
大语言模型(LLM)推动了机器翻译的进步,利用海量训练语料库翻译数十种语言和方言,同时捕捉细微的语言差异。然而,对这些模型进行翻译准确性的微调往往会损害其指令遵循和会话能力,而通用版本则难以达到专业的保真度标准。在精准、文化感知的翻译与处理代码生成、问题解决和用户特定格式的能力之间取得平衡仍然具有挑战性。
模型还必须保持术语一致性,并遵循不同受众的格式指南。利益相关者需要能够动态适应领域需求和用户偏好且不牺牲流畅性的系统。诸如涵盖 55 种语言变体的 WMT24++ 和 IFEval 的 541 个以指令为中心的提示之类的基准测试分数凸显了专业翻译质量与通用多功能性之间的差距,这对企业部署构成了关键的瓶颈。
当前针对翻译准确性定制语言模型的方法
人们探索了多种方法来定制用于翻译的语言模型。在平行语料库上对预训练的大型语言模型进行微调,以提高译文的充分性和流畅性。同时,持续对单语和平行数据进行预训练可以提高多语种的流畅性。一些研究团队在训练过程中加入了基于人工反馈的强化学习,以使输出结果符合质量偏好。GPT-4o 和 Claude 3.7 等专有系统已展现出领先的翻译质量,而包括 TOWER V2 和 GEMMA 2 模型在内的开源适配模型在某些语言场景下已经达到或超越了闭源模型。这些策略体现了研究人员为满足翻译准确性和广泛语言能力的双重需求而做出的持续努力。
TOWER+ 简介:翻译和一般语言任务的统一训练
来自 Unbabel、里斯本大学电信学院、里斯本大学高等技术学院(里斯本 ELLIS 部门)和巴黎萨克雷大学中央理工学院 MICS 的研究人员推出了一套模型TOWER+。研究团队设计了多个参数尺度(20 亿、90 亿和 720 亿)的变体,以探索翻译专业化和通用实用性之间的权衡。通过实施统一的训练流程,研究人员旨在将 TOWER+ 模型定位在帕累托前沿,同时实现高翻译性能和强大的通用能力,而不会牺牲任何一方。该方法利用架构来平衡机器翻译的特定需求与对话和教学任务所需的灵活性,支持一系列应用场景。

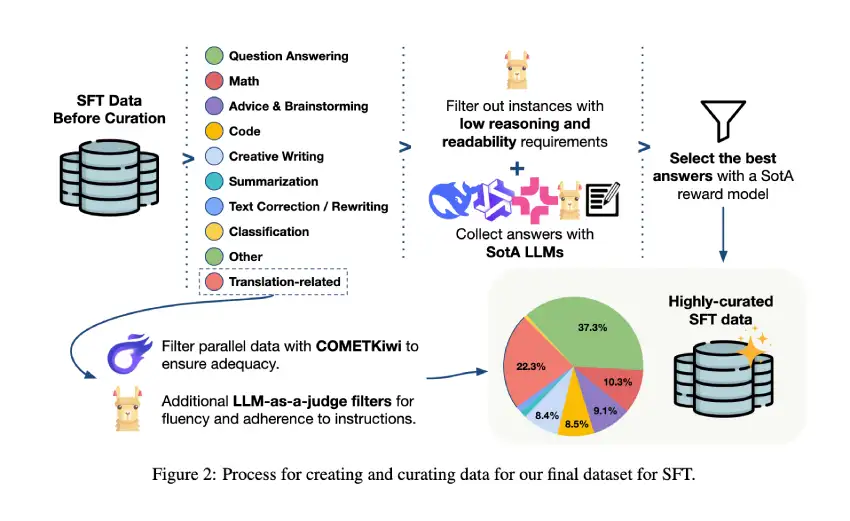
TOWER+ 训练流程:预训练、监督调优、偏好设置和强化学习
训练流程始于对精心挑选的数据进行持续预训练,这些数据包含单语内容、经过筛选并格式化为翻译指令的平行句子,以及一小部分类似指令的示例。接下来,通过监督式微调,结合翻译任务和各种指令遵循场景(包括代码生成、数学问题求解和问答系统)来完善模型。接下来是偏好优化阶段,采用加权偏好优化和基于非策略信号和人工编辑的翻译变体进行训练的群组相关策略更新。最后,采用可验证奖励的强化学习,强化对转换准则的精确遵循,使用基于正则表达式的检查和偏好注释来改进模型在翻译过程中遵循明确指令的能力。这种预训练、监督对齐和奖励驱动更新的组合,在专业翻译准确性和通用语言能力之间实现了稳健的平衡。
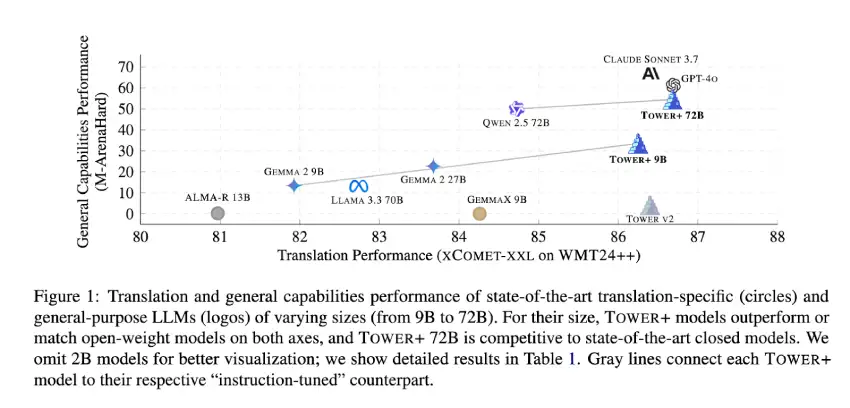
基准测试结果:TOWER+ 实现先进的翻译和教学跟踪
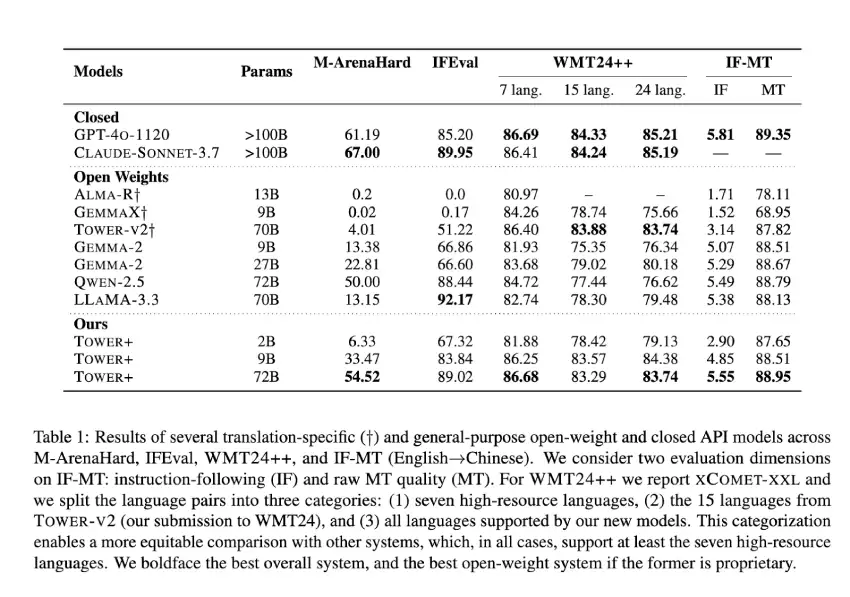
