
NVIDIA 研究人员突破了大语言模型 (LLM) 推理领域长期存在的效率障碍,发布了Jet-Nemotron模型系列(2B 和 4B),其生成吞吐量比领先的全注意力机制 LLM 高出 53.6 倍,同时准确率与后者持平甚至超越。最重要的是,这一突破并非源于从零开始进行新的预训练,而是使用一种名为后神经架构搜索 (PostNAS)的新技术对现有预训练模型进行改造。这对于企业、从业者和研究人员都具有变革性的影响。
现代 LLM 对速度的要求
虽然当今最先进的 (SOTA) LLM,例如 Qwen3、Llama3.2 和 Gemma3,在准确性和灵活性方面树立了新的标杆,但它们的O(n²) 自注意力机制会产生高昂的计算和内存成本,尤其是在处理长上下文任务时。这使得它们的大规模部署成本高昂,并且几乎不可能在边缘或内存受限的设备上运行。迄今为止,人们一直在努力用更高效的架构(例如 Mamba2、GLA、RWKV 等)取代全注意力 Transformer,但一直难以缩小准确性差距。

PostNAS:一场高效的重大改造
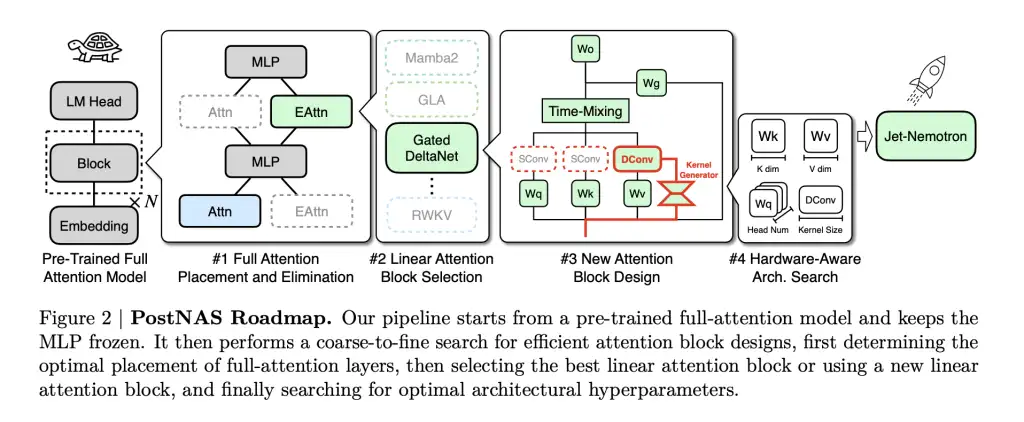
其核心创新在于PostNAS:一种专为高效改造预训练模型而设计的神经架构搜索管道。其工作原理如下:
- 冻结知识:从 SOTA 全注意力模型(例如 Qwen2.5)开始。冻结其 MLP 层——这可以保留模型学习到的智能,并大大降低训练成本。
- 精准替换:用 JetBlock 替代计算密集型全注意力机制(Transformers)。JetBlock是专为NVIDIA最新GPU设计的硬件高效线性注意力模块。
- 混合硬件感知设计:使用超级网络训练和集束搜索,自动确定最佳位置和最小全注意力层集,以保持关键任务(检索、数学、MMLU、编码等)的准确性。此步骤针对特定任务并具有硬件感知能力:搜索会最大化目标硬件的吞吐量,而不仅仅是参数数量。
- 扩展和部署:结果是一个混合架构LLM,它继承了原始模型的主干智能,但减少了延迟和内存占用。
JetBlock尤其值得关注:它引入了以输入为条件的动态因果卷积核(不同于之前线性注意力模块中的静态核),并消除了冗余卷积,从而简化了效率。借助硬件感知的超参数搜索,它不仅在吞吐量上与之前的线性注意力设计保持同步,而且实际上还提高了准确率。
