
阿里云 Qwen 团队推出了Qwen3-ASR Flash,这是一种一体化自动语音识别 (ASR) 模型(可作为API 服务提供),建立在 Qwen3-Omni 的强大智能之上,可简化多语言、嘈杂和特定领域的转录,而无需处理多个系统。
关键功能
- 多语言识别:支持 11 种语言的自动检测和转录,包括英语和中文,以及阿拉伯语、德语、西班牙语、法语、意大利语、日语、韩语、葡萄牙语、俄语和简体中文 (zh)。这种广度使 Qwen3-ASR 能够在全球范围内使用,无需单独开发模型。
- 上下文注入机制:用户可以将任意文本(例如姓名、特定领域术语,甚至是无意义的字符串)粘贴到偏差转录中。这在富含习语、专有名词或不断发展的术语的场景中尤其有效。
- 强大的音频处理能力:在嘈杂环境、低质量录音、远场输入(例如远距离麦克风)以及歌曲或说唱等多媒体人声中均能保持出色性能。报告词错误率 (WER) 保持在 8% 以下,对于如此多样化的输入,这在技术上令人印象深刻。
- 单模型简单性:消除了维护不同语言或音频上下文模型的复杂性——一个模型通过 API 服务来统治它们。
用例涵盖教育科技平台(讲座捕捉、多语言辅导)、媒体(字幕、画外音)和客户服务(多语言 IVR 或支持转录)。
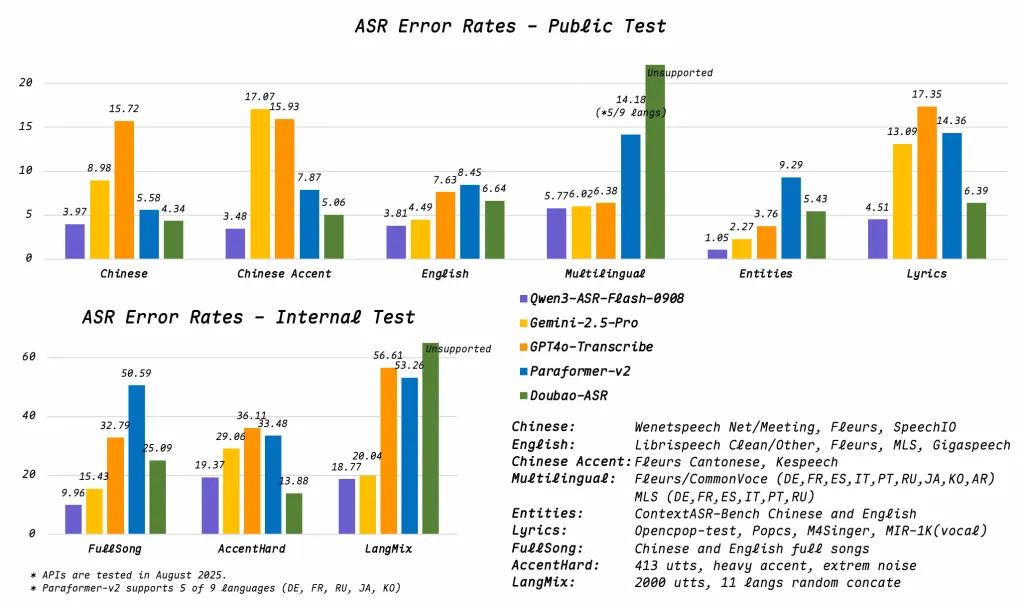

技术评估
- 语言检测 + 转录
自动语言检测功能可让模型在转录前确定语言——这对于混合语言环境或被动音频采集至关重要。这减少了手动选择语言的需求,并提高了可用性。 - 上下文标记注入:
将文本粘贴为“上下文”会使识别偏向预期词汇。从技术上讲,这可以通过前缀调整或前缀注入来实现——在输入流中嵌入上下文以影响解码。这是一种灵活的方法,无需重新训练模型即可适应特定领域的词汇。 - 复杂场景下 WER < 8%
Qwen3-ASR 在音乐、说唱、背景噪音和低保真音频中保持低于 8% 的 WER,使其在开放式识别系统中处于领先地位。相比之下,在清晰语音上,稳健模型的目标 WER 为 3-5%,但在嘈杂或音乐环境中,性能通常会显著下降。 - 多语言覆盖:
支持 11 种语言,包括表意汉语以及阿拉伯语和日语等音系结构各异的语言,这表明我们拥有丰富的多语言训练数据和跨语言建模能力。处理声调语言(普通话)和非声调语言并非易事。 - 单模型架构
,操作优雅:只需部署一个模型即可完成所有任务。这减轻了运维负担,无需动态切换或选择模型。所有功能均在统一的 ASR 流水线中运行,并内置语言检测功能。
结论
Qwen3-ASR Flash(以 API 服务形式提供)是一款技术卓越、易于部署的 ASR 解决方案。它提供了一个罕见的组合:多语言支持、上下文感知转录和抗噪识别,所有这些都集成在一个模型中。
更多详细信息请访问:https://qwen.ai/blog?id=41e4c0f6175f9b004a03a07e42343eaaf48329e7&from=research.latest-advancements-list
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61478.html