
随着推理密集型任务需求的增长,大型语言模型 (LLM) 越来越有望生成更长的序列或并行推理链。然而,推理时间性能不仅受限于生成的令牌数量,还严重受限于键值 (KV) 缓存的内存占用。在最近的一篇论文中,来自 NVIDIA 和爱丁堡大学的研究人员提出了Dynamic Memory Sparsification (DMS,动态内存稀疏化) ——一种数据高效、易于改造的方法,它可以压缩键值缓存,并在不降低模型精度的情况下实现推理时间的超大规模扩展。
瓶颈:Transformer 推理中的 KV 缓存
基于 Transformer 的模型(例如 GPT、LLaMA 和 Qwen)使用键值缓存来存储过去的 token 表征,以便进行自回归生成。该缓存会随着序列长度和宽度(并行线程)线性增长,从而消耗大量 GPU 内存,并由于频繁的内存访问而导致推理速度变慢。
现有的键值缓存优化技术要么依赖于无需训练的启发式算法(例如基于注意力权重的令牌驱逐),要么需要大量的训练后改进,例如动态内存压缩 (DMC)。这两种方法都存在明显的缺点:前者往往会损害准确性,而后者计算成本高昂。
DMS:不折不扣的压缩

动态内存稀疏化(DMS) 采用一种混合方法解决了这些限制:它像传统的剪枝方法一样对键值缓存进行稀疏化,但训练开销极小(约 1,000 步),并且采用了延迟移除技术,即在标记待移除后暂时保留这些标记。这种设计可以保留重要的上下文信息,并避免准确率急剧下降。
其核心思想是使用基于 Gumbel-Sigmoid 的采样机制,使驱逐决策在训练过程中具有可微分性。预测未来将被驱逐的标记在被丢弃之前,会在滑动窗口期内保持可用,从而使模型能够更有效地吸收其信息价值。
使用最少数据进行高效改造
与需要数千个训练步骤和复杂的梯度优化的 DMC 不同,DMS 不会为每个注意力头引入额外的参数。它重用了注意力机制的一小部分(单个神经元)来预测驱逐。这使得 DMS 成为无需架构更改即可改造现有模型的理想选择。
实证结果表明,仅需1K 个训练步骤,DMS 即可实现8× KV 缓存压缩,从而在推理任务中保持甚至提高模型性能。
基准测试结果:无需扩展成本即可扩展性能
研究团队在推理密集型基准上对 DMS 进行了测试,例如:
- AIME 2024(高等数学)
- MATH 500(数学问题解决)
- GPQA Diamond(硬科学 QA)
- LiveCodeBench(代码生成)
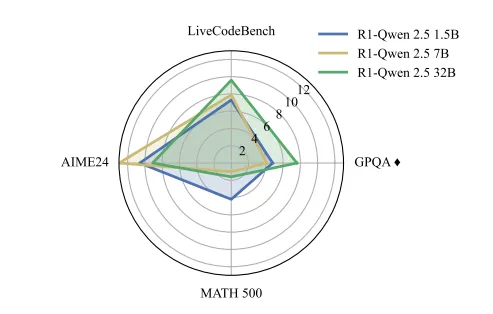
在不同的模型大小(Qwen-R1 1.5B、7B 和 32B)中,DMS在 AIME 上的精确匹配性能提高了 9.1 分,在 GPQA 上的精确匹配性能提高了 7.6 分,在 LiveCodeBench 上的精确匹配性能提高了 9.6 分,所有这些都在相同的内存和计算预算下进行。
与 Quest 和 TOVA 等性能最佳的基线相比,DMS 在KV 缓存读取效率(运行时代理)和峰值内存使用率方面始终优于它们,实现了更好的帕累托前沿。
通用实用程序
DMS 在非推理任务中也表现出色。在 MMLU、GSM8K 和 HellaSwag 等短上下文基准测试中,DMS 在高达4 倍的压缩率下仍能保持性能,且性能下降极小(约 3.5 分)。在诸如 Needle-in-a-Haystack 和变量跟踪等长上下文任务中,DMS 甚至超越了原始模型,这表明其在缓解长序列中信息过度压缩等问题方面具有潜力。
结论
总而言之,动态内存稀疏化 (DMS) 提供了一种实用且可扩展的解决方案,可提升基于 Transformer 的语言模型的推理时间效率。通过以最少的再训练次数智能压缩键值缓存,DMS 使模型能够对更长的序列进行推理或并行推理,而不会增加运行时间或内存需求。它在一系列推理和通用任务中持续提升的性能凸显了其多功能性和有效性。随着 LLM 越来越多地部署在资源受限的环境中,DMS 提供了一条极具吸引力的前进之路——在压缩率、准确性和易于集成性之间取得平衡,以应对实际的推理工作负载。
论文:https://arxiv.org/abs/2506.05345
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58829.html