Jet-Nemotron:性能数据
NVIDIA 技术论文中的关键指标令人震惊:
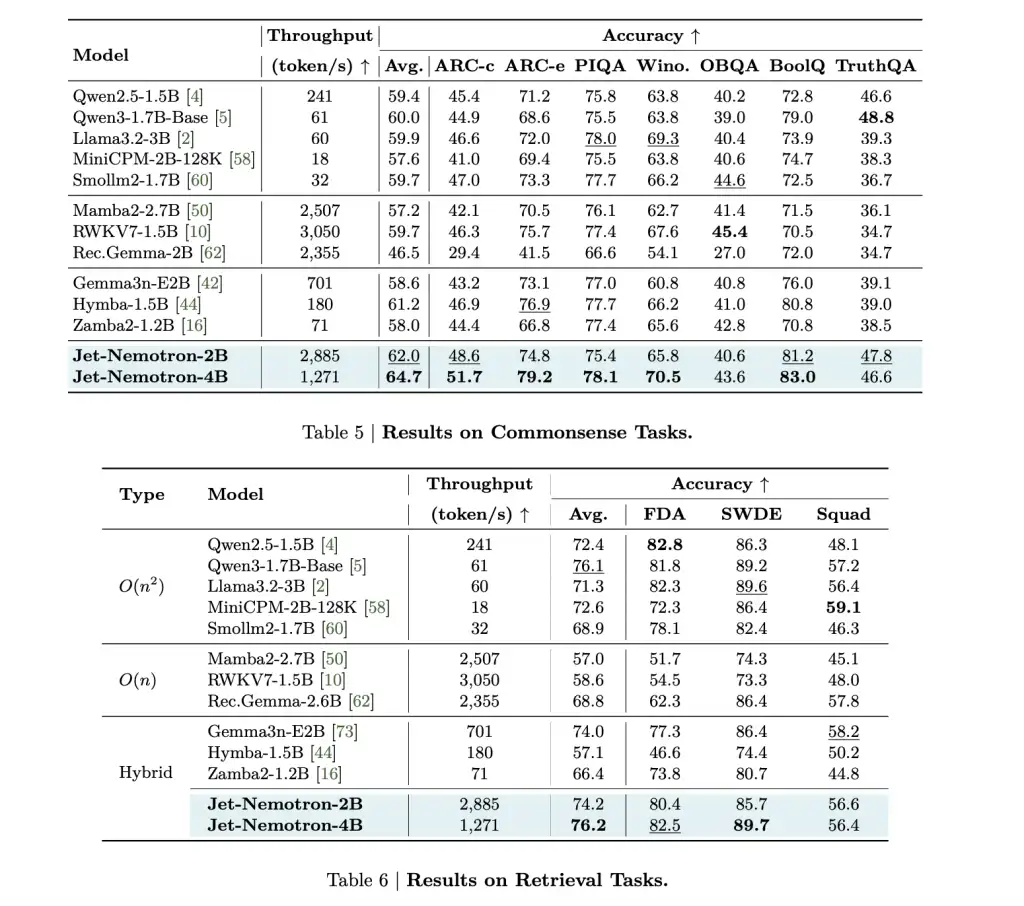
| 模型 | MMLU-Pro Acc. | 生成吞吐量(tokens/秒,H100) | KV 缓存大小(MB,64K 上下文) | 备注 |
|---|---|---|---|---|
| Qwen3-1.7B-Base | 37.8 | 61 | 7,168 | 全注意力基线 |
| Jet-Nemotron-2B | 39.0 | 2,885 | 154 | 吞吐量减少 47 倍,缓存减少 47 倍 |
| Jet-Nemotron-4B | 44.2 | 1,271 | 258 | 21 倍吞吐量,仍为 SOTA acc。 |
| Mamba2-2.7B | 8.6 | 2,507 | 80 | 全线性,精度低得多 |
| RWKV7-1.5B | 13.4 | 3,050 | 24 | 全线性,精度低得多 |
| DeepSeek-V3-Small(MoE) | — | — | — | 已激活 2.2B,总计 15B,降低 acc。 |
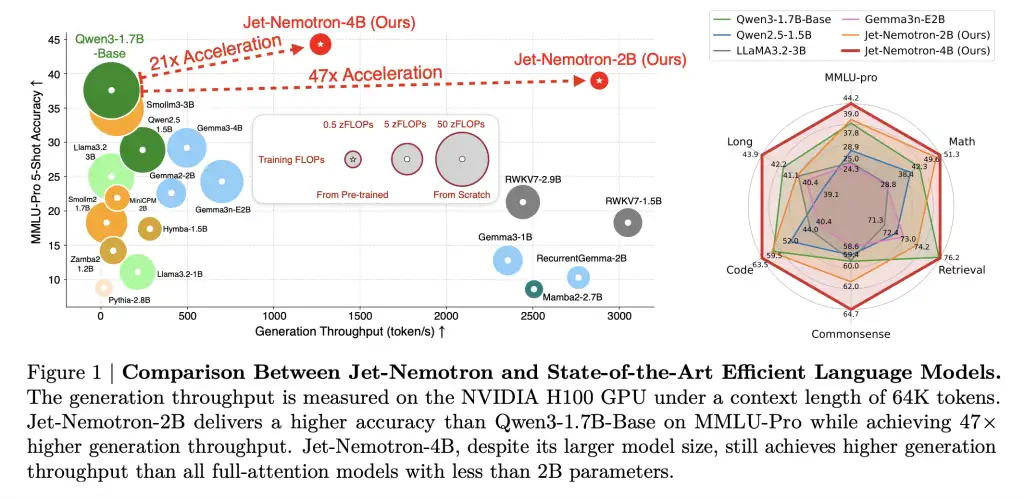
Jet-Nemotron-2B 在每个主要基准测试(数学、常识、编码、检索、长上下文)上都达到或超过 Qwen3-1.7B-Base,同时提供 47 倍更高的生成吞吐量。
这可不是个小数目:在 256K 上下文长度下,解码速度提升了 53.6 倍,这意味着相同数量的 token 的推理成本降低了 98% 。预填充速度提升也非常显著:在 256K 上下文长度下,解码速度提升了 6.14 倍。
内存占用减少了 47 倍(154MB 缓存 vs. Qwen3-1.7B-Base 的 7,168MB)。这对于边缘部署来说是一个颠覆性的变化:在 Jetson Orin 和 RTX 3090 上,Jet-Nemotron-2B 的速度分别比 Qwen2.5-1.5B 快8.84 倍和6.5 倍。
应用
