
以下内容来自哔哩哔哩-流量接入层团队分享。
1、背景
事件简述:2023年8月4日 21:00-21:20 云厂商 CDN 服务故障,回源流量突增导致 BFS SLB 过载,影响依赖图片、JS/CSS静态资源的服务,大量用户出现白屏和无法播放视频的问题。
事件原因:因为云厂商 CDN 故障,自动执行域名下线策略,策略如下:
- 解析回源:域名被下线时,域名会解析回主源站
- 停用域名:域名被下线时,域名会被调整为”停用“状态,停止 CDN 加速服务,并且返回403
解析回源策略,瞬间产生几百G的流量,”攻击”源站BFS服务,服务瘫痪
停用域名策略,会造成大量用户被403处理,用户表现为页面白屏或者打不开
2、事件分析
1、从南北向流量分析
端侧用户(APP、Web和OTT等)打开B站的图片服务,依次经过 CDN、SLB(7层负载均衡)和BFS( B 站内部小文件存储服务);
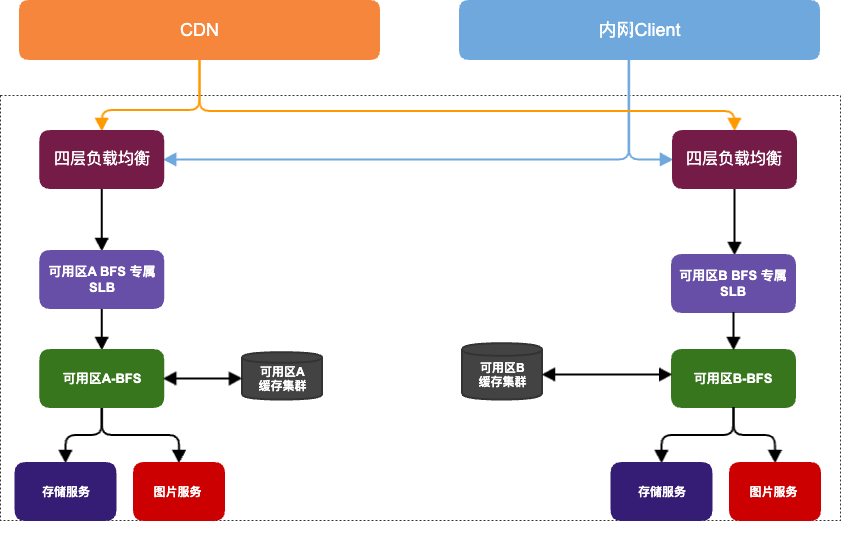

从上到下主要分为以下几层:
- CDN:内容分发网络,由多家第三方CDN厂商提供
- BFS专属SLB:由 SLB 团队帮助部署的、专属 BFS 的 SLB 集群,并通过四层负载均衡作为CDN的回源目标地址
- BFS服务:提供小文件存储服务;同时还集成了对图片文件的处理能力
- 缓存集群:由开源的HTTP缓存软件Apache Traffic Server搭建,相比 NGINX Proxy Cache,更适合海量小文件缓存
- 图片服务:实际提供图片缩放、裁剪、旋转、格式转换等能力的处理集群
- 存储服务:小文件实际存储,当前已迁移使用内部对象存储BOSS。
2、从事件原因分析
- 解析回源策略,对于图片类的静态资源服务,日常 CDN 的流量和请求命中率高达 98%,直接回源,相当于卸载率是 0,瞬间产生大流量的请求,请求直接回源源站;当时图片链路各个组件的实际情况
- SLB,多可用区部署,多集群CPU瞬间100%,返回5XX,原因:大家认为CDN有缓存,源站SLB的性能不存在瓶颈,所以没有设置限流等措施;
- SLB,发布限流失败,由于两个可用区物理机CPU同时达到了100%,导致发布配置文件失败,相当于机器处于失联状态;
- SLB,节点扩容无效,在扩容过程中出现新节点上线立即被打挂,在源站少量的机器情况下,还是无法扛住几十倍的回源流量;
