
写在前面:在 AIGC 时代,数字人和影视动画行业快速发展,如何让角色的口型与音频完美同步,成为提升沉浸感的关键技术之一。音频驱动口型生成技术,通过算法将音频信号转化为逼真的唇形动画,不仅打破了传统手动调参的效率瓶颈,更在实时交互场景中展现出巨大潜力。从数字人的沉浸讲解到游戏角色的动态演绎,再到影视配音的自动化生产,这项技术正悄然重塑数字内容制作的体验边界。本文将深入解析音频驱动口型生成的核心技术路线。
背景篇
在追求沉浸式体验的数字时代,数字人和 AI 驱动的影视制作正以前所未有的速度融入我们的生活、娱乐和工作。这些角色形象能否自然、逼真地表达,是决定用户体验好坏的关键因素之一。其中,口型同步(即角色的唇形动画与其所说语音精确匹配)是至关重要的一环。一个表情丰富但口型错位的角色,会瞬间打破沉浸感,让用户感到“出戏”。
传统上,实现高质量的口型同步主要依赖手工关键帧动画、预录制动画库等费时费力的方法,往往需要极高的专业技能和巨大的时间投入。音频驱动口型生成技术应运而生,旨在解决这些痛点,并开启全新的可能性。其核心目标就是:输入一段音频信号,自动生成与之精确匹配、自然流畅的角色唇形动画。音频驱动口型生成技术因其自动化和逼真度的潜力,正在数字人主播、影视制作、智能客服等多个领域展现出革命性的应用前景。
音频驱动口型生成从输入形式上可分为两类:
- 视频+音频输入:输入一段需要修改口型的视频+驱动音频,输出音频口型对齐后的视频,通常称为视频配音或口型同步(Video Dubbing / Lip Synchronization)
- 图像+音频输入:输入一张角色图像+驱动音频,输出音频口型对齐的视频,称为肖像动画生成(Portrait Animation)
篇幅有限,本文将着重介绍视频+音频输入的口型生成技术。
技术篇
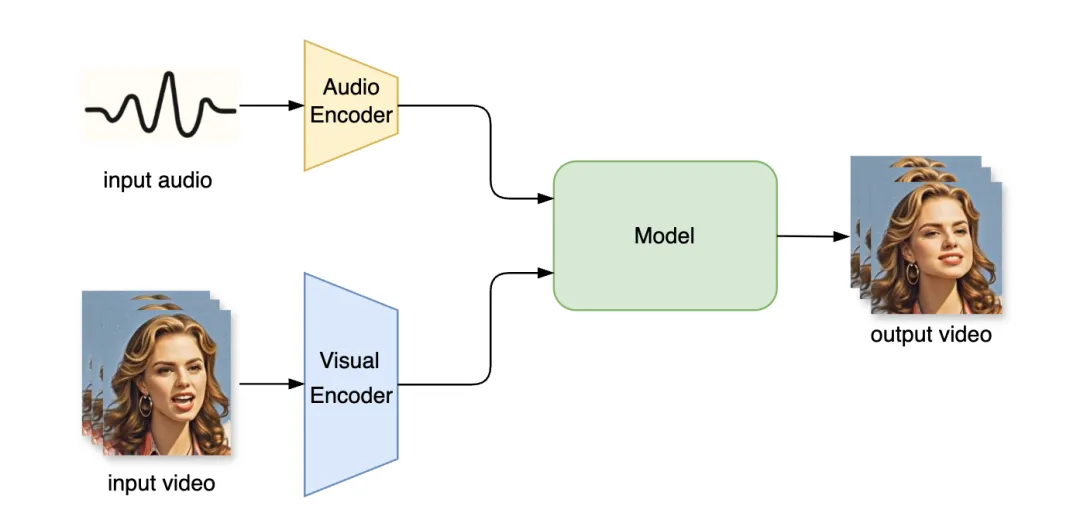
音频驱动口型生成技术经过几年的发展有非常多样的具体实现方式,但大体框架可概括为图 1 所示,主要模块包括:
- 音频编码器:负责将输入的驱动音频信号编码成音频特征,通常用一些预训练好的音频编码器(如 OpenAI 开源的 Whisper 模型[1]);
- 视觉编码器:将输入视频帧编码成视觉特征,通常采用卷积或 VAE [2]编码器;
- 生成模型:以音频为条件,将输入视频转变成口型匹配音频变化的视频。这是算法最核心的部分,生成模型可以是生成对抗网络 (GAN)[3]或近年在图像视频生成领域广泛使用的扩散模型(Diffusion Model)[4]。