TOWER+ 9B 模型在多语言通用聊天提示中取得了 33.47% 的胜率,并在 24 个语言对中获得了 84.38 的 XCOMET-XXL 得分,优于同等规模的开放权重模型。旗舰级 720 亿参数变体在 M-ArenaHard 测试中取得了 54.52% 的胜率,IFEval 指令遵循得分为 89.02,在完整的 WMT24++ 基准测试中达到了 83.29 的 XCOMET-XXL 水平。在翻译和指令遵循的综合基准测试中,IF-MT 的指令遵循得分为 5.55,翻译保真度得分为 88.95,在开放权重模型中取得了最佳成绩。这些结果证实,研究人员的集成流程有效地弥合了专业翻译性能与广泛语言能力之间的差距,证明了其在企业和研究应用中的可行性。
TOWER+ 模型的关键技术亮点
- TOWER+ 模型由 Unbabel 和学术合作伙伴开发,涵盖 2 B、9 B 和 72 B 参数,用于探索翻译专业化和通用实用程序之间的性能边界。
- 后训练流程整合了四个阶段:持续预训练(66%单语、33%并行和1%指令)、监督微调(22.3%翻译)、加权偏好优化和可验证强化学习,以保留聊天技巧并提高翻译准确性。
- 持续的预训练涵盖 27 种语言和方言,以及 47 种语言对,超过 320 亿个标记,合并专门和通用检查点以保持平衡。
- 9B 变体在 24 对中在 M-ArenaHard 上取得了 33.47% 的胜率,在 IFEval 上取得了 83.84% 的胜率,在 XCOMET-XXL 上取得了 84.38% 的胜率,IF-MT 得分分别为 4.85(指令)和 88.51(翻译)。
- 72 B 型号的 M-ArenaHard 记录为 54.52%,IFEval 记录为 89.02%,XCOMET-XXL 记录为 83.29%,IF-MT 记录为 5.55/88.95%,创下了新的公开重量标准。
- 即使 2B 模型也匹配更大的基线,M-ArenaHard 的翻译质量为 6.33%,IF-MT 的翻译质量为 87.65%。
- 以 GPT-4O-1120、Claude-Sonnet-3.7、ALMA-R、GEMMA-2 和 LLAMA-3.3 为基准,TOWER+ 套件在专业任务和一般任务上始终达到或优于其他性能。
- 该研究提供了一种可重复的方法来构建可同时满足翻译和对话需求的 LLM,从而减少模型扩散和运营开销。
结论:未来翻译类 LLM 的帕累托最优框架
总而言之,通过将大规模预训练与专门的对齐阶段相结合,TOWER+ 证明了卓越的翻译能力和灵活的对话能力可以在一个开放权重套件中共存。这些模型在翻译保真度、指令遵循能力和通用聊天能力之间实现了帕累托最优平衡,为未来特定领域的 LLM 开发提供了可扩展的蓝图。
资料
- 论文地址:https://arxiv.org/abs/2506.17080
- 模型:https://huggingface.co/collections/Unbabel/tower-plus-6846ca452a10c0905dc03c0f
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/59242.html