- BFS,由于请求止步于SLB,故障初期无实际回源请求。
- 停用域名策略,用户请求被CDN直接封禁,并返回403,Web用户播放依赖的播放器js资源以及部分图片资源访问失败
- APP端,降级重试策略,APP 网络库xx在遇到网络失败的情况下,会进行域名级别的降级重试,从A降级到B;
- 403状态码不降级,因为403状态码在CDN系统中,常用于refer黑名单、UA封禁、IP封禁以及鉴权系统的场景,因此对于403状态码,APP库并不会进行主动的降级和重试;
- 同理,SLB和BFS也不会对403做降级和重试逻辑。
3、应急恢复阶段
目前B站内部关于安全生产有完整的理论指导,围绕1-5-10的构建业务的连续性
GOC的目标是:安全生产。拆分为三个子目标
- 故障预防:防止能预检的问题
- 故障快恢:快速恢复不能预防的问题
- 故障改进:不再重复已发生的问题
GOC提出了一个非常有稳定性指导意义的数据指标:1-5-10,可以指导我们如何做故障发现、故障定界定位、故障快速&预案建设
- 1:1分钟发现故障
- 5:5分钟定位故障
- 10:10分钟恢复故障
这里多一条解释:我们内部执行的是1+5+10,全局故障的恢复时长,目标控制在16min以内

我们看一下当时流量层,各个组件1-5-10的执行细节
- CDN:3分钟左右,收到端侧错误率指标异常告警;5分钟左右定位厂商;确认故障边界,流量陆续切给友商。此时大部分用户可以打开图片,但是SLB尚未恢复,依赖回源的业务此时无法恢复。
- SLB:2分钟左右,收到服务器CPU指标异常电话告警;5分钟内进行了节点扩容;但是由于请求流量过大后端请求耗时增加,无法立即恢复,需要添加限流逐步放开让存储恢复到正常水位。
- BFS:3分钟左右,收到回源服务指标异常电话告警,5分钟内进行了响应跟进;在协同故障处理的同时,对后端进行了扩容以应对SLB恢复后的流量反弹。
3、云边端协同
3.1.1 云:SLB优化方案
在整个流量请求的过程中,SLB充当着数据中心入口和业务的重要守护者。在这一层面上,我们设置了WAF、请求限流等防御措施,以确保核心域名和应用配置了合理的限流策略。
SLB的部署采用了多集群隔离的方式,这意味着即使发生故障,也只会影响到静态资源的回源,而不会因用户连接直接解析到源站导致过载,从而避免了全局故障的发生。