其核心思想是生成模型,相比于基于计算机图形学(CG)的 3D 数字人口型驱动,生成式口型驱动方法具有逼真度高的特点,而且无需动捕设备或人脸关键点识别。而相比传统人工特效动画,效率更是数量级的提升。

音频驱动口型生成的关键挑战是口型同步的一致性。针对这一挑战,行业研究主要聚焦于以下几个方面:
- 生成建模方法;
- 驱动音频和输入视频如何进行信息交互,使得音频能更好的指导口型生成;
- 时序连贯性的建模和优化。
生成建模方法方面,在扩散模型广泛使用之前,基于生成对抗网络(GAN)的方法[3][5]一度是主流方案,然而这些方法存在一个主要问题,即由于训练不稳定和模式崩溃,它们难以扩展到大规模和多样化的数据集。近几年随着图像生成领域扩散模型的兴起,口型生成也引入了扩散模型来建模生成(图 2)。具体实现上通常使用隐空间扩散模型(Latent Diffusion Model,LDM)来降低计算量和显存需求,即先将像素空间的图像经过 VAE 编码器转成隐空间(latent space)特征,扩散模型以输入的音频特征为条件,在隐空间上进行多步扩散生成,最后将生成的隐空间特征解码到像素空间图像。扩散模型因其高效的生成建模方式和大规模数据扩展能力,泛化能力和生成效果均大幅提升。
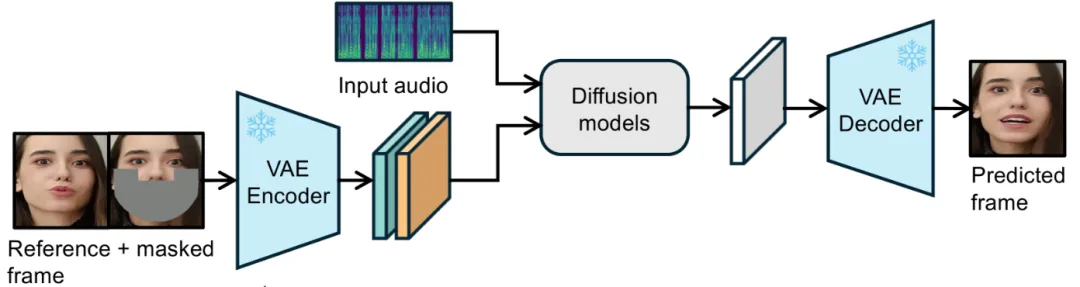
下面,通过介绍两个典型算法 LatentSync [6]和 OmniSync [7]来深入了解驱动音频和输入视频的信息交互、时序连贯性建模等方面的具体实现方式,以及针对某些挑战的优化策略。
LatentSync
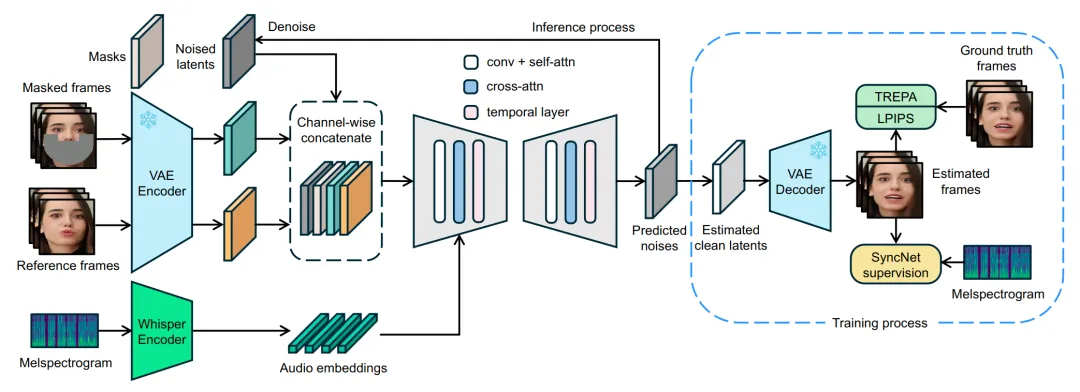
LatentSync 是行业首批使用隐空间扩散模型的音频驱动口型生成方法,大幅降低了算力和显存需求,让更高分辨率视频帧生成成为可能,并且提出了多项训练监督损失函数来提升口型同步效果和时序连贯性,取得了不错的生成效果。
LatentSync 整体框架如图3所示。生成模型骨干网络采用经典的Stable Diffusion 1.5 [4]的 U-Net。输入包含噪声隐变量、掩码、被遮挡帧和参考帧,其中被遮挡帧和参考帧经过 VAE 编码器转到隐空间,四个输入按通道叠加在一起。音频梅尔谱经过预训练的 Whisper 模型提取音频表征,将连续帧的音频特征通过跨注意力(cross-attention)注入 U-Net,与视觉特征进行融合交互。
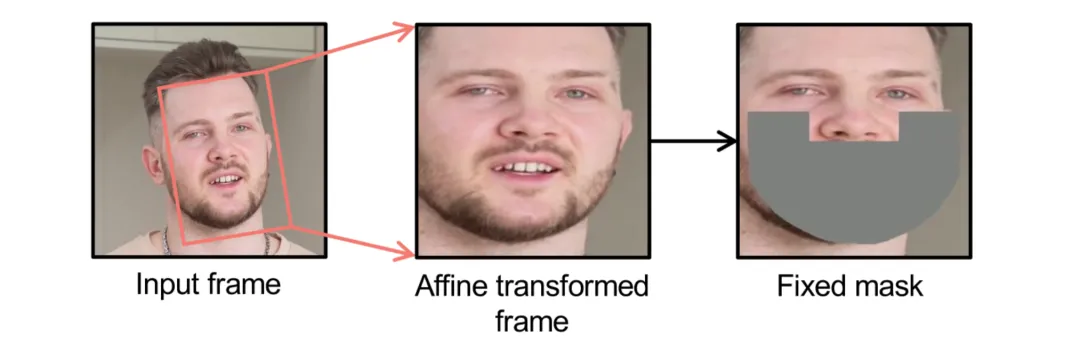
仿射变换和固定掩码
