
Liquid AI 发布了 LFM2-VL-3B,这是一个用于图像文本到文本任务的 3B 参数视觉语言模型。它扩展了 LFM2-VL 系列,使其超越了 450M 和 1.6B 版本。该模型旨在提高准确率,同时保留了 LFM2 架构的速度优势。该模型已在 LEAP 和 Hugging Face 平台上基于 LFM Open License v1.0 许可证发布。
模型概述与接口
LFM2-VL-3B 接受交错的图像和文本输入,并生成文本输出。该模型提供类似 ChatML 的模板。处理器会在模板中插入 <image> 标记,该标记将在运行时替换为编码后的图像令牌。默认文本上下文长度为32,768个令牌。这些细节有助于开发者复现评估结果,并将模型集成到现有多模态管道中。
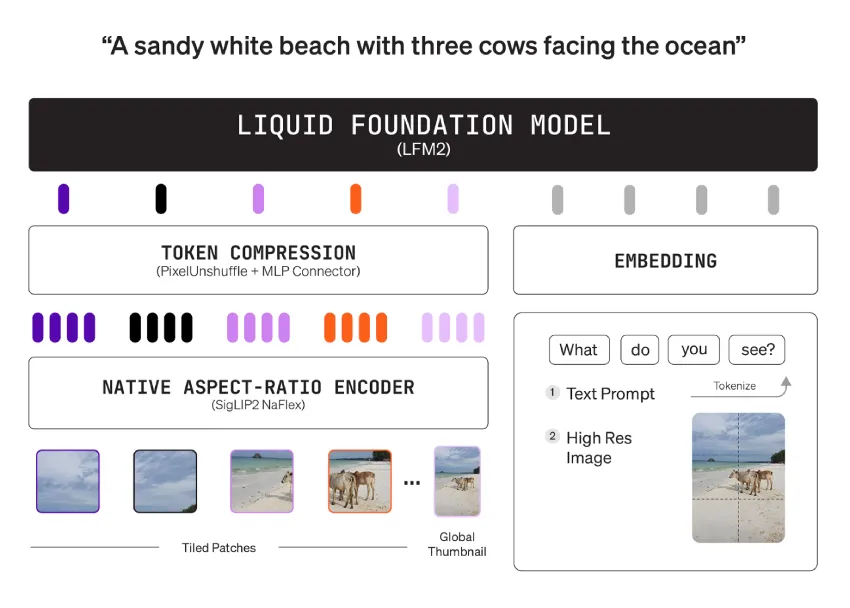

架构
该堆栈将语言塔、形状感知视觉塔和投影器配对。语言塔采用 LFM2-2.6B,这是一个混合卷积加注意力机制的主干网络。视觉塔采用 4 亿参数的 SigLIP2 NaFlex,它保留了原始宽高比并避免了失真。连接器是一个带有像素反混洗功能的双层多层感知器 (MLP),它会在与语言空间融合之前压缩图像标记。这种设计允许用户限制视觉标记的预算,而无需重新训练模型。
编码器可处理高达 512×512 的原始分辨率。较大的输入会被分割成互不重叠的 512×512 图像块。缩略图路径在平铺过程中提供全局上下文。高效的标记映射已通过具体示例记录:256×384 的图像映射到 96 个标记,1000×3000 的图像映射到 1,020 个标记。模型卡提供了用于控制最小和最大图像标记以及平铺开关的用户控件。这些控件可在推理时调整速度和质量。
推理设置
Hugging Face 模型卡提供了推荐参数。文本生成使用温度 0.1、最小 p 值 0.15 和重复惩罚值 1.05。视觉设置使用最小图像标记 64、最大图像标记 256 和启用图像分割。处理器自动应用聊天模板和图像标记。示例使用AutoModelForImageTextToText和AutoProcessor ,精度为bfloat16。
它是如何训练的?