主要的功能涉及三个方面:
- 在线业务API接口的数据转发
- 静态资源转发(image/html/css/js)
- 离线日志数据的上报
然而,在故障时我们发现很多功能失效,控制面和节点失联,配置无法进行变更。与此同时,新的扩容机器也无法承受大量的回源请求(日常CDN命中率为98%)。
为了解决这一问题,我们采取了以下策略:
- 在SLB中增加了全局连接数限制,通过压测来确定适当的连接数大小;
- 为控制面保留了部分核心资源,以避免请求数过多导致CPU资源耗尽,从而无法更改集群配置;
- 采用BBR限流策略,类似于我们Kratos框架中的CPU自适应限流。当机器负载达到80%时,可以自动舍弃部分请求流量。
以上的措施对于SLB的系统稳定性起到了重要的作用,有效防止了集群雪崩等突发情况的发生。特别是BBR限流策略,在极限情况下尽可能地保证请求的转发,进一步提升了系统的可靠性和稳定性。
3.1.2 云:BFS优化方案
BFS 是 B 站统一小文件存储服务,承载了公司级静态资源的存储与分发需求;故障期间,BFS 故障产生了全站级别的影响,包括不限于:
- 用户侧加载 HTML/CSS/JavaScript 高概率失败,部分用户遭遇网页白屏等问题;
- 部分缩略图无法访问,如稿件封面、图文动态、评论,显著影响用户体验;
- 阻塞内部审核平台工作,影响稿件开放时效;
- 内部中间件平台相关静态资源无法加载,影响研发人员排障。
其中,用户侧静态资源加载受损对用户感知最为明显,历史上为便于业务更新,大量静态资源配置了一个相对较短的缓存有效期,因此故障感知明显。
BFS 针对以上典型场景,做了以下优化:
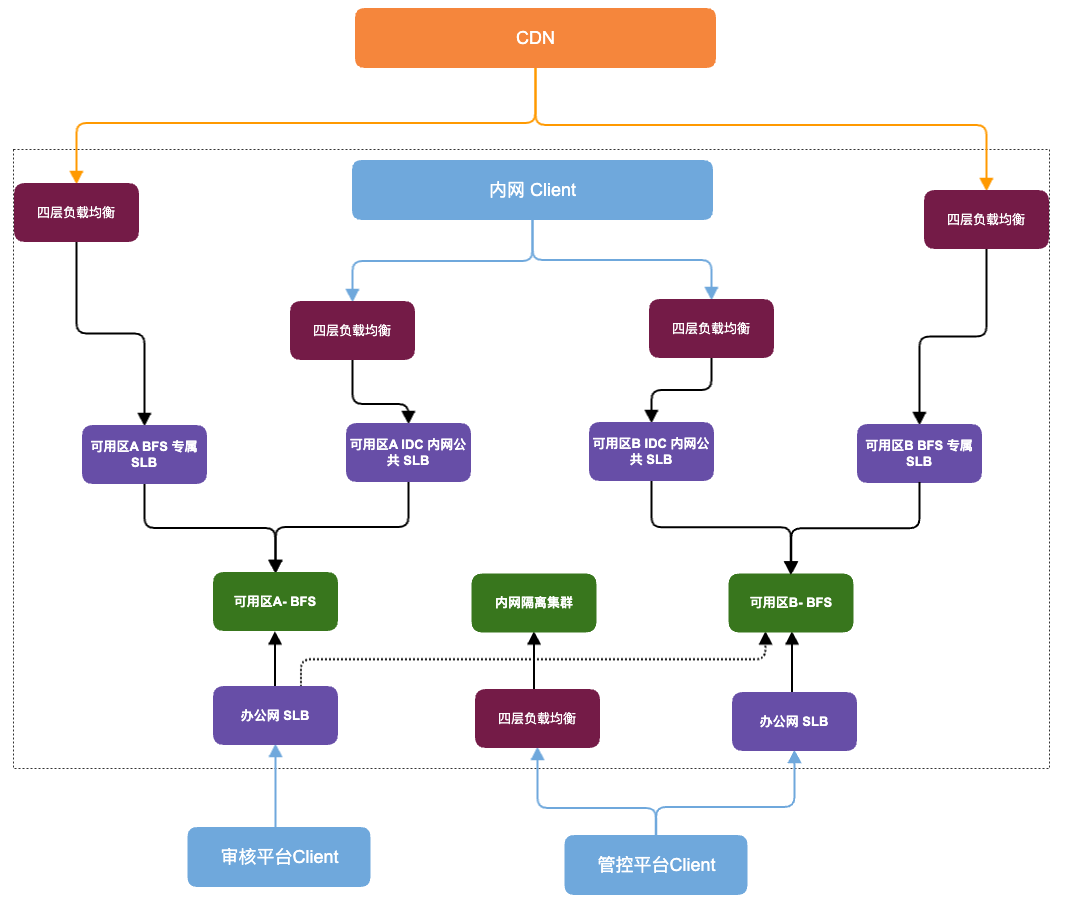
- 用户侧前端静态资源业务上要求缓存有效期较短,对可用性要求高;在其他常规稳定性建设基础上,我们在第三方云存储内备份了全站静态资源文件;在源站整体不可用的最坏情况下,依赖 CDN 备用回源策略,降级请求到云厂商存储,隔离故障域,减少用户对故障的感知;
- 内部审核平台所用图片流量相对较小,但其可用性显著影响 UP 主稿件开放时效,我们将其审核平台所用资源的相关链路拆分到独立 SLB 集群进行接入;