为了提升模型在侧脸等挑战性场景下的面部特征学习能力,数据预处理时使用仿射变换将脸统一转正。此外,口型生成中常出现视觉捷径(visual-visual shortcuts)现象,即模型可能学会一种捷径:直接根据眼睛及脸部的视觉信息推断出口型,而不受音频控制,这降低了音频驱动口型的一致性效果。 为了降低模型学习视觉捷径的倾向,LatentSync 使用覆盖全脸的固定形状掩码,该掩码不依赖动态的面部关键点,因为其运动轨迹也可能泄露唇部动作信息。仿射变换与固定掩码如下图所示。
SyncNet监督
为了提升唇形-语音同步的效果,可以加上 SyncNet [1]来提供额外的训练监督信号。SyncNet 是一个预训练好唇形-语音同步判别模型,为口型同步质量打分。LatentSync 研究者探索了两种 SyncNet 监督方案:(a)像素空间监督;(b)隐空间监督:需训练适配隐空间的 SyncNet ,其视觉编码器的输入为 VAE 编码得到的隐空间向量。实验表明(见下表),隐空间监督的 SyncNet 收敛性较差,可能由 VAE 编码过程中唇部区域信息丢失导致,而像素空间监督方案表现更优。
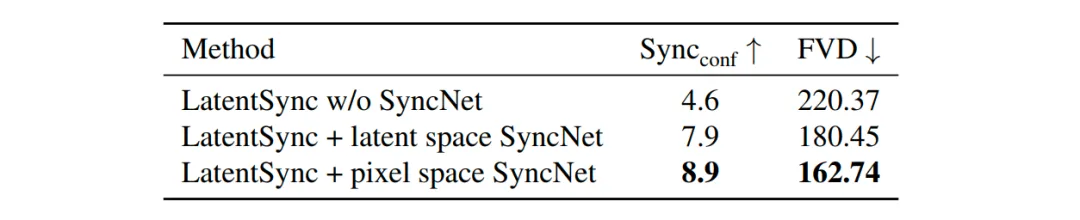
显存瓶颈之殇:两阶段训练策略
由于 SyncNet 像素空间监督的引入,训练过程中需要保存 VAE 解码的激活值用于梯度反传计算,这增大了训练过程显存消耗,因此,设计了两阶段训练策略。在第一阶段仅训练 U-Net(仅使用标准的噪声重构损失,不添加时序层),这一阶段无需进行 VAE 解码,显存占用较少,可使用较大批量加速视觉特征学习。在第二阶段,仅训练时序层(Temporal Layer)和音频层,冻结其他参数。这个阶段的损失函数包含多项:噪声重构损失、SyncNet 唇音同步损失、图像质量损失(包括 LPIPS 损失和 VGG 感知损失),以及 TREPA 时序损失。其中 LPIPS 和 VGG 损失提高了图像的视觉质量,而 TREPA 损失通过对齐生成帧和真实帧的时序表征来强化帧间一致性。
LatentSync 使用隐空间扩散模型比传统像素空间扩散模型降低了算力和显存需求,支持更高分辨率视频帧生成。为了提升口型同步效果和时序连贯性,增加了多项监督损失函数,并解决了训练过程中像素空间监督带来的显存难题,最终口型同步效果提升明显。
OmniSync
OmniSync 是一种创造性的使用无掩码方式的扩散模型口型生成方法,放弃了之前普遍使用的视频帧嘴部区域掩码重绘(masked inpainting)方式,而直接以视频帧加噪声初始化进行扩散生成。这在头部姿态变化、角色身份一致性、遮挡与风格化内容等方面具有显著优势,不仅从另一个角度解决视觉捷径问题,还能支持多样化的视觉场景,显著提高了鲁棒性和口型同步质量。

