
本次分享由库比蒂诺高中和纽约州立大学布法罗分校联合投稿在CVPR 2023的一篇论文:《Integrating Audio-Visual Features for Multimodal Deepfake Detection》。该工作提出了一种基于音视频的深度伪造检测方法,结合了每个单一模态的特征,将样本分类为四种类型;并提出了一种细粒度的深度伪造识别模块,以指导检测模型识别视频中的单一模态或多模态伪造的不同特征。
论文地址:https://arxiv.org/pdf/2310.03827.pdf
0 Abstract
Deepfakes是指通过人工智能生成的媒体,其中图像或视频已经进行了数字修改。深度伪造技术的进步导致了隐私和安全问题。大多数深度伪造检测技术依赖于对单一模态的检测。现有的音视频检测方法并不总是优于基于单一模态的分析。因此,本文提出了一种基于音视频的深度伪造检测方法,将精细粒度的深度伪造识别与二进制分类相结合。我们通过结合每个单一模态的特定标签,将样本分为四种类型。这种方法增强了在域内和跨域测试中的检测能力。
1 Introduction
Deepfakes(深度伪造)是一种合成媒体,可以通过各种方式对图像、视频和音频记录进行改变和伪造。它们涉及使用生成对抗网络(GANs)[1]、自编码器[2]、扩散模型[3]和其他机器学习算法来创建。这些算法的迅速发展使得创造这种合成视频的过程变得越来越容易和快速。最著名的深度伪造形式涉及生成一个视频,其中一个人的脸被替换成另一个人的身体。这创造了一个令人信服的幻觉,让使用某人的脸的人看起来是在视频中扮演角色的人。这项技术在各个行业中找到了实际应用,特别是在娱乐领域,包括电影制作和视频游戏制作。
然而,与此同时,深度伪造技术也可以轻松用于恶意目的,对媒体安全和信息认证的完整性构成重大威胁。例如,通过使用虚假和盗用的身份信息开设银行账户,发生了金融欺诈行为。2021年,银行劫匪使用人工智能克隆声音,从阿联酋银行中窃取了3500万美元。然而,关于深度伪造的主要担忧集中在误导信息的传播和不当内容的制作上。2022年,一段深度伪造视频中乌克兰总统沃洛迪米尔·泽连斯基宣布投降,被传播给公众,引发了广泛的恐慌和混乱。