对于企业领导者:更好的投资回报率
- 大规模推理现已经济实惠。53倍的吞吐量提升意味着,同等成本下,可以服务 53 倍以上的用户,或者将托管成本降低 98%。
- 运营效率大幅提升:延迟降低、批量增长、内存限制消失。云服务提供商可以以商品价格提供 SOTA AI。
- 人工智能商业模式重塑:曾经过于昂贵的任务(实时文档人工智能、长上下文代理、设备上的副驾驶)突然变得可行。
对于从业者来说:边缘上的 SOTA
- 无需再为量化、提炼或剪枝妥协而烦恼。Jet -Nemotron 的微型 KV 缓存 (154MB) 和 2B 参数适用于 Jetson Orin、RTX 3090 甚至移动芯片——无需再将负载转移到云端。
- 无需重新训练,无需更改数据管道:只需进行改造。您现有的 Qwen、Llama 或 Gemma 检查点可以升级,且不会降低准确性。
- 现实世界的人工智能服务(搜索、副驾驶、摘要、编码)现在是即时的和可扩展的。
对于研究人员来说:更低的门槛,更高的创新
- PostNAS 大幅降低了 LLM 架构创新的成本。与耗费数月和数百万美元进行预训练相比,架构搜索只需在冻结的主干模型上进行,耗时极短。
- 硬件感知 NAS 是未来趋势:Jet-Nemotron 流程将键值缓存大小(而不仅仅是参数)视为影响实际速度的关键因素。这是我们衡量和优化效率的范式转变。
- 社区可以更快地迭代:PostNAS 是一个快速测试平台。如果一个新的注意力模块在这里有效,那么它值得进行预训练;如果无效,则在投入大量资金之前将其过滤掉。
总结
Jet-Nemotron 和 JetBlock (代码在 GitHub 上)的开源意味着更广泛的 AI 生态系统现在可以改进其模型,以实现前所未有的效率。PostNAS并非一次性技巧:它是一个通用框架,可以加速任何 Transformer,从而降低未来突破的成本。
参考资料:
https://arxiv.org/abs/2508.15884v1
https://github.com/NVlabs/Jet-Nemotron
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61075.html