如图5所示,OmniSync 在处理人脸遮挡、姿态变化和风格化角色时能够保持高度的身份一致性,并生成准确自然的口部动作。相比于基于掩码的方法产生的边缘伪影和身份漂移,通过无掩码的训练范式有效保留了原始角色的面部特征与动态特性。
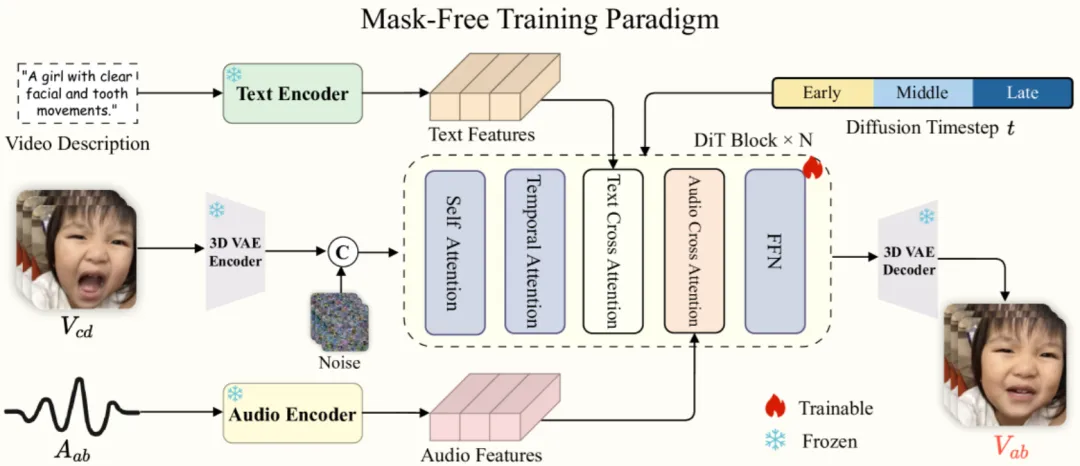
OmniSync 模型架构如图6所示,结构上与之前工作最大的区别在于,去掉了显式的嘴部掩码和参考帧信息,而用原始视频帧加噪声的形式输入,此外主干网络使用了比U-Net 更先进的 DiT,并使用 3D VAE [9]作为视频编解码器。
无掩码训练范式
传统的视频+音频输入的口型同步方法通常对嘴部区域进行掩码处理,并结合参考帧来恢复缺失内容。这种基于掩码的重绘(inpainting)方式容易在口部边界产生伪影,而参考帧的引入容易导致学习视觉捷径问题。此外这种方法需要依赖人脸检测与人脸关键点对齐,因此在姿态差异大或角色非真实人脸时常常失效。一种解决方案是直接帧编辑,不依赖参考帧和掩码,直接在音频条件下将一个视频迁移到另一个口型不同的视频。然而这需要完美配对的数据,即人物及人脸姿态一致只有口型不一样的视频对,这样的配对视频是极难大量获得的,容易获得的数据只有一段音频以及与之配对的口型视频,这将极大限制模型的泛化能力。
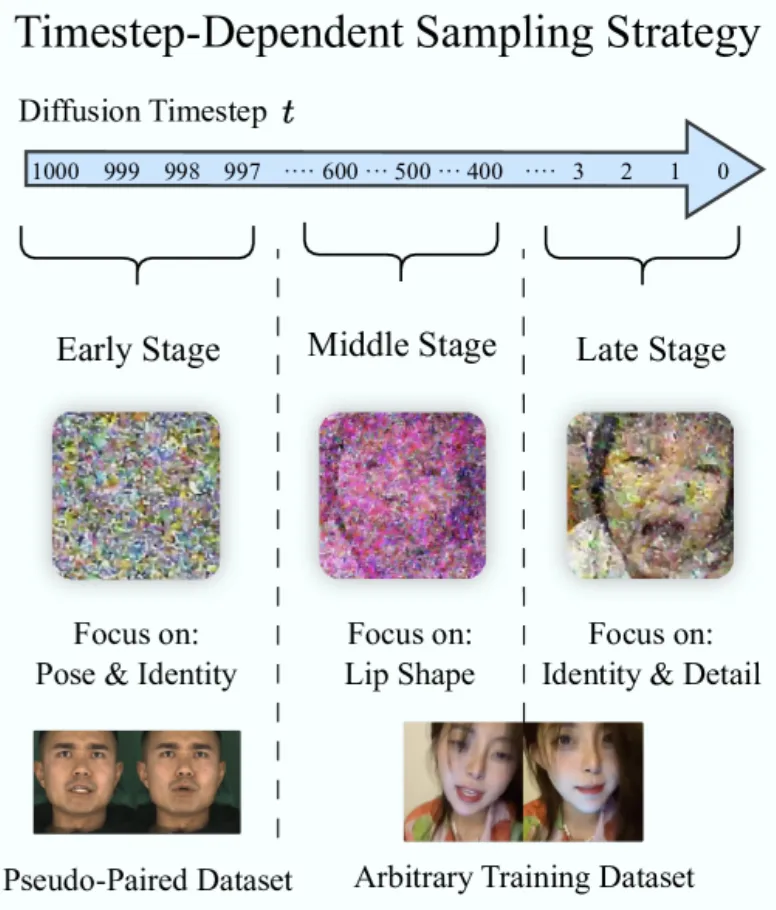
为解决这个限制,OmniSync 的研究者利用扩散模型的渐进式去噪特性,提出了一种新的训练策略:在扩散步的不同阶段采取不同的数据采样策略,从而在无需完美配对视频样本的情况下,也能稳定的学习口型生成能力。对扩散过程的观察发现,扩散过程可以分为明确的几个阶段,早期主要聚焦于基础面部结构的生成,包括姿态和身份 ID 信息;中期主要生成音频驱动的唇部动作;后期细化细节和纹理。基于这个观察,提出的具体方案如下(图 7):
- 在早期,使用有限的伪配对视频数据(人物姿态基本一样,只有口型不一样的配对视频)为结构特征学习提供稳定的学习信号,同时保证了输入输出的姿态对齐。
- 在中期和后期,使用任意视频数据,引入更大规模且多样的视频,实现更好的纹理细节生成。
这个渐进式的训练方法与扩散模型的学习过程相对应,在不同阶段提供不同的训练信号,在没有完美配对数据的情况下也能稳定学习,使得模型可以高效泛化到很多不同的场景甚至非人的场景,并且保持较好的 ID 一致性。
