
近年来,基于大语言模型(LLM)的零样本文本转语音(Zero-shot TTS)系统发展迅速,已经能够在仅提供几秒参考音频的情况下,合成自然、清晰、且具有说话人风格的语音。然而,即便是最先进的系统,在真实使用场景中仍然频繁出现一些“局部灾难性错误”:某个词突然读错、不自然的停顿或拖长、亦或是重复、截断,甚至语义对不齐。这些问题往往只发生在语音的某一小段,但却会严重破坏整体听感。
最近,西工大音频语音与语言处理研究组(ASLP@NPU)与喜马拉雅珠峰实验室合作的论文 “FPO: Fine-grained Preference Optimization Improves Zero-shot Text-to-Speech” 被语音领域顶级期刊IEEE TASLP录用,该论文针对上述问题开展了深入研究,本文提出了一种新的偏好优化方法,首次将 TTS 的偏好学习从“整句级别(utterance-level)”推进到“token / 片段级别(fine-grained)”。FPO 不再平均地优化整段语音,而是精准定位并修复真正出问题的片段,从而在显著提升鲁棒性的同时,大幅提高数据利用效率。
论文题目:FPO: Fine-grained Preference Optimization Improves Zero-shot Text-to-Speech
作者列表:姚继珣,杨宇光,潘宇,冯源,宁子谦,叶剑豪,周鸿斌,谢磊
合作单位:喜马拉雅珠峰实验室
论文原文:https://arxiv.org/pdf/2502.02950
Demo:https://yaoxunji.github.io/fpo/
背景动机
语音合成(Text-to-Speech, TTS)一直是语音与人工智能领域的重要研究方向。近年来,大语言模型(LLM)的成功进一步推动了语音合成范式的转变。一类新的 TTS 系统开始借鉴语言建模的思想,将语音离散化为 token,并将语音生成建模为一个“下一个 token 预测”的问题。这种基于神经编解码器(Neural Codec)的语言模型式 TTS,使系统具备了类似文本大模型的上下文学习能力,只需几秒钟的参考语音,便可以在不做任何微调的情况下合成目标说话人的语音,即所谓的零样本语音合成(Zero-shot TTS)。
然而,随着模型规模和训练数据的不断扩大,零样本 TTS 的主要瓶颈逐渐不再是“整体听起来像不像人”,而是“在真实使用场景中是否足够稳定”。即便是当前最先进的系统,在长句、复杂文本或跨语言场景下,仍然频繁出现影响听感的问题,例如个别词的误读、不自然的停顿、异常的拖音,甚至重复和截断等现象。这类问题往往只发生在语音的某一小段,但却会显著破坏整体体验,使得听者对系统的可靠性产生质疑。
为了进一步提升生成语音与人类感知的一致性,研究者开始引入基于人类偏好的优化方法。受到 ChatGPT 等系统中强化学习对齐(RLHF)和直接偏好优化(DPO)成功经验的启发,近期工作尝试通过成对偏好数据来对零样本 TTS 进行后训练,使模型更倾向于生成人类更“喜欢”的语音。这类方法通常在句子级别收集偏好标注,通过比较两条完整语音,判断哪一条在整体上更自然、更清晰,从而引导模型更新参数,在全局层面对齐人类审美与听感。
尽管这种整句级别的偏好优化在提升整体音质和说话人一致性方面取得了一定成效,但它与语音合成中错误的实际分布形式存在明显错位。大量影响听感的错误并非系统性的全局问题,而是集中出现在某些局部片段中:前后语音衔接不自然、某个音节发音突变、停顿位置不合理,或是语义与音素对齐失败导致的重复和漏读。使用整句偏好信号进行优化时,模型需要对整段语音计算损失,即便其中大部分片段已经生成得足够好,这不仅降低了优化效率,还可能对原本正确的部分产生不必要的扰动。正是在这样的背景下,本文提出了一种细粒度偏好优化的思路,试图从“整体对齐”转向“精准修复”。与传统方法不同,FPO 不再假设一句语音是“整体好”或“整体坏”,而是通过精细化标注和选择性优化,将学习信号集中到真正存在问题的语音片段上。这一转变不仅更符合语音错误的实际分布规律,也为提升零样本 TTS 的鲁棒性和数据效率提供了一条新的路径。
解决方案
本文提出的 Fine-grained Preference Optimization(FPO)并不是对现有偏好学习方法的小幅改动,而是围绕“语音错误具有强局部性”这一观察,对偏好数据构建与优化目标进行了系统性的重设计。整体而言,FPO 仍然基于神经编解码器驱动的零样本 TTS 框架,在不改变模型结构和推理方式的前提下,通过更精细的偏好标注与选择性损失计算,实现对问题片段的定向修复。
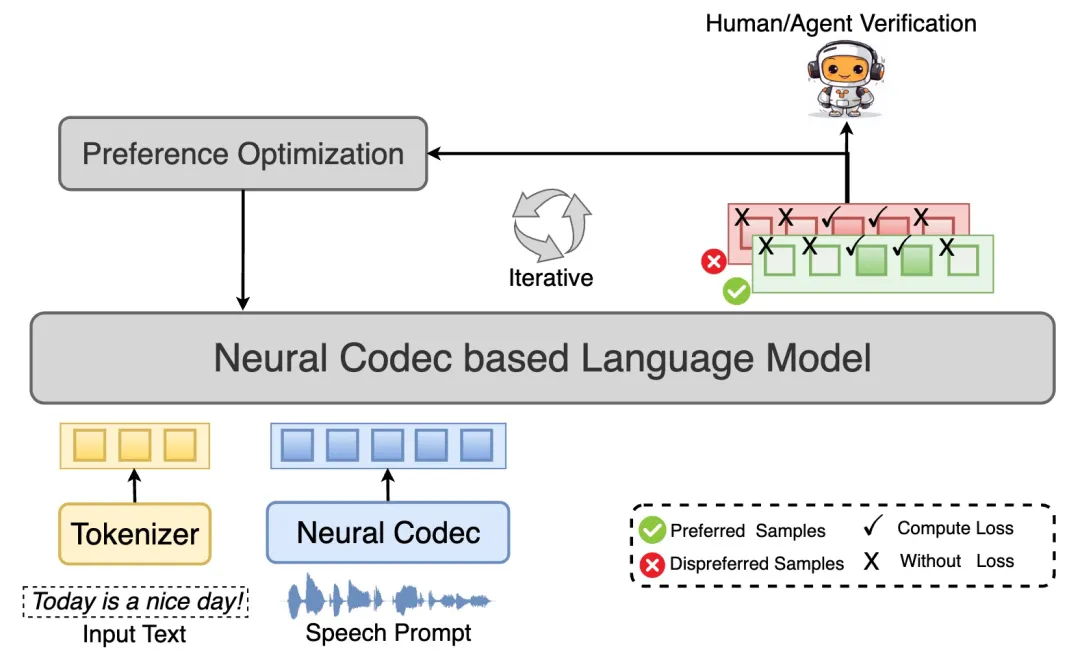