深度伪造带来的巨大威胁已经促使研究人员近年来创建了有效的深度伪造检测方法[4, 5, 6, 7]。大多数方法使用深度学习模型将输入分类为“真实”或“伪造”,这是一个二元分类。其中绝大多数方法仅针对单一模态[8],主要探讨视频中的视觉伪迹。在过去的几年中,涉及音频或视频的多模态深度伪造已经开始出现,生成更加逼真和多样化的内容[9, 10]。音频-视频检测方法[11, 12, 13, 14]已经被提出,用于将音频和视频的特征进行融合,用于深度伪造检测。通过分析两种模态,比如融合音频-视频特征[9, 11]或学习音频-视频不一致性[14, 12, 15],可以提供丰富的信息来揭示深度伪造。然而,现有研究表明,利用多模态并不能保证与应用单一模态相比能获得更高的准确性[9, 11, 15]。探索如何利用多模态来增强深度伪造检测值得进一步研究。
考虑到音频-视频深度伪造可以以各种方式进行操纵,例如将真实视频与合成音频配对、将真实音频与脸部替换的视频组合,或同时修改两种模态,因此在探索多模态特征时考虑这些类别非常重要。然而,现有的特征融合方法将不同类型的深度伪造视为相同的伪造类型。这可能会混淆单一模态的特征学习,特别是在基于集成的融合中[9, 11, 15]。例如,在具有真实视频和伪造音频的深度伪造以及具有伪造视频和伪造音频的深度伪造的情况下,样本的标签相同,但视频分支可能会学习不稳定的特征以进行融合。引入单一模态检测损失[15]可以减轻混淆,但融合性能未必会提高。我们认为,受音频和视频生成模型的限制,音频-视频伪造的不一致性在不同类型的深度伪造之间变化。因此,在本文中,我们提出了一个细粒度深度伪造识别模块,以引导检测模型识别出单模态或双模态中存在的视频中的不同伪造痕迹,而不是像以前的检测方法一样将音频-视频样本视为简单的二元分类任务。我们提出了一种简单但有效的方法,用于识别四种类型的视频中的视觉-音频痕迹,包括真实视频真实音频、真实视频伪造音频、伪造视频真实音频和伪造视频伪造音频。结合每个单一模态的痕迹学习,我们提高了音频-视频特征融合方法的性能。我们将该方法应用于两种检测骨干模型,包括广泛使用的Capsule network[16]和最近的Swin Transformer [17]模型。在两个公共的多模态深度伪造数据集上进行的领域内和跨领域测试实验显示,所提出的方法在性能上优于现有的检测器。
2 Related Work