渐进式噪声初始化
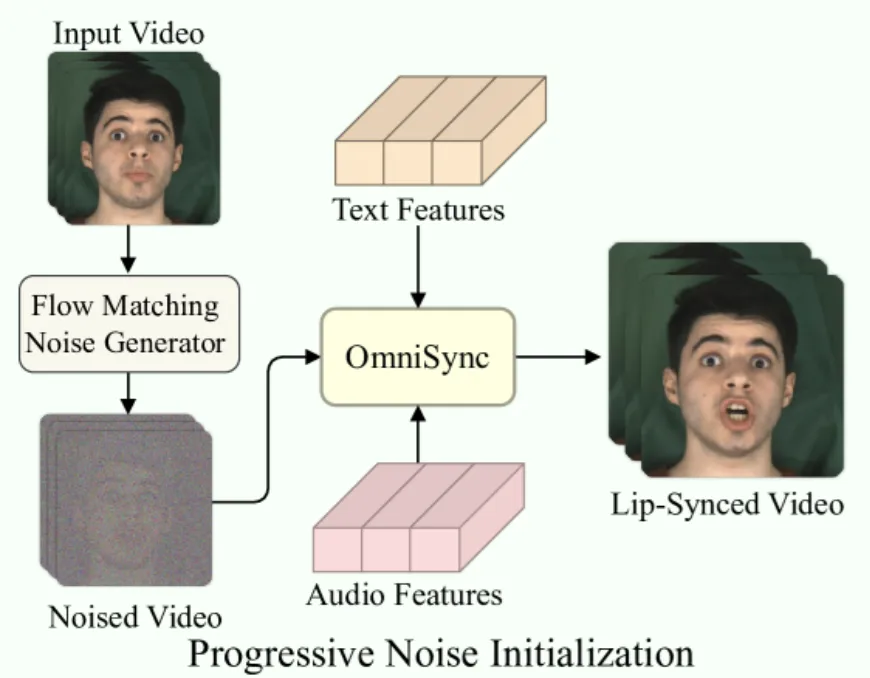
传统的扩散模型生成过程往往从纯随机噪声开始,这在前期会造成结构误差的累积,导致生成帧与原始视频在姿态和结构上的不一致。针对这一问题,OmniSync 在推理阶段采用了流匹配(Flow Matching)[10]的渐进式噪声初始化策略(图 8):不直接使用纯随机噪声作为起点,而是在源视频帧上注入一定程度的噪声,模拟扩散过程中的某个中间状态。这样一来,模型跳过了结构形成的早期阶段,直接继承了源帧的头部姿态和面部结构。随后只对后续的去噪阶段进行有条件处理(根据目标音频调整嘴部区域),这有效维持了原始帧的空间一致性,同时为嘴部区域的精细编辑留出足够的自由度。这个两阶段的生成过程极大地改善了姿态不一致和身份 ID 漂移的问题,使得最终输出既能准确同步音频,又保留了源视频中除嘴部以外的所有视觉信息。
动态时空无分类器引导(Dynamic Spatiotemporal Classifier-Free Guidance)
口型生成任务的另一大挑战是音频条件信号相对较弱:普通的无分类器引导(Classifier-Free Guidance,CFG)[11]若一味地增大权重,会在局部带来准确的嘴型但损害整体画质,反之权重太小又难以产生精确唇动。为解决这一矛盾,OmniSync 提出了动态时空无分类器引导(DS-CFG)机制,实现空间和时间上的自适应指导(图 9)。空间上,它通过高斯加权的方式将引导强度集中在嘴部及其周围区域,使得音频条件主要影响嘴部,而对其他面部区域影响极小。时间上,它在扩散过程的早期采用较强的音频引导,帮助形成正确的唇部结构,在后期则逐渐减弱引导强度,避免破坏细节纹理。这种时空自适应的引导策略使得模型能够在精确同步口型的同时,保持高质量的整体画面效果。
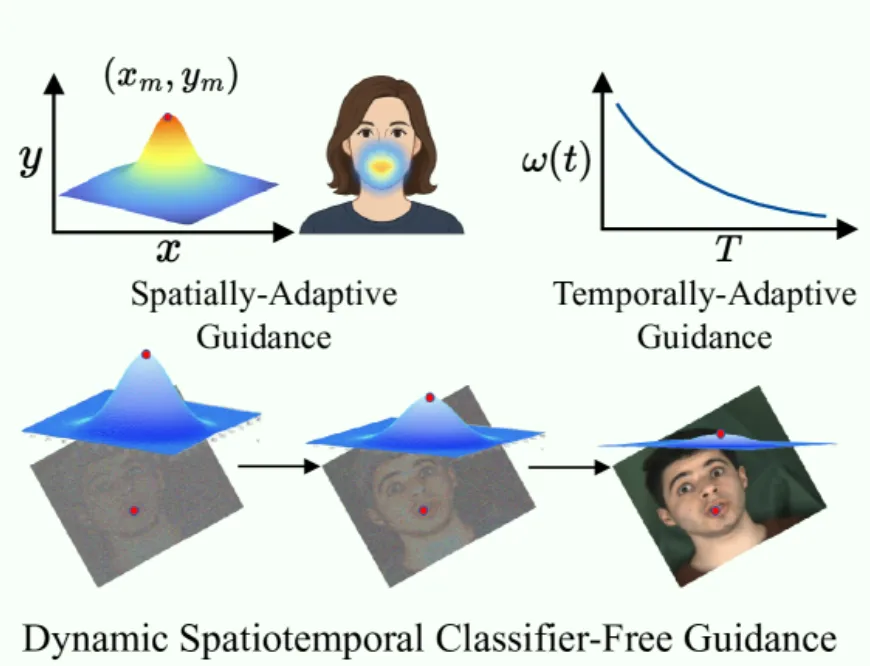
OmniSync提出了无掩码的扩散模型口型生成方法,很大程度上提升了人脸遮挡、大姿态等极端情景的口型同步效果,也能很好的保持 ID 一致性。而且因其无掩码方式降低了高质量配对数据的需求,能更高效利用更大规模的数据,从而更容易泛化到动画、玩偶等形象的生成。
小结
从上面两个算法可以看出,虽然都基于扩散模型,但针对口型生成的各项问题,都有不同的解法。比如视觉捷径问题,可以用固定掩码,也可以直接用无掩码的方式;时序连贯性问题,可以增加时序层,也可以用 3D VAE 来建模时序信息。行业里范式暂未统一,处于百家争鸣的阶段,但随着视频生成模型的范式趋于稳定,口型生成领域也将逐渐收敛到一个更加高效简洁的范式。
