
声源定位(Sound Source Localization, SSL)作为机器听觉领域的基础任务,在增强听觉、机器人技术、自动驾驶等场景中应用广泛。现有 SSL 技术主要分为声学信号处理、数据驱动深度学习和混合方法三大类。
此前研究表明,结合随机模型与信号处理的混合方法虽有潜力,但导向向量(Steering Vectors)的稀疏测量和非高斯噪声鲁棒性问题一直是技术难点。
日本理化学研究所(RIKEN)等机构的研究团队提出了一种新型混合 SSL 技术——SHAMaNS(Sound Localization with Hybrid Alpha-stable Spatial Measure and Neural Steerer),将α稳定模型与基于神经网络的转向向量建模相结合,为解决上述挑战提供了创新方案。相关研究成果发表于预印本平台 arXiv。
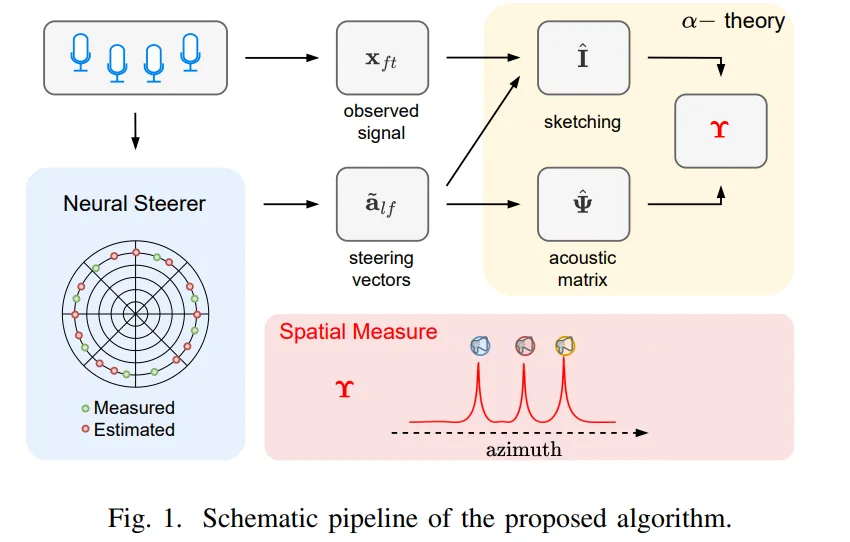

研究团队基于 α 稳定分布理论(α∈(0,2))构建了非高斯噪声下的空间测度模型。该模型将观测信号视为多个 α 稳定源的线性组合,通过唯一的空间测度向量 Υ 表征声源到达方向(DOA),对脉冲噪声和模型误差具有天然鲁棒性。当 α<2 时,模型理论上可唯一确定声源方向,为复杂噪声环境下的定位提供了数学基础。
针对导向向量测量成本高、稀疏测量导致插值精度不足的问题,团队引入了 Neural Steerer 模型。这是一种基于坐标的物理信息神经网络,通过学习少量实测 SVs 的球面谐波(Spherical Harmonics)展开系数,实现对全空间导向向量的高精度插值。该方法可突破传统插值技术(如重心插值、球面样条)在稀疏测量下的性能瓶颈,仅需 32 个随机测量点(约 5% 全量数据)即可重构接近实测精度的导向向量。
此外,SHAMaNS 通过引入加性椭圆型 α 稳定噪声分量,将神经导向器的重构误差自然纳入模型框架。同时,提出观测归一化策略:
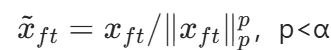
来抑制非高斯噪声中的异常值,确保低能量声源的准确识别。