1. 模型架构: 如图1所示,FPO 作用于当前主流的 neural codec–based TTS 系统。这类系统首先使用神经编解码器将连续语音映射为离散的语音 token,并将语音合成过程转化为一个条件语言建模问题:模型在文本和参考语音提示的条件下,自回归地预测后续语音 token。由于语音已经被表示为离散序列,这为后续在 token 级别进行偏好建模与损失选择提供了天然的操作空间
2. 偏好数据构建
FPO 设计了一套精细化的采样与筛选流程
- 对于同一段文本和同一位说话人,系统会在不同采样超参数下多次生成候选语音,从而构建一个具有多样性的生成样本集合
- 引入一种综合打分机制,结合可懂度、音质、说话人相似度以及时长等多个自动评价指标,对生成语音进行排序,并从中选出差异足够明显的偏好对
在获得句子级偏好对之后,FPO 并未止步于传统的“哪一句更好”,而是进一步引入了细粒度的错误分析与标注。通过对大量生成样本的观察,将常见的局部错误归纳为两大类:一类是时间建模相关的问题,例如发音突变、不自然的停顿或异常静音,这些错误通常局限在较短的时间窗口内;另一类是语义与音素对齐失败导致的问题,如重复或截断,一旦出现往往会影响后续较长一段语音。针对不同类型的错误,FPO 采用了不同的标注策略,以确保被标记为“有问题”的 token 能够准确覆盖实际听感中出现异常的区域。
选择性训练策略
- 模型在前向传播时仍然对整段语音进行建模,保证上下文建模的完整性
- 在计算偏好损失时,仅对被标注为问题区域的 token 进行梯度更新,而对已经生成良好的片段完全跳过
这种“全序列建模、局部损失计算”的方式,使得优化信号高度集中于真正需要修复的部分,避免了传统整句偏好优化中梯度被大量无关 token 稀释的问题。
实验验证
为了验证 FPO 的有效性,我们在多个当前主流的零样本 TTS 系统上进行了系统实验,包括 CosyVoice、CosyVoice2 以及近期提出的 Llasa。所有方法均在相同的基础模型和数据设置下进行对比,重点考察语音的可懂度、自然度以及系统在真实使用场景中的鲁棒性。
从表1中的客观指标来看,FPO 在可懂度相关的错误率上取得了最稳定、也是幅度最大的改进。无论是在中文测试集上使用的字符错误率(CER),还是英文测试集上的词错误率(WER),FPO 都明显优于现有的多种偏好优化方法 。在 CosyVoice 模型上,FPO 将中文 CER 几乎降低了一半,同时在英文 WER 上也取得了超过三成的下降幅度。即便是在性能更强、原始错误率已经较低的 CosyVoice2 和 Llasa 上,FPO 仍然能够持续带来额外收益。这一结果说明,细粒度偏好优化并不是只对“弱模型”有效,而是在高性能系统中同样能够精准发现并修复残余错误。

