
简介:神经辐射场(NeRF)学习时数据包含不在图像拍摄期间持续存在的干扰物(如移动物体、光照变化、阴影)时,会出现伪影。为了处理这些干扰物,本工作提出一种用于NeRF训练的鲁棒性估计,将训练数据中的干扰物建模为优化问题的离群值。我们的方法成功地从场景中去除了离群值,并在合成和真实场景上改进了目前NeRF方法的结果。本方法只需很少的超参数就能加入到各种类型的NeRF算法中。
来源:CVPR2023
项目链接:https://robustnerf.github.io/
作者:Sara Sabour, Suhani Vora, Daniel Duckworth, Ivan Krasin, David J. Fleet, Andrea Tagliasacchi
内容整理:陈梓煜
介绍
尽管NeRF在新视角合成方面表现出色并且方法直接,但它隐藏了一些假设。由于模型通常是为了最小化在RGB颜色空间中的误差而训练的,因此图像的光照一致性非常重要——从相同视角拍摄的两张照片应该是相同的,除了噪声。应该手动保持相机的焦点、曝光、白平衡和ISO固定。


然而,正确配置相机并不是捕捉高质量NeRF的全部要求,还有一个重要的要求是避免干扰物:即在整个捕捉过程中并不持续存在的任何干扰物体。干扰物以多种形式出现,从拍摄者影子,到突然出现的宠物等。手动去除干扰物是繁琐的,需要逐像素的标记。检测干扰物也很繁琐,因为典型的NeRF场景是从数百张输入图像中训练的,而干扰物的类型事先是未知的。如果忽略干扰物,重建场景的质量会显著降低,如图1。
在通常使用的nerf数据中,一个场景往往无法从同一视角捕捉多幅图像,这使得数学建模干扰物变得困难。更具体地说,虽然视角相关效应(View-Dependent)是使NeRF看起来逼真的因素,但模型如何区分干扰物和视角相关效果呢?
尽管存在挑战,研究界已经设计了几种方法来克服这个问题:
- 如果已知干扰物属于特定类别(例如人),可以使用预训练的语义分割模型将其去除,这个过程不适用于“意外”干扰物,如阴影。
- 可以将干扰物建模为每张图像的瞬时的现象,并控制瞬时/永久建模的平衡,就像NeRF in the wild一样处理,但是这个优化问题是困难的。
- 可以将数据建模为时间(即高帧率视频)并将场景分解为静态和动态(即干扰物)两部分,但这显然仅适用于视频捕捉而不是照片收集捕捉。
相反,本工作通过将它们建模为NeRF优化中的离群值来解决干扰物问题。我们从鲁棒性估计的角度进行了分析,从而能理解干扰物的特征,并设计出一种不仅可以简单实现,而且更有效的方法,需要很少或不需要超参数调整,并实现了SOTA的性能。
方法
传统的NeRF训练损失在捕获光照一致的场景方面非常有效,然而,当场景中存在不在整个拍摄场景中持续存在的元素时会发生什么?这种场景的简单示例包括只在某些观察图像的一部分中存在的对象,或者可能不在所有观察图像中的相同位置。例如,图2描绘了一个包含持久对象(卡车)以及几个瞬时对象(如人和狗)的2D场景。尽管来自三台相机的蓝色光线与卡车相交,但来自相机1和3的绿色和橙色光线与瞬时对象相交。对于视频捕捉和时空NeRF模型,持久对象组成了场景的“静态”部分,而其余部分被称为“动态”。
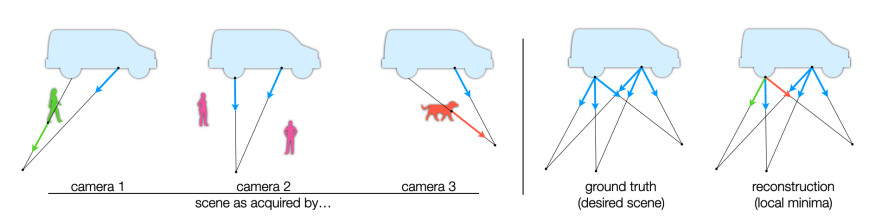
对离群值的敏感性
对于Lambertian场景,光照一致的结构是视角无关的,因为场景辐射仅取决于入射光线。对于这种场景,视角相关NeRF模型,通过最小化RGB L2 Loss进行训练,可以产生解释瞬时对象的局部最优解。图2右解释了这一点,出射颜色对应于离群值的记忆颜色——即视角相关颜色。这种模型利用模型的视角相关容量来过拟合训练数据,有效地记忆瞬时对象。可以改变模型以消除对d的依赖性,但L2损失仍然有问题,因为最小二乘(LS)估计对离群值或重尾噪声分布敏感。
在更自然的条件下,放弃Lambertian假设,问题变得更加复杂,因为非Lambertian反射现象和离群值d都可以被解释为视角相关辐射。虽然我们希望模型能够捕捉光照一致的视角相关辐射,但理想情况下,离群值和其他瞬时现象应该被忽略。在这种情况下,使用L2损失进行优化会导致重建中出现明显的错误,如图1 MipNeRF360所示。这种问题在NeRF模型拟合中普遍存在,特别是在不受控的环境中,具有复杂的反射、非刚性或独立运动的物体。
对离群值的鲁棒性
通过语义分割实现的鲁棒性
在NeRF模型优化期间减少离群值污染的一种方法是依赖于一个Mask,该Mask指定给定像素是否为离群值,并且不计算该像素的Loss,在实际应用中,可以使用一个预训练的语义分割网络提供mask。例如,NeRF in the Wild使用语义分割模型来删除被人占据的像素,因为在旅游照片数据集中,短暂存在的人群为离群值。Urban Radiance Fields分割了天空像素,这种方法的明显问题在于需要一个可以检测任意干扰物的分割网络。
Robust Loss
本文提出了一种用于NeRF模型拟合的带有修剪最小二乘(LS)损失的迭代重新加权最小二乘(IRLS)形式,如图3所示。