- 内部中间件平台,如 SLB 管控平台、发版平台,主要面向公司内部研发人员,请求流量极低;过去我们按照普通业务统一接入,但本次事故发生初期,研发人员尝试查看日志排查问题时,因日志平台网页资源加载依赖 BFS,导致日志平台无法查看,影响排查进度;故障后,BFS 针对内部系统所用资源,从负载均衡到元信息服务、存储节点等组件,全部单独物理机独立部署,以隔绝其余业务依赖,消除循环依赖;内部发布平台也支持了既有 BFS 和新隔离集群的双写发布,日常通过 DNS 多解析同时提供服务。
改造后,整体源站BFS的部署架构如图所示:
3.2 边:图片CDN智能调度系统优化方案
目前B站图片CDN智能调度系统,围绕 智能告警->根因分析→自动调度三个核心子系统保证CDN的业务稳定性,针对常见场景故障,区域运营商粒度,自动化调度覆盖度达到95%,但是全局故障影响面较大,同时受限于架构设计影响,所以全局故障更多的是靠人的经验判断和决策
DNS调度
LDNS调度是CDN流量调度常见的方式之一,也是目前行业中图片和动态CDN的调度方式,我司和行业保持一致
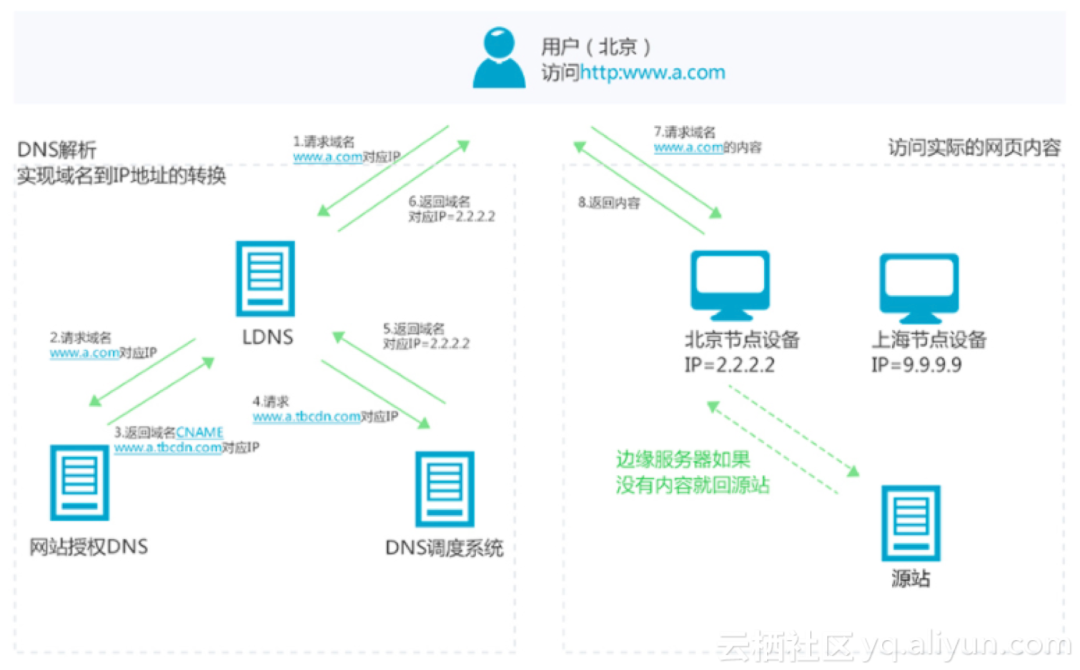
图片CDN的调度是基于LDNS+HttpDNS实现,调度粒度粗,时效性差,在端侧开放能力的支持下,依靠端的管控能力,构建B站边端协同调度新体系成为了一种可能,端侧具备调度能力,极大的解决了LDNS调度的一些缺点和问题,提高了调度的准确性和时效性
端侧调度是一种新的调度形式,19年底,B站上线端侧调度,主要是图片和API的场景
目前 端+CDN的一个联动策略如下:
1. 端APP,图片请求重试,依次请求A域名, B域名, C域名,如下图

不足:a.该策略会造成一个问题是请求的大头集中在A域名,B和C域名在日常的请求量比较小,命中率较低,故障情况下,短时间从A切到B或者C,会造成缓存击穿,所以日常A域名是多家覆盖b.多家覆盖在单厂商故障的时候,很难快速定位定界,在故障处置的时候,不同的厂商之间,要考虑缓存预热和击穿问题
2. 端APP,图片请求降级,针对建联失败的情况进行降级重试,403和5xx不重试