2.1 Multimodal deepfake dataset
为推动检测技术的发展,建立了几个深度伪造数据集。早期的数据集主要关注视觉模态生成,要么利用真实音频,要么完全排除音频,如FaceForensics++ (FF++) [18]、CelebDF [19]、DFDC (Deepfake Detection Challenge) [13]和KoDF (Korean Deepfake Detection Dataset) [20]。随着音频生成技术的发展,最近创建了包括生成克隆伪造音频和生成的脸部的音频-视频深度伪造数据集,包括FakeAVCeleb数据集 [9]和TMC [10]。这两个数据集都涵盖了伪造视频与真实音频、真实视频与伪造音频、伪造视频与伪造音频以及真实视频与真实音频等类别。
2.2 Multimodal deepfake detection
深度伪造检测引起了广泛的兴趣。大多数单模态检测方法 [8] 侧重于视觉和面部特征。对于多模态深度伪造检测,研究人员提出了基于深度学习的音频-视觉模型。检测方法的一支使用了来自两种模态的特征或分数的融合 [11, 12, 15]。然而,音频和视觉网络的集成没有像专注于单一模态的检测方法那样令人印象深刻的结果。另一支方法利用多模态检测器来提取深度伪造中的音频-视觉不一致性 [14, 21, 12, 22]。这些方法在提供卓越性能 [9, 11] 或提供计算效率高的检测方面存在限制。
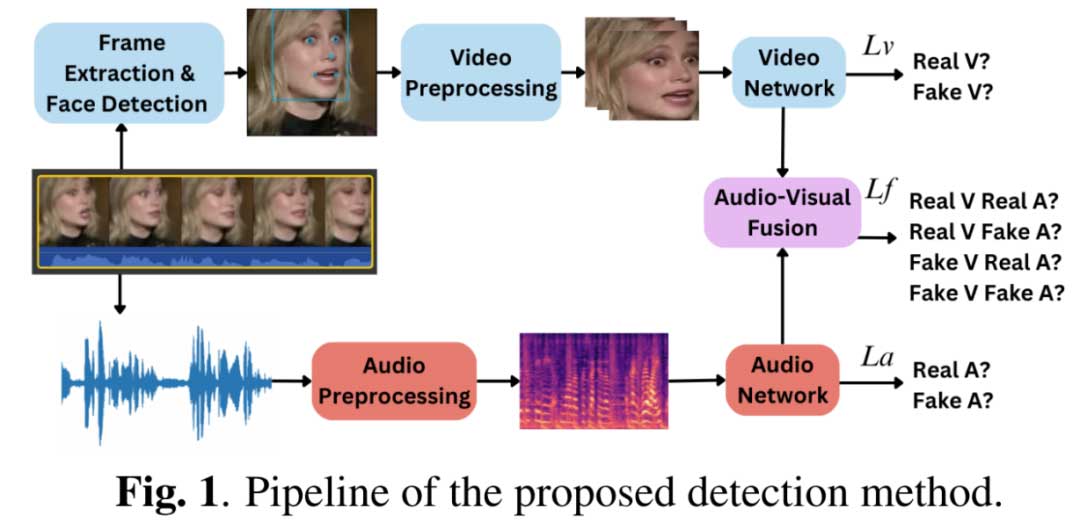

3 Proposed Method
我们提出了一种简单而有效的检测方法,以提高多模态深度伪造的检测性能。所提出的方法涉及音频和视觉分支的融合,并使用细粒度的深度伪造分类损失。我们进一步整合了来自每种模态的二元分类损失,以引导检测模型捕捉多模态的不一致性和每个单一模态的特征。在本节中,我们将首先描述每个单一模态的预处理模块,然后介绍特征提取网络,然后介绍多任务学习策略。
3.1 Video Branch
首先,对每个输入视频应用帧提取以输出图像。考虑到视频样本的长度各不相同,对于长于一分钟的视频,如TMC数据集中的视频,我们每秒提取一帧,对于较短的视频,如FakeAVCeleb数据集中的视频,我们提取所有帧。对于每一帧,使用基于MTCNN的人脸检测方法来检测和裁剪基于面部标志的面部区域。