研究团队利用 SPEAR 挑战数据集和 VCTK 语音库,在多种声学场景下对 SHAMaNS 进行了系统评估。实验设置包括 6 通道麦克风阵列、1.7 米距离的 60 个候选声源位置,通过变化声源数量(N=1 至 6)、信噪比(SNR=0 至 20dB)和混响时间(RT60=0.123 至 0.273 秒)构建多样化测试环境。
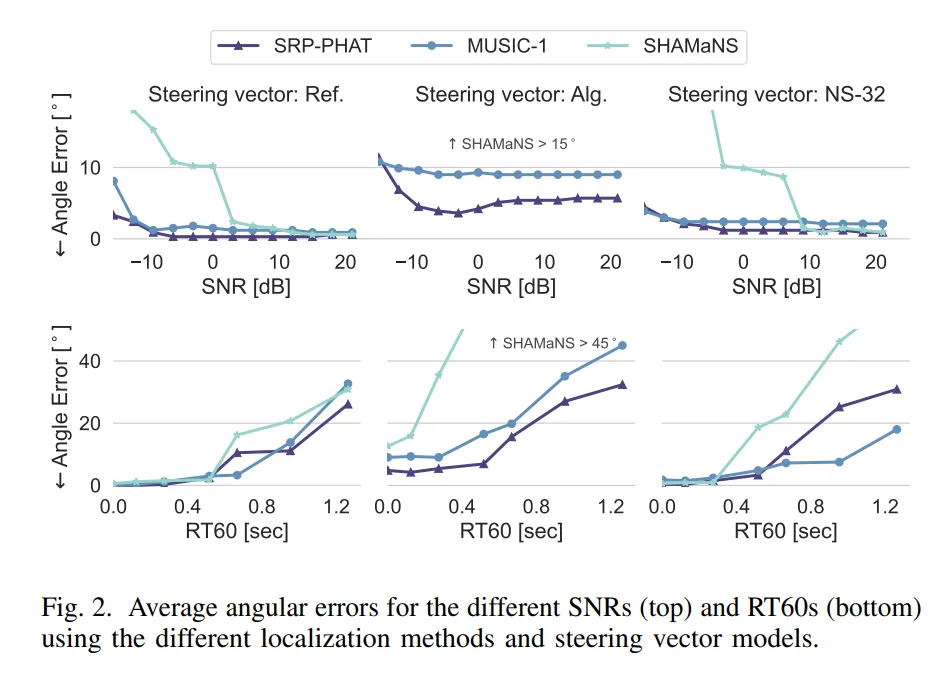
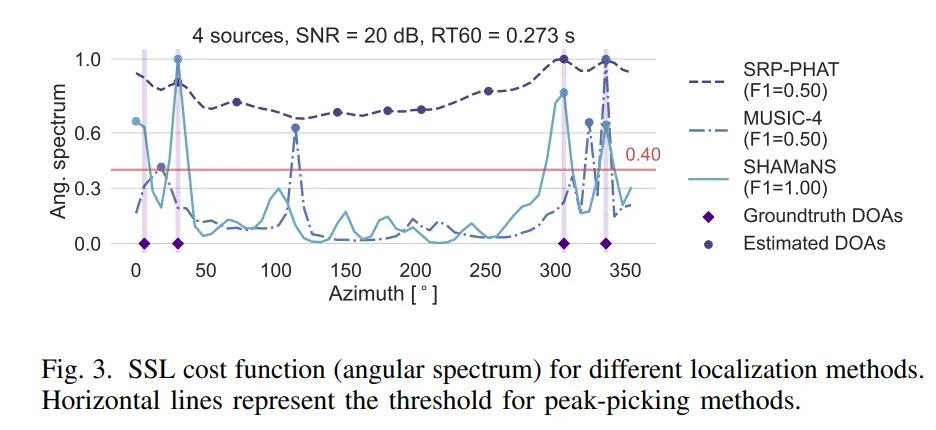
结果显示,在单声源情况下,当使用测量或插值转向向量时,SHAMaNS的平均角度误差仅为0.98°±2.45°,与MUSIC-1和SRP-PHAT方法相当。即使在代数转向向量下,SHAMaNS仍保持了良好的性能。
在多声源场景下,SHAMaNS也展现出优势。当声源数量在2到6个之间时(这是大多数实际应用场景),SHAMaNS的定位准确率超过了基线方法。即使在只有32个随机测量的情况下,SHAMaNS也能保持合理的性能,显示出其在测量数据有限情况下良好的适应能力。
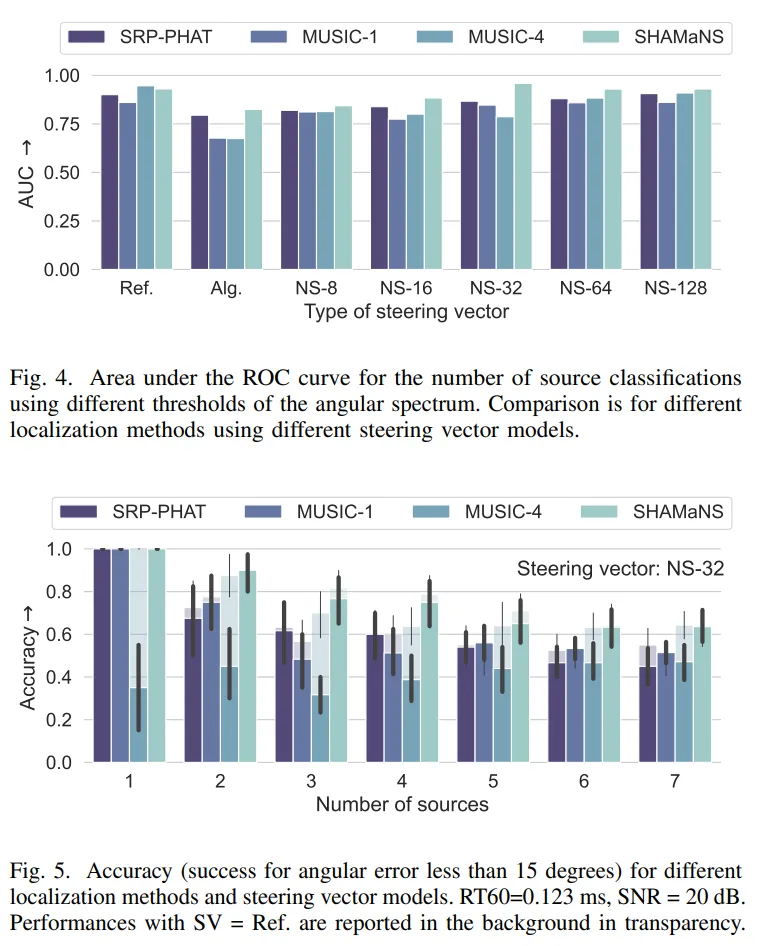
图 4. 使用角度谱的不同阈值进行声源数量分类的 ROC 曲线下面积。比较的是使用不同导向向量模型的不同定位方法。图 5. 不同定位方法和导向向量模型的准确率(角度误差小于 15 度为成功)。RT60=0.123 毫秒,SNR=20 分贝。使用参考导向向量(SV=Ref.)的性能以透明背景显示。
SHAMaNS 通过将 α 稳定理论的噪声鲁棒性与神经导向器的插值灵活性相结合,为复杂声学环境下的多声源定位提供了新的解决思路。该技术已开源(代码地址:https://github.com/chutlhu/shamans)。未来,团队计划拓展技术至三维空间定位,并探索其与声源分离的联合应用。
论文信息:Di Carlo D, Fontaine M, Nugraha A A, et al. SHAMaNS: Sound Localization with Hybrid Alpha-Stable Spatial Measure and Neural Steerer [J]. arXiv preprint arXiv:2506.18954, 2025.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。