应用篇
音频驱动口型生成技术因其自动化和逼真度的潜力,正在多个领域展现出广阔的应用前景。
超写实数字人
音频驱动口型生成技术可以为在线客服、新闻播报、直播带货等场景的虚拟数字人形象提供实时、自然的口型同步,大幅提升交互真实感和亲和力。例如百度近期首秀的罗永浩数字人直播带货因其逼真的效果取得了惊人的 GMV 收益,咪咕视频在今年世俱杯期间推出的 AI 解说员刘建宏,也应用了口型生成技术。
影视制作
在影视制作中,角色的口型与语音同步是动画、特效和虚拟角色表现真实感的关键因素。传统方法依赖动画师、特效师手动调整每一帧的口型,耗时耗力且成本高昂。而音频驱动口型生成技术利用人工智能,自动将音频信号转化为匹配的口型动画,大幅提升了制作效率,在多个影视制作环节展现出重要价值。
- 自动口型动画生成:在3D动画电影(如《阿凡达》、《哪吒》)中,角色的口型需要精确匹配配音。传统方法需人工逐帧调整,而AI模型可直接从音频生成口型动作,大幅降低人工成本。
- 多语言适配:同一角色在不同国家地区上映时需重新配音,音频驱动口型生成技术能快速适配新语言的口型,降低本地化成本。
- 后期配音与影视修复:影视剧常因现场收音不佳或台词错误需后期配音,AI 口型生成技术可调整原有镜头口型,使其与新配音匹配,避免重拍。
娱乐互动
在娱乐互动场景中,音频驱动口型生成技术也有很丰富的应用场景,例如:
- NPC 语音口型同步:游戏中的非玩家角色(Non-Player Character, NPC)对话可通过音频驱动生成自然口型,提高沉浸感。
- 玩家语音驱动角色互动:在元宇宙或多人在线游戏中,玩家语音实时驱动角色口型,使交流更自然。
- 虚拟偶像表演:让虚拟偶像的表演(唱歌、说话)口型更加精准自然,提升粉丝体验。
- 个人内容制作玩法:让用户自己的视频唱出像明星一样好听的歌,口型精准匹配,体验 AI 视频娱乐新玩法。快手可灵和字节的即梦均推出了口型同步功能。
展望篇
近几年音频驱动口型生成技术取得了前所未有的进展,已经在不少工业级应用中发挥着价值。但在,随着用户要求的不断提高,还有诸多方面可以继续进化。
口型同步一致性
基于视频+音频输入的方法,大多是逐帧单独生成,这能满足小时级长时间生成而不产生 ID 漂移,但因缺乏帧间关联或时域关联度不够,口型同步一致性效果达不到完美效果,容易让人看出瑕疵。