3.2 Audio Branch
对于音频模态,我们首先从输入视频中提取WAV格式的音频。WAV文件中的音频以原始格式存储,不能直接传递到检测模型。因此,我们进一步将音频转换成梅尔频谱图像。梅尔频谱图是一种频谱图,其中频率被转换为梅尔刻度。为此,首先使用原始音频文件来获取随时间变化的气压样本,以数字方式表示音频信号,从而捕获信号的波形。这将音频文件转换为音频信号的数字表示。然后,使用快速傅立叶变换(FFT)将音频信号从时域映射到频域,FFT是一种能够有效计算傅立叶变换的算法,傅立叶变换是将信号分解为其各个频率和频率振幅的数学公式。这产生了一个频谱。然后,将频率刻度(y轴)映射到对数刻度,颜色维度(振幅刻度)映射到分贝,形成频谱图。然后,将y轴映射到梅尔刻度,通过另一种数学操作形成梅尔频谱图。梅尔刻度的转换方程如下:
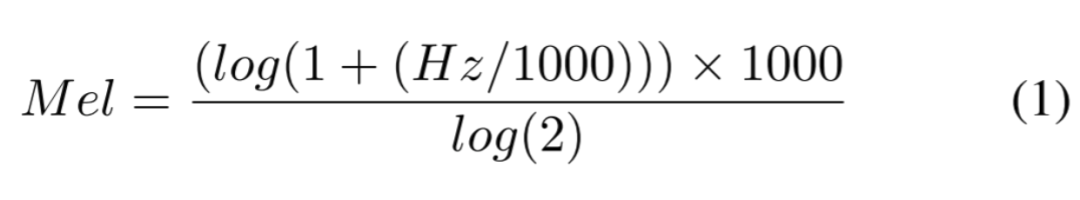
其中Hz代表频率。我们将文件转换成梅尔频谱图而不是频谱图,因为梅尔刻度将频率转换成对听众来说声音间距相等的方式。为了确保每个梅尔频谱图中显示的频率范围和长度相同,我们将频率刻度设置为0至8000赫兹,长度设置为4秒。
3.3 Feature Extraction
特征提取涉及将输入图像转换为高级特征,旨在捕捉对检测任务至关重要的数据内部的独特模式。预处理后的视觉面部图像和音频梅尔频谱图被输入深度神经网络,以自动提取用于深度伪造检测的特征。值得注意的是,我们的方法不对特征提取模型施加任何限制,并且在应用于各种网络架构时表现出灵活性。在我们的实验中,我们将使用Capsule网络,它在深度伪造检测方法中被广泛使用,以及Swin Transformer,它最近在各种图像分类任务中展示了强大的特征学习能力,作为视频和音频网络的两个示例,以展示我们的方法的灵活性。
3.4 Multi-task Learning
由于我们的方法提出了将细粒度伪造识别模块与每种模态的二元分类相结合,以进行不同的特征学习,因此我们通过融合三个损失函数来制定多任务学习策略。损失函数定义如下:
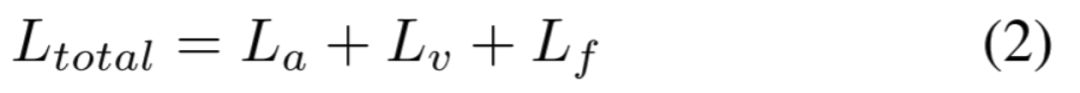
这里,La和Lv分别是应用于每个单独的音频和视频模态的二元交叉熵损失,Lf是一个四类交叉熵损失,考虑了不同类型的视频。每个交叉熵损失的定义如下:
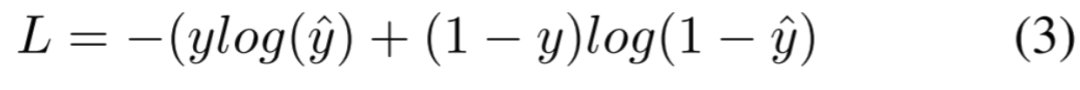
其中y是真实标签,ˆy是预测标签。
对于音频-视频模块,这是一个多类别分类任务,我们对多帧的视频网络输出进行平均,以代表输入视频的整体特征。音频-视频融合可以有两个版本。第一个版本涉及特征融合,其中来自视频网络的平均视觉特征与来自音频网络的音频特征(在移除分类头后)进行连接。第二种方法是得分融合,它平均来自包括分类头的视频和音频网络的分数。随后,融合的特征或融合的分数将被输入四类别分类头以进行视频识别。
4 Experimental Setup
4.1 Implementation Details
从视频中提取的帧被调整大小为300×300,音频梅尔频谱图像也被调整大小为300×300。检测模型进行了50个时代的训练,批处理大小为10。我们使用Adam优化器[26],其中β1 = 0.9,β2 = 0.999,学习率为5×10^-4。
与其他方法进行比较,我们报告了深度伪造检测中广泛使用的两个指标,即准确度和曲线下面积(AUC),AUC是在绘制真正例率与假正例率的曲线时生成的曲线下的总面积的度量。
4.2 Dataset
我们使用训练(80%) / 测试(20%)分割方式在两个多模态深度伪造数据集上评估了我们方法的性能,这两个数据集分别是FakeAVCeleb [9] 和TMC数据集 [10]。
FakeAVCeleb 数据集是通过使用VoxCeleb2中的真实名人视频生成的,该数据集包含了来自YouTube的真实视频,其中包括五种不同的种族背景:白种人(美国人)、白种人(欧洲人)、非洲裔美国人、南亚人和东亚人。每个种族背景中,男性和女性的数量相等。每个种族群体包括100位名人的真实视频,每种性别50位。这样生成了600个不同的视频,平均时长约为7秒。该数据集包含三种不同类型的音频-视频深度伪造(仅伪造音频、仅伪造视频或两者兼有),使用了常见的深度伪造生成方法。这些方法包括面部交换和面部再现方法。对于伪造音频的生成,他们使用合成语音合成方法生成克隆或伪造的语音样本。Wav2Lip是基于音频源进行面部再现的工具。