Liquid AI 描述了一种分阶段的方法。团队进行联合中期训练,随着时间的推移调整文本与图像的比例。然后,该模型进行监督微调,重点关注图像理解。数据源是大规模开放数据集以及用于任务覆盖的内部合成视觉数据。
基准测试
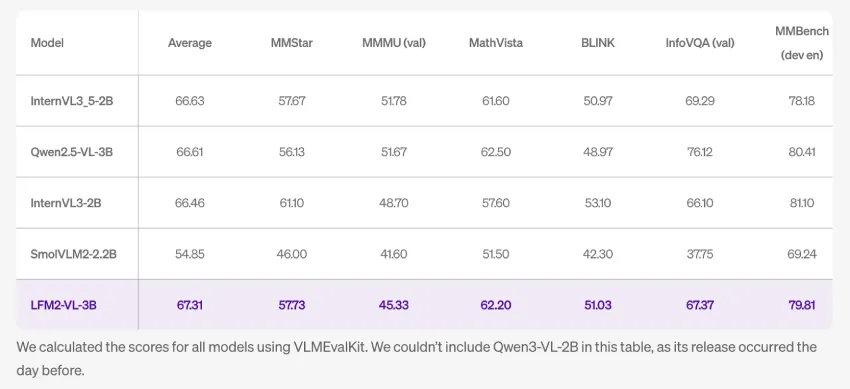
研究团队报告了轻量级开放式 VLM 的竞争性结果。在 MM-IFEval 上,该模型得分达到 51.83。在 RealWorldQA 上,该模型得分达到 71.37。在 MMBench dev en 上,该模型得分达到 79.81。POPE 得分为 89.01。表格中指出,其他系统的得分是使用 VLMEvalKit 计算的。表格中未包含 Qwen3-VL-2B,因为该系统发布时间比 VLMEvalKit 早一天。
语言能力仍然接近 LFM2-2.6B 主干。研究团队在 GPQA 上引用了 30%,在 MMLU 上引用了 63%。当感知任务包含知识查询时,这一点至关重要。该团队还表示,其多语言视觉理解能力已扩展到英语、日语、法语、西班牙语、德语、意大利语、葡萄牙语、阿拉伯语、中文和韩语。
为什么边缘用户应该关心?
该架构将计算和内存保持在较小的设备预算范围内。图像令牌可压缩且受用户约束,因此吞吐量可预测。SigLIP2 400M NaFlex 编码器保留了宽高比,有助于实现细粒度感知。投影仪减少了连接器处的令牌数量,从而提高了每秒令牌数。研究团队还发布了用于设备运行时的 GGUF 版本。这些特性对于需要本地处理和严格数据边界的机器人、移动和工业客户非常有用。
关键要点
- 紧凑型多模态堆栈:3B 参数 LFM2-VL-3B 将 LFM2-2.6B 语言塔与 400M SigLIP2 NaFlex 视觉编码器和 2 层 MLP 投影器配对,用于图像-token 融合。NaFlex 保留原始宽高比。
- 分辨率处理和令牌预算:图像原生运行分辨率最高可达 512×512,更大的输入会被平铺成互不重叠的 512×512 图像块,并通过缩略图路径提供全局上下文。已记录的令牌映射包括 256×384 → 96 个令牌和 1000×3000 → 1,020 个令牌。
- 推理接口:带有哨兵的类似 ChatML 的提示
<image>、默认文本上下文 32,768 个标记、推荐的解码设置以及用于图像分割的处理器级控制可实现可重复的评估并轻松集成到多模式管道中。 - 实测性能:报告结果包括 MM-IFEval 51.83、RealWorldQA 71.37、MMBench-dev-en 79.81 和 POPE 89.01。来自主干网的纯语言信号约占 30% GPQA 和 63% MMLU,这对于混合感知加知识的工作负载非常有用。
总结
LFM2-VL-3B 是边缘多模态工作负载的实用步骤,3B 堆栈将 LFM2-2.6B 与 400M SigLIP2 NaFlex 编码器和高效投影仪配对,从而降低图像令牌数量,实现可预测的延迟。采用 512 x 512 平铺和令牌上限的原生分辨率处理可提供确定性的预算。在 MM-IFEval、RealWorldQA、MMBench 和 POPE 上报告的得分对于此规模而言具有竞争力。开放权重、GGUF 构建和 LEAP 访问减少了集成阻力。总体而言,这是一个边缘就绪的 VLM 版本,具有清晰的控制和透明的基准测试。
参考资料:
- https://huggingface.co/LiquidAI/LFM2-VL-3B
- https://www.liquid.ai/blog/lfm2-vl-3b-a-new-efficient-vision-language-for-the-edge
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/62500.html