
现代语言模型的记忆行为面临越来越多的质疑。例如,一个拥有 80 亿个参数的转换器,需要用 15 万亿个词元进行训练,研究人员开始质疑这些模型是否能够以有意义的方式记忆训练数据。数据提取和成员推理等常用技术往往无法区分记忆和泛化,因此存在不足。
现有方法的局限性
先前的框架,例如基于提取的方法或差异隐私,都是在数据集级别运行,并未考虑特定于实例的记忆。通过压缩进行语言建模,并通过事实记忆进行容量评估(例如 RNN 和量化 Transformer),虽然提供了部分洞察力,但缺乏可扩展性和精度,尤其是在深度 Transformer 架构中。
测量记忆力的新方法
来自 FAIR at Meta、Google DeepMind、康奈尔大学和 NVIDIA 的研究人员提出了一种新颖的方法,用于估算模型对特定数据点的“了解”程度,从而衡量现代语言模型的容量。他们将记忆分为两个部分:非预期记忆(代表模型包含的关于数据集的信息)和泛化(捕捉关于真实数据生成过程的信息)。他们计算总记忆,通过去除泛化来提供对模型容量的准确估计,结果表明 GPT 系列模型的容量约为 3.6 位/参数。研究人员还通过训练数百个 Transformer 语言模型,开发了一系列缩放定律,将模型容量和数据大小与成员推断关联起来。
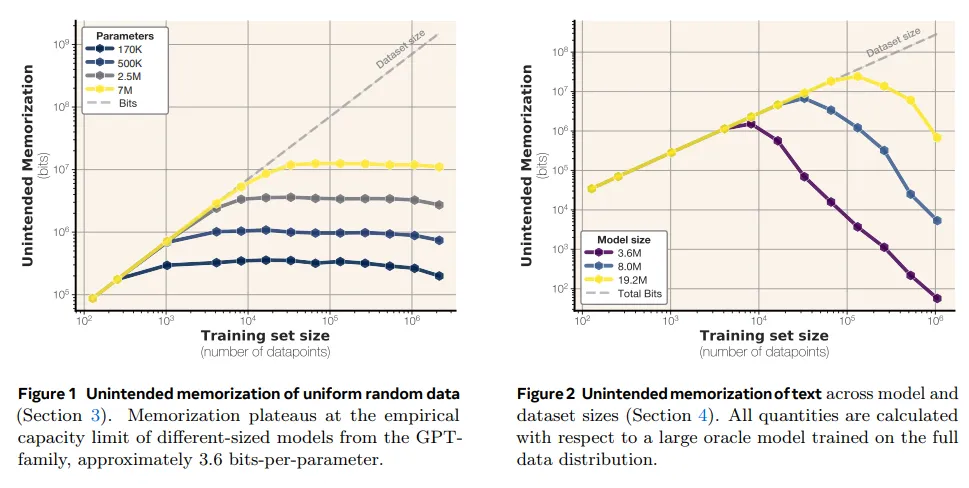

实验框架与训练方法
该团队使用 GPT-2 架构训练了数百个模型,这些模型的参数数量从 10 万到 2000 万不等,深度(1-8 层)和隐藏层大小(32-512)各不相同。训练内容包括:
- 10^6步
- 批次大小:2048
- 精度:bfloat16
- 硬件:单个 A100 GPU
这些模型在 FineWeb 数据集的合成序列和去重后的 64 个 token 文本序列上进行训练。实验通过精心构建数据集,确保泛化干扰最小化。
模型容量洞察和主要发现
- 每个参数的位数:在各种配置中,模型始终存储在3.5 到 3.6 位/参数之间。
- 双重下降:随着训练数据集大小接近模型容量,测试损失最初会减少(过度拟合),然后随着模型开始推广而再次改善。
- 精度影响:与 bfloat16(~3.51 bpp)相比,float32 中的训练会略微增加存储容量(至约 3.83 bpp)。
解开记忆与概括
从合成文本数据集转换为真实文本数据集后,研究团队观察到:
- 样本级别的意外记忆会随着参数数量的增加而增加。
- 随着训练集规模的增加,记忆力会下降。
- 准确估计模型记忆需要重复数据删除并参考 Oracle 模型来确定基线压缩率。
Membership Inference Scaling Laws
研究人员将基于损失的成员推理的成功率(F1 分数)建模为模型容量与数据集大小之比的函数。主要观察结果如下:
- 随着数据集的增长,成员推断变得不可靠。
- 对于多达 15 亿个参数的模型,预测扩展定律的准确率保持在 1-2% 以内。
结论:更好地理解模型行为
这项工作建立了一个用于测量语言模型中记忆性的原则性框架。通过引入可量化的指标和可扩展的实验,它加深了我们对 Transformer 模型如何编码训练数据的理解,并在记忆性和泛化性之间划出了清晰的界限。由此得出的洞见可以指导未来模型评估、隐私和可解释性方面的发展。
论文地址:https://arxiv.org/abs/2505.24832
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58793.html