TMC Dataset 是在2022年创建的,旨在解决新加坡的虚假媒体问题。该数据集包括4,380个伪造视频和2,563个来自不同来源的真实素材,包括新闻节目中的主持人和记者、电视采访中回答问题的人以及讨论一般主题的人。TMC数据集中有72.65%的亚洲受试者和45.82%的女性受试者。这些视频的时长从10秒到1分钟不等。存在四种不同类型的伪造:仅伪造音频、仅伪造视频、音视频都是伪造的,或者音视频都是真实的,但音频和视频不匹配。与FakeAVCeleb类似,TMC数据集是使用常见的深度伪造生成方法创建的,包括面部交换和深度学习技术。其中,StarGAN-VC被用于生成伪造音频。
4.3 Baselines
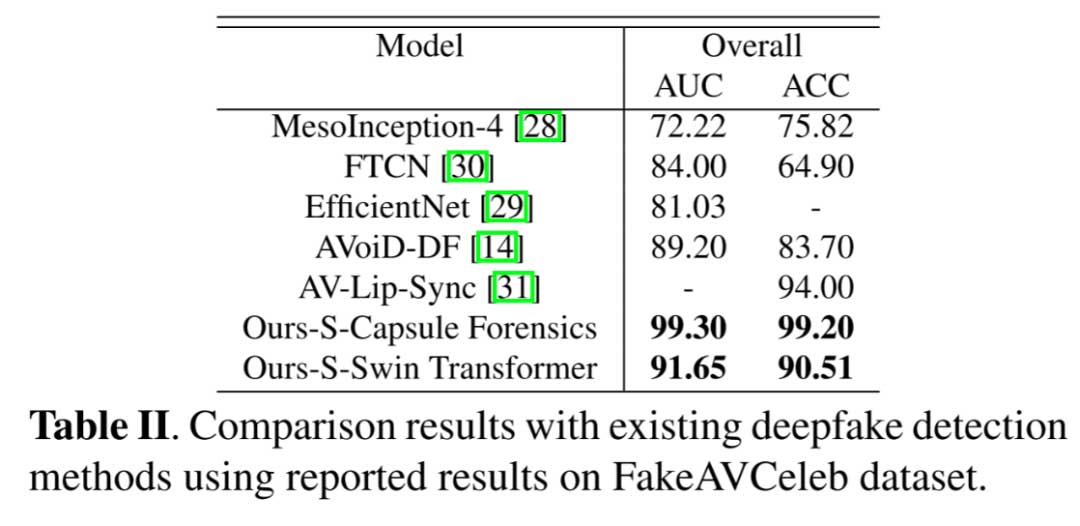
我们首先将提出的音频-视频方法与两种不同的检测策略进行比较,这两种策略分别基于Capsule网络[16]和Swin Transformer[17]模型。然后,我们与已有的深度伪造检测方法[11, 21]进行比较,这些方法是在FakeAVCeleb数据集上进行评估的,包括基于帧的集成方法MesoInception-4[28]、EfficientNet[29]和FTCN[30],以及音频-视频多模态方法,包括AVoiD-DF[14]和AV-Lip-Sync[31]。
4.4 Intra-domain testing
在同一领域测试情况下,检测模型在相同的数据集上进行训练和测试。表格I将我们的分数融合方法“Ours-S”和特征融合方法“Ours-F”与两个单模态模型(“Video”和“Audio”)以及基于二元分类损失的传统特征和分数融合方法进行了比较。
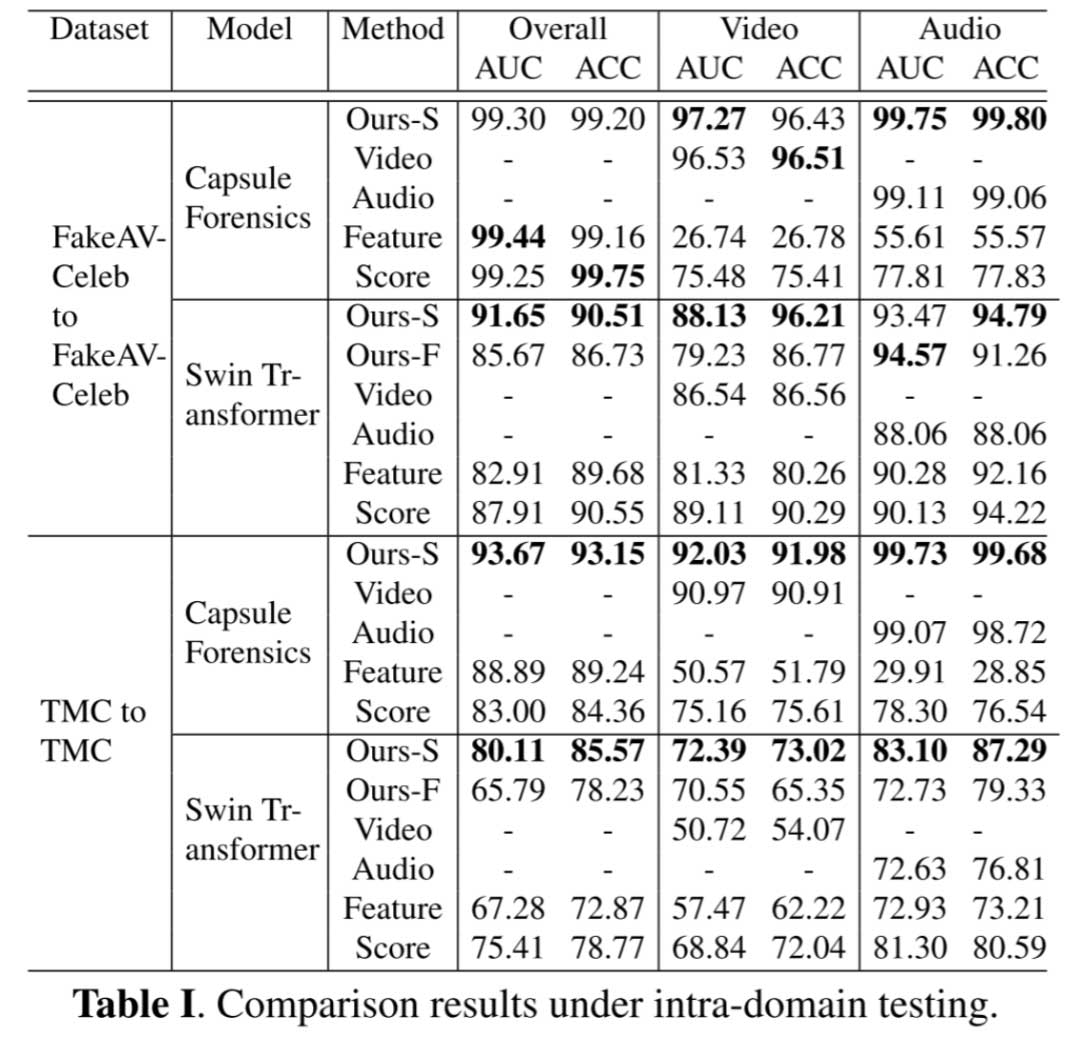
由于精细的视频识别模块的优势,我们的方法,特别是在分数融合的情况下,明显优于其他方法,在大多数情况下取得了最高的AUC和ACC得分。这显示了所提出的方法在识别多模态的工件方面的有效性。值得注意的是,所有方法在FakeAVCeleb数据集上的结果都高于TMC数据集。这可以归因于TMC数据集中视频和音频轨道的高度多样性和额外扰动。我们还将基于分数融合的方法与现有的深度伪造检测技术在FakeAVCeleb数据集上进行了比较。表格II中的结果显示了所提出方法在检测多模态深度伪造方面的出色性能,特别是在使用Capsule网络的情况下。
