性能。


实验结果
论文采用 REDS 数据集进行训练,在 REDS4 和 Vid 数据集上进行测试。所有帧首先由标准差为 1.5 的高斯核平滑并下采样为原来的 1/4。由于我们的框架是为压缩视频设计的,我们使用最常见的视频编解码器 H.264 在不同的 CRF 值下对数据集进行编码。H.264 中推荐的 CRF 值在 18 到 28 之间,默认值为 23。在实验中,我们将 CRF 值设置为 18、23 和 28,并使用 FFmpeg 编码器对数据集进行编码。
基于运动矢量的对齐效果
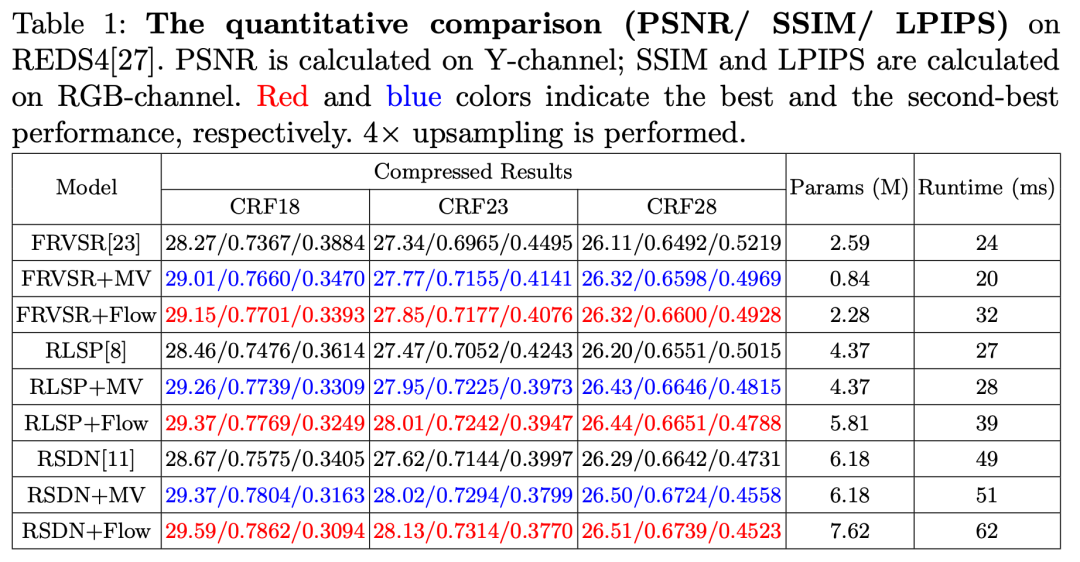
我们将基于运动矢量的对齐和基于光流的对齐应用到现有模型 FRVSR[1]、RLSP[2] 和 RSDN[3] 以验证我们基于运动矢量的对齐的效果。我们采用 SpyNet 作为光流预测模型。原始 FRVSR 有一个光流对齐子模块来进行对齐,我们将其替换为运动矢量对齐和 SpyNet 光流对齐。我们可以看到 SpyNet 对齐的 FRVSR 模型性能超过了原始 FRVSR,这是因为 SpyNet 相比原始 FRVSR 的光流子网络能够更加准确的预测光流。原始 RLSP 和 RSDN 没有显式对齐模块,我们为其添加了运动矢量对齐和 SpyNet 光流对齐来评估不同对齐方式的效果。我们发现添加了对齐模块的 RLSP 和 RSDN 模型相比原始模型性能得到很大提升,证明了帧间对齐对视频超分的重要性。我们发现基于运动矢量的对齐模块几乎可以达到和光流对齐相当的性能,并且没有引入新的参数,省去了运动估计的时间,显著提升了帧间对齐的效率。下图展示了主观对比效果。可以看到基于运动矢量的对齐达到了和光流相当的效果,并且显著好于原始基线模型。