3. CDN,理想设计,单域名对应单厂商,做到域名级别的厂商隔离,如图6,有2个好处a.降级的时候重试到不同的域名,即不同的厂商,提高成功率,避免出现连续的降级,命中同一个故障厂商b.端上在遇到解析失败或者拿不到CDN IP的时候,无法识别哪些厂商的CDN厂商故障,例如,无IP或者无heade里的厂商标识,但是可以很容易拿到请求的域名的错误率,方便定位定界
端调度
优化点:
1. CDN侧优化降级厂商了逻辑:域名和厂商隔离,从域名A多供应商,域名B和域名C单供应商,拆分为:域名A 对应 CDN-X厂商, 域名B对应CDN-Y厂商, 域名C对应CDN-Z厂商,每个供应商同时配置域名A、B和C,但是缓存共享,在单厂商内切换不同域名,不会出现缓存击穿等问题
2. 端APP侧:把域名A、域名B和域名C的请求打散,让不同的CDN厂商,在同一业务租户下,同时拥有相同的资源,避免多厂商故障切换的缓存预热和击穿问题。
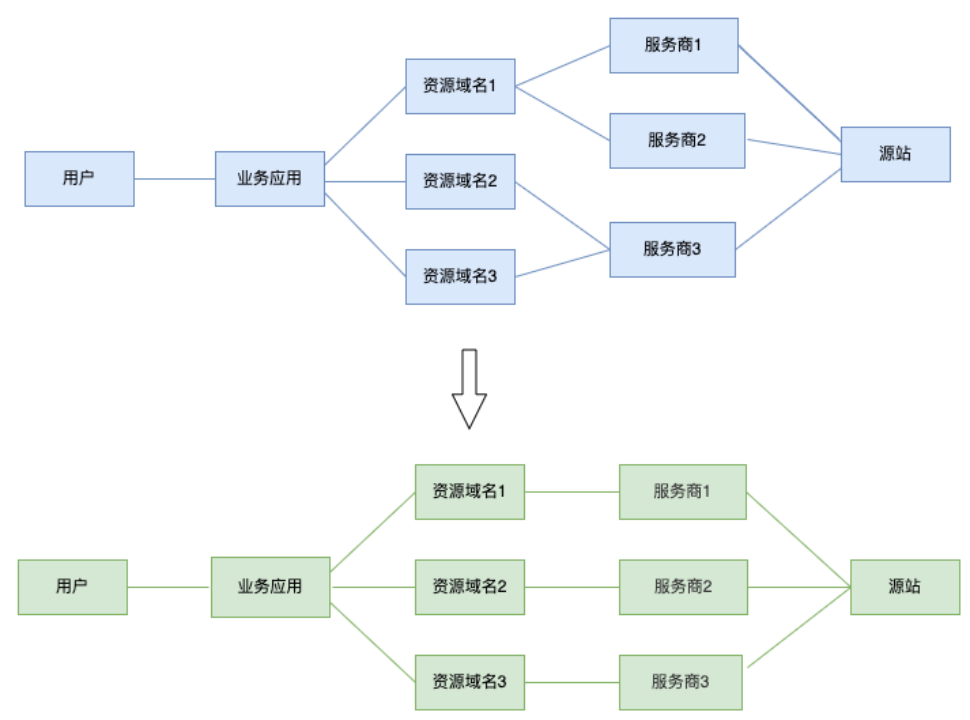
3.GTM(全局流量管理系统):在LDNS和端调度的基础上,强化端侧调度能力,调度体系上移,元信息管理,降级域名,降级顺序,权重配比等,联动端fawkes平台;并提供场景式的全局故障预案平台化能力
3.3.1 端:APP策略
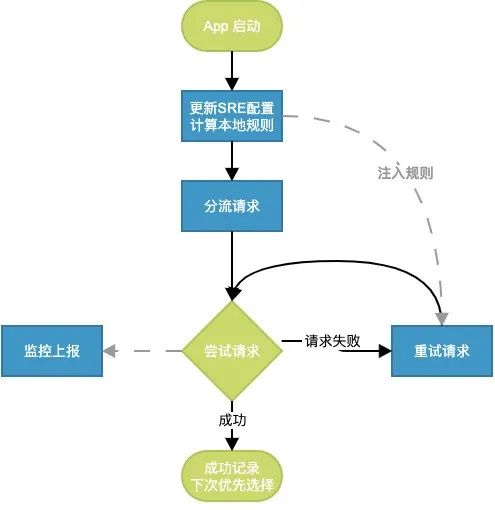
App端通过分流和重试策略来进行端上的负载均衡和应急处理,保障用户体验。核心思路为:基于设备级分流+多域名协同+基于错误码的重试。
分流策略:
客户端分流策略主要流程如下
- 接收CDN调度系统动态下发的全局分流策略,分流策略定义了各个分桶的大小(例如域名 i0:i1:i2 使用4:3:3比例)
- 客户端使用buvid(设备ID)计算当前设备的分桶值
- 客户端找到命中的分桶和对应的规则,假设命中分流规则为[i2, i0, i1]
- 客户端将所有的i0,i1,i2请求域名全部分流到i2域名
客户端目前使用设备级维度(buvid)进行分流,使得各个域名的资源保持在一定的比例量级,优化缓存热度的问题。未来可以细化到mid、机型、版本或者请求路径做分流,把调度精确到每一个用户每一个路径。
降级策略:
客户端降级策略主要流程如下
1. 从上述分流规则中,客户端可以获得降级域名列表,例如上述当前设备命中规则 [i2, i0, i1],且客户端已经完成请求资源分流,所有资源请求全部使用i2域名