4.5 Cross-domain testing
为了评估所提出的方法在检测未见过的深度伪造方面的泛化能力,所提出的方法是使用不同的数据集进行训练和测试。表格III中的比较结果显示,我们提出的方法在跨领域测试场景下表现最佳。
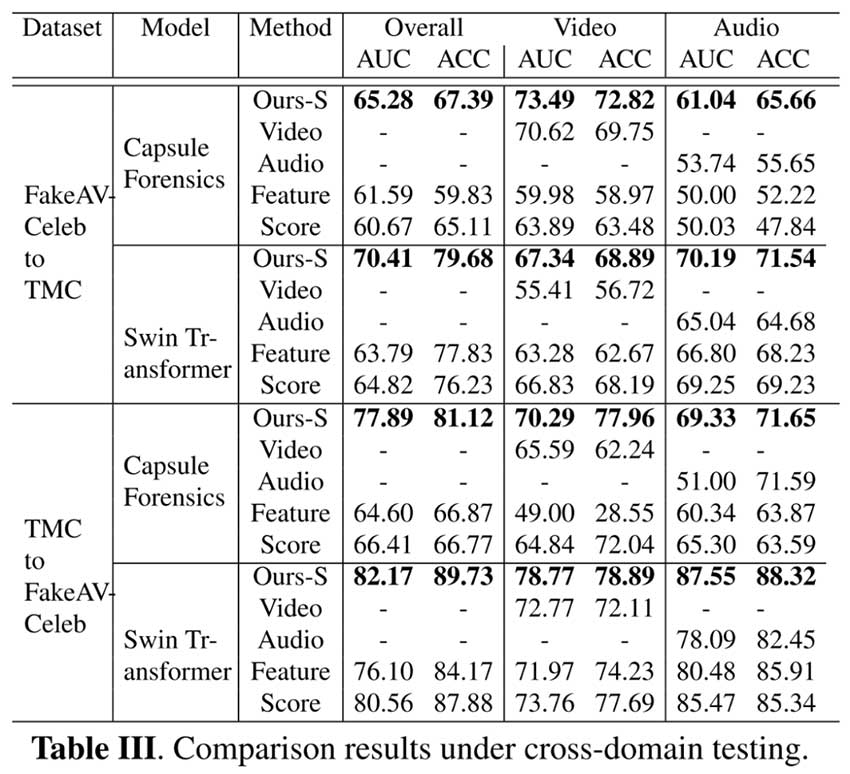
我们还可以观察到,使用TMC进行训练并在FakeAvCeleb数据集上进行测试在大多数情况下会导致更高的AUC和ACC。这是合理的,因为在更多样化的数据集上训练的模型(即TMC)会对未见过的数据表现出更强的泛化能力。此外,可以看到Swin Transformer明显优于Capsule网络,表现出更好的泛化能力。
4.6 Cross-type testing
TMC数据集中存在一种廉价伪造视频,即真实视频与不匹配的真实音频。为了进一步证明我们的方法在捕捉音频-视觉一致性特征方面的有效性,我们使用预训练模型来测试这些不匹配的视频作为跨类型测试。表格IV将我们基于分数融合的Swin Transformer模型与使用两种模态的最大预测的朴素融合方法进行了比较。
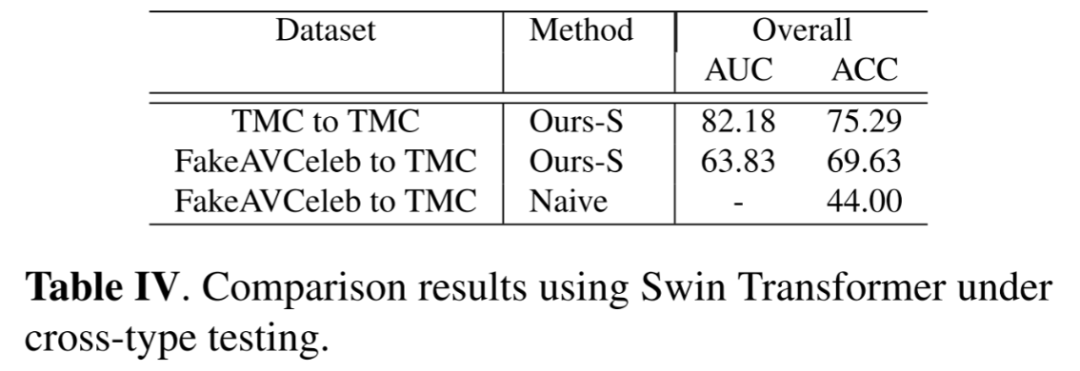
显然,我们的方法能够处理这些以前未见过的伪造类型,而朴素融合方法失败了。我们还发现,大多数不匹配的真实视频和音频样本都被归类为我们的多类别识别模块中的“真实视频假音频”类。这可以归因于这两种类型的伪造视频中发现的类似的音频-视觉模式,比如不同步。
5 Conclusion
我们引入了一种用于音频-视觉深度伪造检测的方法,该方法能够识别各种深度伪造类型中的多模态不一致特征,以及每种模态内的人工制品。所提出的方法表现出良好的适应性,可以应用于各种特征提取网络。在两个音频-视觉深度伪造数据集上的实验结果,无论在域内还是跨域,都突显了该方法的有效性。在未来的工作中,我们计划专注于开发更强大的多模态网络,以增强音频和视频模态的特征学习和融合策略。此外,探索如何提高多模态深度伪造检测方法对未见过深度伪造的泛化能力将是研究的一个重要领域。
论文翻译:内蒙古大学计算机学院 23级硕士研究生 鲜鹄鸿(导师:刘瑞研究员)
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。