IRLS是一种广泛使用的用于鲁棒性估计的方法,它涉及求解一系列加权最小二乘问题,这些问题的权重根据逐渐减小离群值的影响而调整。但是为NeRF优化选择合适的权重函数(即Kernel函数,权重函数)是不容易的,这主要是因为视角相关辐射现象与离群值之间的相似性。一个可能的方法是通过学习神经网络权重函数来解决这个问题,但是生成足够的标注训练数据比较困难。相反,本文所提出的Kerner函数利用离群值结构中的先验,利用了修剪最小二乘估计的简洁,便达到了目标效果。
Robust Kernel
RobustNeRF提出一种用于迭代加权最小二乘优化的权重函数(图3),能既简单又捕获了用于NeRF优化的有用归纳误差。为了简单起见,RobustNeRF选择了一种具有直观参数的二进制权重函数,它在模型拟合过程中自然地适应,以便快速学习非离群值的细粒度图像细节。Robust Kernel捕获了典型离群值的结构化性质,根据结构先验,干扰物通常具有局部连续性,因此离群值预计占据图像的大块连续区域(例如,从旅游照片数据集中分割出一个人的轮廓)。
实验
与Mip-NeRF 360比较
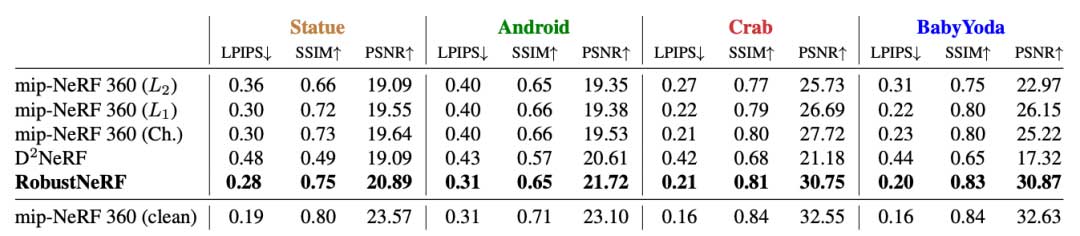
在自然场景中,RobustNeRF通常比MipNeRF360的变体在PSNR上高出1.3到4.7 dB。由于L2、L1和Charbonnier损失同等对待所有像素,MipNeRF360被迫将干扰物表示为具有视角相关外观的“云”而不是忽略它们。我们发现当干扰物在多个帧中保持静止时,云最为明显。相比之下,RobustNeRF的损失将干扰物像素隔离出来,并将它们的权重设为零。为了确定重建准确性的上限,我们使用Charbonnier损失在每个场景的不包含干扰物的版本上训练MipNeRF360,这些图像从(大致)相同的视角拍摄。RobustNeRF在训练没有干扰物的帧时,实现了几乎相同的性能,见图4。

与D2NeRF比较
定量上,RobustNeRF与D2NeRF相当,具体取决于场景中离群的对象数量。在Statue和Android中,分别移动了一个和三个非刚性对象。D2NeRF能够对这些对象进行建模,因此可以将它们与场景的静态内容分开。在其余的场景中,使用了更多干扰物体,包含100到150个唯一的非静态对象——这对于D2NeRF来说太多了,无法有效地建模。因此,在其静态表示中出现了伪影,类似于MipNeRF360产生的伪影。相比之下,RobustNeRF将非静态内容识别为离群值,并在重建过程中省略它。尽管这两种方法使用了类似数量的参数,但D2NeRF的内存使用峰值比RobustNeRF高2.3倍,而在批处理大小归一化时高出37倍。这是模型结构差异的直接结果D2NeRF专门用于同时建模静态和动态内容,因此具有更高的复杂性。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。