
近年来,深度学习技术在许多语言和图像处理任务中取得了显著的成果。这包括视觉语音识别(VSR),它只需要通过分析说话人的嘴唇运动来识别说话的内容。
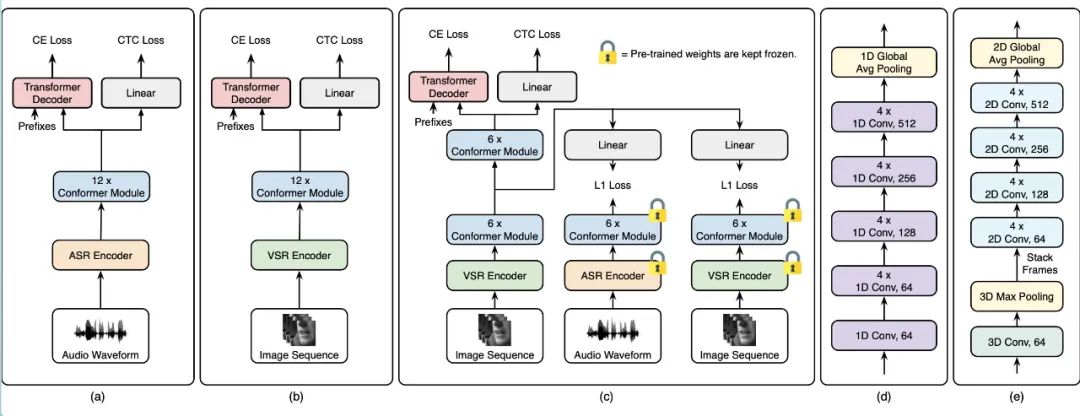

a-c、基线ASR模型(a)、基线VSR模型(b)和建议的模型(c)以及基于预测的辅助任务。提取的视觉特征和音频特征的帧率为25。(d) 来自a.e的ASR编码器的架构,来自b.的VSR编码器的架构。图片来源:Ma,Petridis&Pantic.虽然一些深度学习算法在VSR任务上取得了非常有希望的结果,但它们主要是被训练用于检测英语语音的,因为大多数现有的训练数据集只包括英语语音。这将它们的潜在用户群限制在那些生活或工作在英语环境中的人。
最近,伦敦帝国理工学院(Imperial College London)的研究人员开发了一种新的模型,可以用多种语言处理VSR任务。发表在《自然机器智能》(Nature Machine Intelligence)杂志上的一篇论文介绍了这个模型,发现它比之前提出的一些在更大数据集上训练的模型表现更好。
“视觉语音识别(VSR)是我博士论文的主要主题之一,”进行这项研究的帝国理工学院博士研究生Pingchuan Ma表示。“在我的学习期间,我研究了几个主题,例如探索如何将视觉信息与音频相结合进行视听语音识别,以及如何独立于参与者的头部姿势识别视觉语音。我意识到,绝大多数现有文献只涉及英语口语。”
Ma和他的同事最近研究的关键目标是训练一个深度学习模型,从说话者的嘴唇运动中识别英语以外的语言的语音,然后将其表现与其它训练过的识别英语语音的模型进行比较。研究人员创建的模型与过去其他团队引入的模型相似,但它的一些超参数得到了优化,数据集得到了增强(即,通过添加合成的、略微修改的数据版本来增加大小)并使用了额外的损失函数。
“我们证明,我们可以使用相同的模型来训练其他语言的VSR模型,”Ma解释说,“我们的模型需要原始图像作为输入,不提取特征,然后自动学习有用的特性从这些图像中提取完整的VSR任务。这项工作的主要新颖之处在于,我们训练了一个模型来执行VSR,并添加了一些额外的数据增强方法和损失函数。”
在最初的评估中,Ma和他的同事创建的模型表现得非常好,即使它需要更少的原始训练数据,也优于其它在更大的数据集上训练的VSR模型。然而,正如预期的那样,它的表现不如英语语音识别模型,主要是由于可供训练的数据集更小。
“我们通过精心设计模型,而不是简单地使用更大的数据集或更大的模型,在多种语言中取得了最先进的结果,这是目前文献中的趋势,”Ma说。“换句话说,我们表明,与增加模型的规模或使用更多的训练数据相比,如何设计模型对其性能同样重要。这可能会导致研究人员试图改进VSR模型的方式发生转变。”
Ma和他的同事们表明,人们可以通过精心设计深度学习模型,而不是使用相同模型的更大版本或收集额外的训练数据在VSR任务中实现最先进的性能,这既昂贵又耗时。在未来,他们的工作可能会激励其他研究团队开发替代的VSR模型,可以有效地从英语以外的语言的嘴唇运动中识别语音。
“我感兴趣的主要研究领域之一是如何将VSR模型与现有的(纯音频)语音识别结合起来,”Ma补充说。“我特别感兴趣的是如何动态地对这些模型进行加权。也就是说,模型如何根据噪声来学习应该依赖哪个模型。换句话说,在嘈杂的环境中,视听模型应该更多地依赖于视觉流,但当口腔区域被遮挡时,它应该更多地依赖于音频流。现有的模型一旦训练,基本上就会被冻结,无法适应环境的变化。”
信息源于:techxplore
文献:Pingchuan Ma et al, Visual speech recognition for multiple languages in the wild, Nature Machine Intelligence (2022). DOI: 10.1038/s42256-022-00550-z
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。