
奖励模型是将 LLM 与人工反馈对齐的基础组件,但它们面临着奖励黑客攻击的挑战。这些模型关注的是诸如响应长度或格式等表面属性,而不是识别诸如真实性和相关性等真正的质量指标。这个问题的出现是因为标准的训练目标未能区分训练数据中存在的虚假相关性和响应质量的真正因果驱动因素。无法区分这些因素会导致奖励模型 (RM) 变得脆弱,从而生成不一致的策略。此外,我们需要一种方法,利用对偏好形成的因果理解来训练 RM,使其对因果质量属性敏感,并且不受各种虚假线索的影响。
现有 RM 方法的局限性和因果稳健性的必要性
现有方法试图解决标准 RLHF 系统中的奖励黑客问题,这些系统依赖于 Bradley-Terry 或成对排序方法。这包括架构修改(如 Odin)、策略级调整和以数据为中心的方法(涉及集合或一致性检查)。近期的因果启发方法针对预先指定的虚假因素使用 MMD 正则化,或通过校正重写来估计因果效应。然而,这些方法只针对预先确定的虚假因素,而忽略了未知的相关因素。虽然增强策略仍然粗糙,以评估为重点的方法也未能为奖励模型提供针对各种虚假变化的强大训练机制。
Crome 简介:LLM 的因果稳健奖励模型
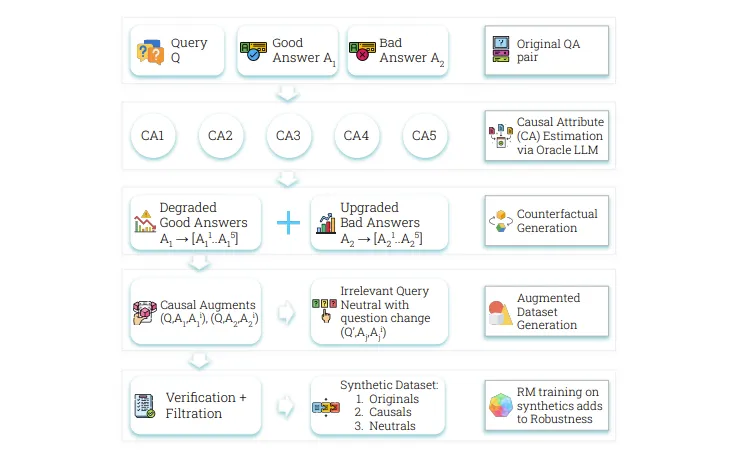

来自 Google DeepMind、麦吉尔大学和魁北克人工智能研究所 (MILA) 的研究人员提出了 Crome(因果稳健奖励模型),这是一个基于明确的答案生成因果模型的框架。Crome 通过添加偏好数据集,并利用 LLM 生成的定向反事实示例,训练奖励模型 (RM) 区分真正的质量驱动因素和表面线索。此外,它还创建了两种类型的合成训练对:
(a) 因果增强,针对特定的因果属性(例如事实性)引入变化,以增强对真实质量变化的敏感性;
(b) 中性增强,使用关联标签 (tie-labels) 增强对风格等虚假属性的不变性。
Crome 增强了稳健性,将 RewardBench 的准确率提高了 4.5%,从而增强了安全性和推理能力。
技术方法:反事实增强和复合损失优化
Crome 的运作主要分为两个阶段:基于因果模型生成属性感知的反事实数据,以及使用特定损失函数对组合数据进行奖励模型训练。它提供了理论分析,阐明了在理想模型下,因果增强如何将真正的奖励驱动因素与虚假相关因素区分开来。Crome 使用 UltraFeedback 数据集,其中包含使用 Gemini 2.0 Flash 生成的反事实数据,并在 RewardBench 和 reWordBench 上评估其性能。研究人员在实验中使用了多种基础 LLM,包括用于成对偏好和 Bradley-Terry 奖励模型的 Gemma-2-9B-IT、Qwen2.5-7B 和 Gemma-2-2B,并通过在多个任务中进行 Best-of-N 选择来影响下游的对齐效果。
性能提升:从 RewardBench 到 WildGuardTest
在 RewardBench 上,Crome 的排名准确率在多种基础模型上均优于 RRM,尤其是在安全性(高达 13.18%)和推理(高达 7.19%)类别中均有显著提升。在 PairPM 设置下,使用 Gemma-2-9B-IT 的 reWordBench 测试中,Crome 的总体准确率提升高达 9.1%,并且在 23 个转换中的 21 个中表现出色。此外,与 RRM 相比,Crome 从 RewardBench 到 reWordBench 的排名准确率下降幅度较小(分别为 19.78% 和 21.54%)。在 WildGuardTest 上,Crome 采用 Best-of-N 筛选法,展现出卓越的安全性提升,在有害提示的攻击成功率较低的同时,对良性提示的拒绝率保持相似。
因果数据增强的结论和未来方向
总而言之,研究人员介绍了 Crome,这是一个因果框架,用于解决 RM 训练期间的奖励黑客攻击问题。它采用了两种有针对性的合成数据增强策略:因果增强和中性增强。Crome 在 RewardBench 上的表现优于跨多个基础模型和奖励建模技术的强基线,并在 reWordBench 上对虚假相关性表现出卓越的鲁棒性。这种以数据集策展为中心的训练方法(即 Crome)为基础模型训练的合成数据生成开辟了新的研究方向,其中因果属性验证可能对未来稳健语言模型对齐的发展大有裨益。
论文地址:https://arxiv.org/abs/2506.16507
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/59420.html