同时我们将出现严重可懂度问题或音质显著下降的样本定义为 bad case,用以衡量系统在复杂场景下的稳定性。实验结果显示,FPO 在所有测试设置下都取得了最低的 bad case 比例。例如,在 CosyVoice 系统上,bad case 比例从原始模型的 21% 降低到了 9%;在 CosyVoice2 和 Llasa 上,这一比例也分别被压缩到了个位数或接近个位数的水平。相比之下,传统的整句级偏好优化方法虽然在整体指标上有所改善,但在降低 bad case 方面的效果并不稳定。
在主观评测方面,采用了自然度平均意见分(NMOS)以及 ABX 偏好测试,对不同系统生成的语音进行对比。结果显示,FPO 在所有 backbone 上都取得了最高或并列最高的 NMOS 分数,且提升幅度具有统计显著性。

ABX 测试进一步验证了这一趋势。当听者在相同文本和说话人条件下比较两条语音时,FPO 生成的语音被选为“更自然”的比例显著高于基线模型和其他偏好优化方法。这一结果表明,FPO 带来的提升不仅体现在指标上,也真实反映在人的主观感知中。

最后,除了性能提升,FPO 还在数据效率上展现出明显优势。在小规模偏好数据实验中,FPO 仅使用约三分之一甚至更少的训练样本,就能达到甚至超过其他方法在大规模数据下的效果。例如,在仅使用 200 条偏好样本的情况下,FPO 在高难度测试集上的错误率已经接近甚至优于其他方法在 600 条样本时的表现;在 bad case 比例上,FPO 的收敛速度也明显更快。这说明细粒度偏好优化并非“标注更细、成本更高”,反而在整体上更加高效。

综合来看,FPO 在实验中的优势并非来自更复杂的模型或更激进的训练策略,而是源于其对优化目标的重新定义。传统方法试图用一句话的偏好信号去修正整段语音,而 FPO 则明确区分“哪里已经够好,哪里还需要修”,避免了对良好生成片段的无效甚至有害更新。
样例请参考:https://yaoxunji.github.io/fpo/
参考文献
[1] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in neural information processing systems. vol. 33, pp. 1877–1901, 2020.
[2] A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan et al., “The llama 3 herd of models,” arXiv e-prints, pp. arXiv–2407, 2024
[3] C. Wang, S. Chen, Y. Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li et al., “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023
[4] Z. Du, Q. Chen, S. Zhang, K. Hu, H. Lu, Y. Yang, H. Hu, S. Zheng, Y. Gu, Z. Ma et al., “CosyVoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens,” arXiv preprint arXiv:2407.05407, 2024.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。