
艾伦人工智能研究所 (AI2) 发布了OLMoASR,这是一套开放的自动语音识别 (ASR)模型,可与 OpenAI 的 Whisper 等闭源系统相媲美。除了发布模型权重外,AI2 还发布了训练数据标识符、过滤步骤、训练方案和基准脚本——这在 ASR 领域是一次罕见的透明举措。这使得 OLMoASR 成为语音识别研究领域最热门、最具扩展性的平台之一。
为什么要开放自动语音识别ASR?
目前大多数语音识别模型(无论是 OpenAI、谷歌还是微软的)都只能通过 API 访问。虽然这些服务性能出色,但它们的运行方式却如同黑匣子:训练数据集不透明,过滤方法缺乏文档记录,评估协议也并非始终符合研究标准。
这种缺乏透明度的情况对可重复性和科学进步构成了挑战。研究人员无法验证结论、测试变体或将模型应用于新领域,除非他们自己重新构建大型数据集。OLMoASR 通过开放整个流程解决了这个问题。此次发布不仅是为了实现实用的转录,更是为了推动 ASR 走向更加开放、科学的基础。
模型架构和扩展
OLMoASR 使用 transformer 编码器-解码器架构,这是现代 ASR 中的主导范式。
- 编码器接收音频波形并产生隐藏的表示。
- 解码器根据编码器的输出生成文本标记。
这种设计与 Whisper 类似,但 OLMoASR 使实现完全开放。
该模型系列涵盖六种尺寸,均经过英语训练:
- tiny.en – 39M 参数,专为轻量级推理而设计
- base.en – 74M 个参数
- small.en – 244M 个参数
- medium.en – 769M 个参数
- large.en-v1 – 15亿个参数,经过44万小时的训练
- large.en-v2 – 15亿个参数,经过68万小时的训练
此范围允许开发人员在推理成本和准确率之间进行权衡。较小的模型适用于嵌入式设备或实时转录,而较大的模型则可以最大限度地提高研究或批量工作负载的准确率。
数据:从网页抓取到精选组合
OLMoASR 的核心贡献之一是开放发布训练数据集,而不仅仅是模型。
OLMoASR-Pool(约 300 万小时)
这个庞大的数据集包含弱监督语音,以及从网络上抓取的文字记录。它包含约300 万小时的音频和1700 万份文本记录。与 Whisper 的原始数据集一样,它包含噪声,包含未对齐的字幕、重复内容和转录错误。
OLMoASR-Mix(约 100 万小时)
为了解决质量问题,AI2 采用了严格的过滤:
- 对齐启发法确保音频和文字记录匹配
- 模糊重复数据删除,删除重复或低多样性示例
- 清理规则以消除重复的行和不匹配的文本
其结果是一个高质量的 1M 小时数据集,可提高零样本泛化能力– 这对于数据可能与训练分布不同的实际任务至关重要。
这种双层数据策略反映了大规模语言模型预训练的实践:使用大量嘈杂的语料库进行扩展,然后使用过滤后的子集进行细化以提高质量。
性能基准
AI2 使用LibriSpeech、TED-LIUM3、Switchboard、AMI 和 VoxPopuli等数据集,在短篇和长篇语音任务中对 OLMoASR 与 Whisper 进行了基准测试。