2. 如果i2请求失败,客户端将检查失败的原因,决定是否进行重试。客户端对于以下三种失败场景将进行重试:
a.建连失败b.证书校验失败c.http status code 500/502/504
3. 重试依次使用 [i2, i0, i1]域名,并且全局保证最多重试两次
4. 如果重试成功,客户端对于后继请求全部使用成功的域名,直到冷启重置
3.3.2 端:Web策略
配置逻辑
我们接入了配置平台,可以通过下发配置的形式控制客户端功能是否开启以及降级策略。
通过配置域名i0:i1:i2的比例来实现用户分桶后所在的默认域名达到按比例分配的逻辑,在发生故障时,按客户端均匀计算的降级域列表顺序降级。
分流策略
web端分流策略主要流程如下
- 接收配置平台下发的程序开关以及域配比,如[1,1,1]
- 使用buvid(设备ID)计算当前设备的分桶值
- 以分桶值结合配比区间,映射到一个确定的域,假设命中i2,剩余的域均匀打乱排序,最终得到分流规则为[i2, i0, i1],排在列表第一序号的域名即为默认域
- 前端将所有的i0,i1,i2请求域名在首次请求时,全部分流到i2默认域名
AutoFallback SDK设计
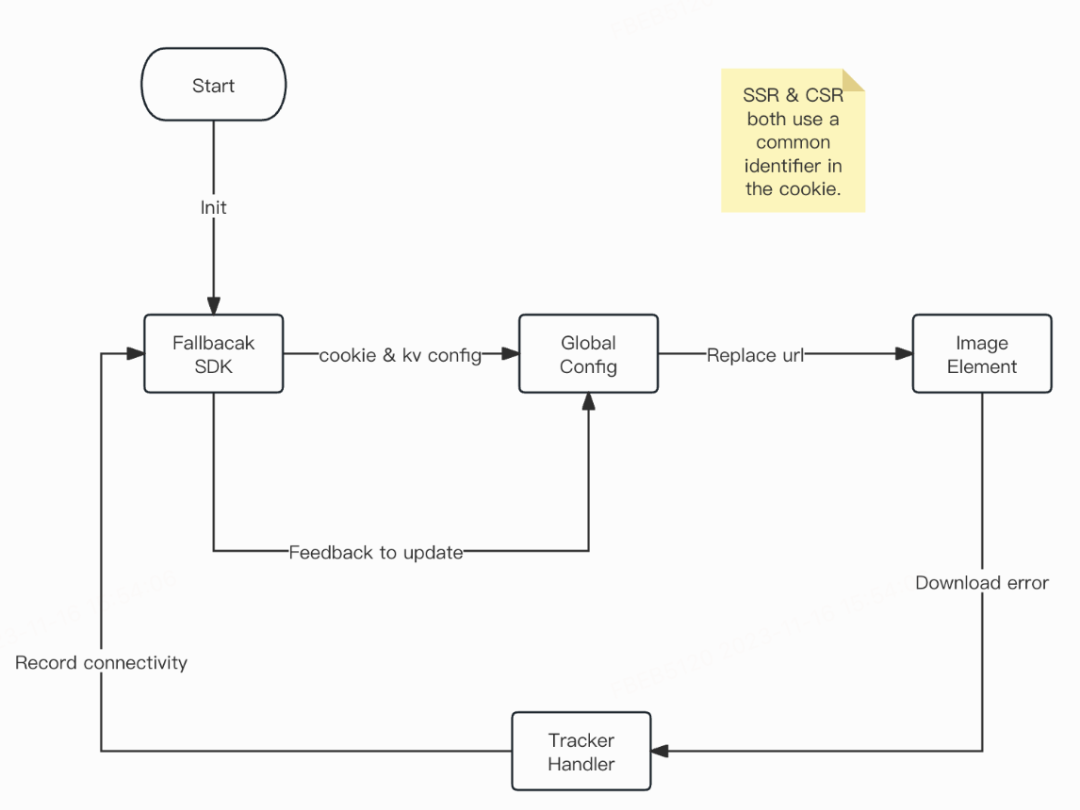
该SDK可以与任意的图片组件工作,因为其核心是以ImageElement为基础实现的。
图片在触发error时,调用AutoFallback.getNext(img.src)得到下一个资源信息NextInfo 或 null(此处有计算性能)
- 如果为null,说明已无法再降级
- 如果不为null,可取NextInfo.src,同时next.strategy 为2时说明已经到最后一次fallback,可以为img标记一下fallback-end attr,以此前置判定不进入getNext计算,提升性能
逻辑链路
远程开关(kv配置),本地开关(cookie中的开关标记:<“1″开启,非”1″关闭>)
- 远程&本地开关未开启,cookie中没有”默认域“ => 无任何效果
- 远程&本地开关未开启,cookie中有”默认域“ => 无任何效果
- 远程开关未开启,cookie中开关开启,cookie中有”默认域“ => 会替换默认域,也有降级功能,同步开关配置后,会清除cookie 中的默认域以及本地开关,下次访问同1