残差指导的稀疏处理效果
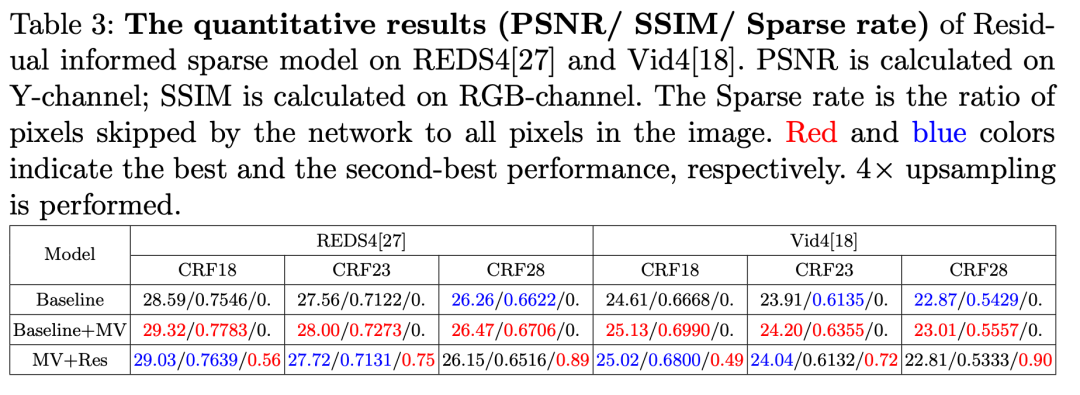
我们在基于运动矢量对齐的模型基础上进一步利用基于残差的稀疏处理来降低冗余计算。上表中,Baseline 是我们设置的基线模型,类似图2-1,基线是一个类似 RLSP 和 RSDN 的基于单向循环神经网络的视频超分网络,其没有显式的对齐模块。Baseline+MV 是在基线上添加了运动矢量对齐模块,而 MV+Res 是结合了运动矢量对齐和基于残差的稀疏处理的模型。可以看到结合了运动矢量对齐和基于残差的稀疏处理模型可以跳过许多像素的计算而性能在大多数情况下仍然好于基线模型。在 CRF 为 28 时,由于残差非常稀疏,参与运算的像素很少,但是其性能仍与基线模型相当。图3-2展示了 CRF 为 23 时的主观效果对比,可以看到结合了基于残差的稀疏处理模型可以实现比基线更好的效果,但是其运算量比基线少得多。

结论
本文提出重用压缩视频中的编解码器信息来辅助视频超分辨率任务。我们使用运动矢量来高效对齐单向基于循环神经网络的视频超分辨率系统中的前后帧。实验表明基于运动矢量的对齐可以显著提高性能,只引入了忽略不计的额外计算,它甚至达到了与基于光流的对齐相当的性能。为了进一步提高视频超分辨率模型的效率,我们从压缩视频中提取残差并设计残差指导的稀疏处理。结合基于运动矢量的对齐方式,我们的残差指导的稀疏处理可以精确定位需要计算的区域并跳过不重要的区域以节省计算。实验表明我们的稀疏模型仍然优于基线模型或者与基线模型相当。此外,鉴于运动信息对于视频底层视觉任务的重要性和固有的视频时间冗余,我们的编解码器信息辅助框架具有应用于其他任务例如压缩视频增强和去噪的潜力。
参考文献
[1] Vemulapalli R, Brown M, Sajjadi S M M. Frame-recurrent video super-resolution: arXiv, 10.1109/CVPR.2018.00693[P]. 2020.
[2] Fuoli D , Gu S , Timofte R . Efficient Video Super-Resolution through Recurrent Latent Space Propagation[C]// 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). IEEE, 2019.
[3] Isobe T, Jia X, Gu S, et al. Video Super-Resolution with Recurrent Structure-Detail Network[J]. 2020.
论文标题:A Codec Information Assisted Framework for Efficient Compressed Video Super-Resolution
发表会议:ECCV 2022
作者:Hengsheng Zhang,Xueyi Zou,Jiaming Guo,Youliang Yan,Rong Xie and Li Song
论文链接:https://arxiv.org/pdf/2210.08229.pdf
来源:媒矿工厂。倡导极客、创客精神,促进学术界、工业界以及开源社区共享信息、交流干货、发掘价值。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。