另外有很多工作是基于音频驱动的肖像动画生成(Portrait Animation),即图像+音频 -> 视频,这类方法的口型同步一致性更高,但存在 ID 一致性、纹理细节、动态特征保持不足的问题。而且这类方法面临视频生成通用的问题:生成时长过短(往往不超过 20 秒),这在很大程度上限制了其应用范围。
视频生成技术这两年发展迅速,生成视频的 ID 一致性、时序连贯性和逼真度已经取得了相当不错的进展,与视频生成技术的结合甚至统一,将会是口型生成技术未来重要的发展方向。
实时性
目前的口型驱动方法,大多基于扩散模型,推理阶段的多步采样导致耗时较长,难以达到实时生成。MuseTalk [2]等结合 GAN 的方法,实时性较高,但也损失了一些口型同步的质量。所以相关领域还有很多探索空间,比如低清+超分,更高效的3D VAE, 高效扩散采样策略等。
更多形态
除了以语音驱动真人,还有很多研究工作在探索更多的形态。例如以音乐歌唱的驱动,动画风格、动物玩偶的口型生成,口型+身体姿态的联合生成等等。随着更大规模数据训练和更强的泛化能力,这些都将趋于成熟可用。
未来,口型同步一致性、实时性、形态多样性等问题的持续改进,必将推动音频驱动口型生成在超写实数字人主播、实时直播、低成本高质量影视制作、动画制作等多个领域发挥更大价值。
作者:朱宏吉审核:单华琦、邢刚、韩宇龙、梁先华
【参考资料】
[1] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492–28518. PMLR, 2023. 3
[2] Diederik P Kingma. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013. 2, 4
[3] KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Namboodiri, and CV Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the 28th ACM international conference on multimedia, pages 484–492, 2020. 1, 2, 3, 4, 5, 6, 8
[4] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 3, 5
[5] Yue Zhang, Minhao Liu, Zhaokang Chen, Bin Wu, Yubin Zeng, Chao Zhan, Yingjie He, Junxin Huang, and Wenjiang Zhou. Musetalk: Real-time high quality lip synchronization with latent space inpainting. arXiv preprint arXiv:2410.10122, 2024.
[6] Chunyu Li, Chao Zhang, Weikai Xu, Jinghui Xie, Weiguo Feng, Bingyue Peng, and Weiwei Xing. Latentsync: Audio conditioned latent diffusion models for lip sync. arXiv preprint arXiv:2412.09262, 2024.
[7] Ziqiao Peng, Jiwen Liu, Haoxian Zhang, Xiaoqiang Liu, Songlin Tang, Pengfei Wan, Di Zhang, Hongyan Liu, Jun He. OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers. arXiv preprint arXiv:2505.21448, 2025.
[8] William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023.
[9] Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021.
[10] Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow
matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022.
[11] Jonathan Ho, Tim Salimans. Classifier-free diffusion guidance. arXiv preprint
arXiv:2207.12598, 2022.
[12] Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, Jingchen Shu. IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech. arXiv preprint arXiv:2506.21619, 2025.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。