- 远程&本地开关开启(非首次),cookie中有”默认域“ => 会替换默认域,也有降级功能
- 远程&本地开关开启(非首次),cookie中没有有”默认域“ =>无 任何效果,在同步配置完成后,会植入分桶后的cookie默认域,下次访问同4
- 远程开关开启,cookie中开关未开启(首次),cookie中没有”默认域“ => 无任何效果,在同步配置完成后,会植入本地开关以及分桶后的cookie默认域,下次访问同4
4、总结
过去,在遇到南北向链路的组件全局故障的时候,各个团队侧重于解决内部服务稳定性,忽视了上下游的技术衔接,在降级的手段和方案上,缺少全局视角,缺乏整体性,在故障的应急处置和止损恢复上存在较大的优化空间。
CDN、SLB和BFS网关类流量层组件,天然具备分布式容灾能力,在故障的转移、降级重试和熔断层面,做好上下游的限流统一口径、分层分组件的降级预案、以及服务SLO指标承诺,同时结合端侧开放的调度能力,可以大大提升整体链路的容灾降级能力。
未来,在云边端调度一体化的框架下,依靠云数据中心的算力、算法和数据模型,把流量的调度和容灾能力,逐步下沉到端,调度效率和容灾能力更强;强化基于1-5-10形成的稳定性治理方法,提升内部流量组件服务SLA,将流量层各个组件打造成一个更稳定的产品,助力业务更好的发展。
5、参考
- 十三天精通超大规模分布式存储系统架构设计——浅谈B站对象存储(BOSS)实现
- 阿里巴巴稳定性指标1-5-10调研
- 从Kratos分析BBR限流源码实现 https://www.cnblogs.com/haiyux/p/15227815.html
- 淘宝移动端统一网络库的架构演进 https://developer.aliyun.com/article/1353951
作者
王岩:哔哩哔哩资深运维工程师;陈志辉:哔哩哔哩资深开发工程师;龚振:哔哩哔哩资深开发工程师;简思鹏:哔哩哔哩资深开发工程师;邓小超:哔哩哔哩资深开发工程师
来源:流量接入层团队 哔哩哔哩技术
原文:https://mp.weixin.qq.com/s/Tg6JQl4r73Jc3sKxE53rlQ
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。