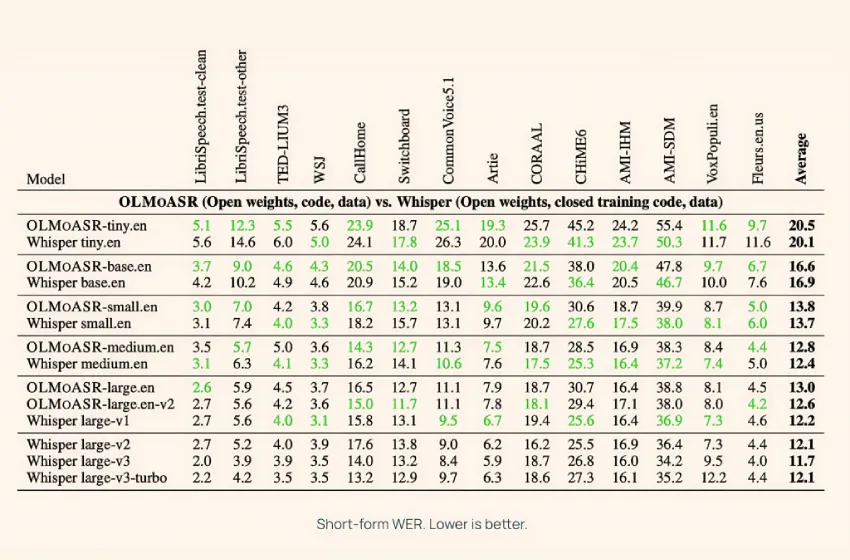

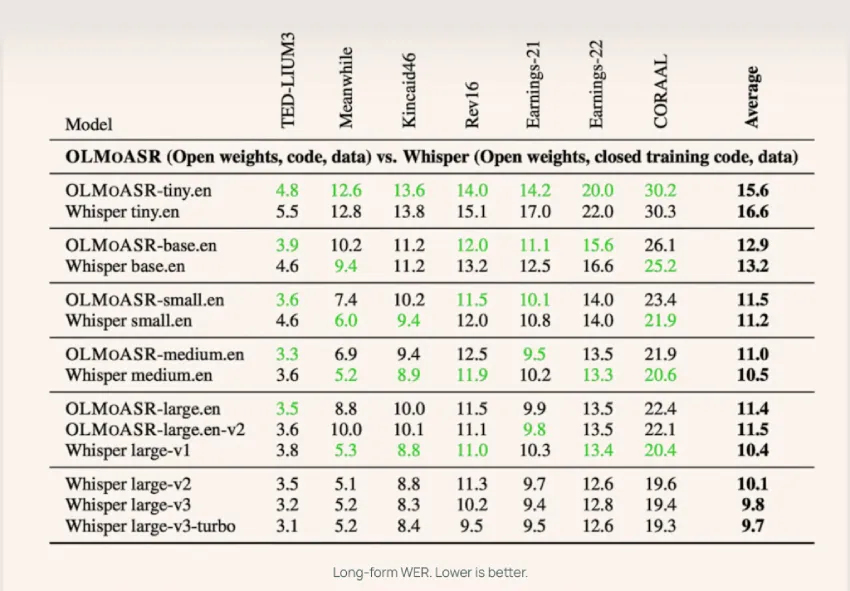
中型(769M)
- 短篇演讲的词错率 ( WER) 为 12.8%
- 长篇演讲的 WER 为 11.0%
这与 Whisper-medium.en 几乎持平,后者分别达到12.4%和10.5%。
大模型(15亿)
- large.en-v1(44 万小时):短版 WER 为 13.0%,Whisper large-v1 为 12.2%
- large.en-v2(68 万小时):WER 为 12.6%,差距缩小至 0.5% 以下
较小型
即使是微型和基础版本也具有竞争力:
- tiny.en:短格式 WER 约为 20.5%,长格式 WER 约为 15.6%
- base.en : 短格式 WER ~16.6%,长格式 WER ~12.9%
这使得开发人员可以根据计算和延迟要求灵活地选择模型。
微调和领域适应
由于 AI2 提供了完整的训练代码和方法,OLMoASR 可以针对专门领域进行微调:
- 医学语音识别:根据 MIMIC-III 或专有医院记录等数据集调整模型
- 法律转录:法庭音频或法律诉讼方面的培训
- 低资源口音:对 OLMoASR-Mix 中未充分涵盖的方言进行微调
这种适应性至关重要:当模型应用于包含特定领域术语的专业领域时,ASR 性能通常会下降。开放的流程使领域适应变得简单。
应用
OLMoASR 为学术研究和现实世界的人工智能开发开辟了激动人心的机会:
- 教育研究:研究人员可以探索模型架构、数据集质量和过滤技术之间的复杂关系,以了解它们对语音识别性能的影响。
- 人机交互:开发人员可以自由地将语音识别功能直接嵌入到会话式 AI 系统、实时会议转录平台和辅助功能应用程序中,而无需依赖专有 API 或外部服务。
- 多模式 AI 开发:与大型语言模型相结合,OLMoASR 可以创建先进的多模式助手,无缝处理语音输入并生成智能、情境感知的响应。
- 研究基准:训练数据和评估指标的开放可用性将 OLMoASR 定位为标准化参考点,使研究人员能够在未来的 ASR 研究中将新方法与一致、可重复的基线进行比较。
结论
OLMoASR 的发布使高质量的语音识别能够以透明性和可重复性为优先原则进行开发和发布。虽然这些模型目前仅限于英语,且训练过程中仍需要大量计算资源,但它们为未来的适应和扩展奠定了坚实的基础。此版本为开放式 ASR 的未来发展树立了清晰的参考点,并使研究人员和开发者能够更轻松地研究、基准测试和应用不同领域的语音识别模型。
参考资料:
https://huggingface.co/allenai/OLMoASR
https://github.com/allenai/OLMoASR
https://allenai.org/blog/olmoasr
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61301.html