
Liquid AI 推出了 LFM2.5,这是基于 LFM2 架构构建的新一代小型基础模型,专注于设备和边缘部署。该模型系列包括 LFM2.5-1.2B-Base 和 LFM2.5-1.2B-Instruct,并支持日语、视觉语言和音频语言变体。它以开源权重的形式发布在 Hugging Face 上,并通过 LEAP 平台对外开放。
架构与训练方案
LFM2.5 保留了 LFM2 的混合架构,该架构专为在 CPU 和 NPU 上实现快速高效的内存推理而设计,并扩展了数据和后训练流程。针对 12 亿参数主干模型的预训练规模从 10T 扩展到 28T 个 token。指令变体随后接受监督式微调、偏好对齐以及大规模多阶段强化学习,重点关注指令跟踪、工具使用、数学运算和知识推理。
文本模型在十亿规模下的性能
LFM2.5-1.2B-Instruct 是主要的通用文本模型。Liquid AI 团队报告了该模型在 GPQA、MMLU Pro、IFEval、IFBench 以及多个函数调用和编码测试套件上的基准测试结果。该模型在 GPQA 上的得分为 38.89,在 MMLU Pro 上的得分为 44.35。相比之下,其他 10 亿级开源模型,例如 Llama-3.2-1B Instruct 和 Gemma-3-1B IT,在这些指标上的得分明显更低。
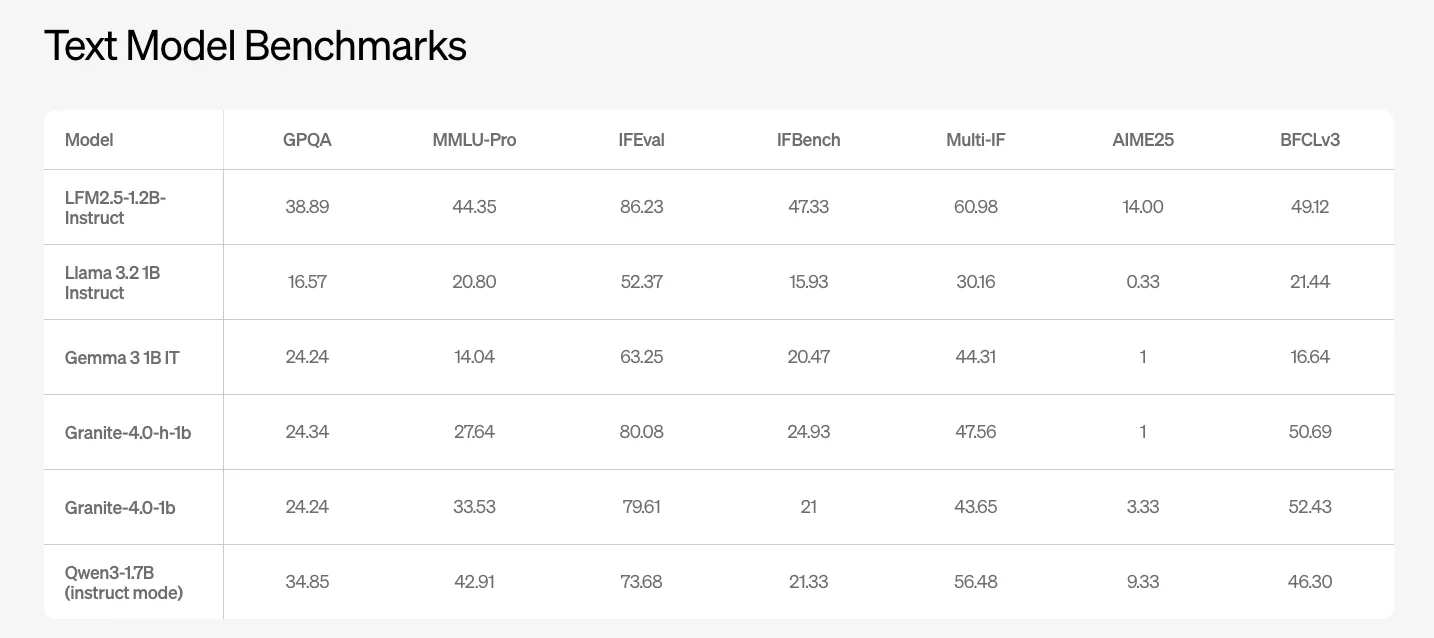

在针对多步指令跟踪和函数调用质量的 IFEval 和 IFBench 测试中,LFM2.5-1.2B-Instruct 的得分分别为 86.23 和 47.33。这些数值均优于上述 Liquid AI 表格中的其他 1B 级基线。
日版优化版本
LFM2.5-1.2B-JP是一个基于同一骨干网络构建的日语优化文本模型。它针对 JMMLU、M-IFEval(日语版)和 GSM8K(日语版)等任务进行优化。该模型在日语任务上优于通用指令模型,并且在这些本地化基准测试中,其性能可与 Qwen3-1.7B、Llama 3.2-1B Instruct 和 Gemma 3-1B IT 等其他小型多语言模型相媲美,甚至更胜一筹。
面向多模态边缘工作负载的视觉语言模型
LFM2.5-VL-1.6B 是该系列中更新的视觉语言模型。它以 LFM2.5-1.2B-Base 为语言骨干,并新增了一个用于图像理解的视觉塔。该模型在一系列视觉推理和 OCR 基准测试中进行了优化,包括 MMStar、MM IFEval、BLINK、InfoVQA、OCRBench v2、RealWorldQA、MMMU 和多语言 MMBench。LFM2.5-VL-1.6B 在大多数指标上都优于之前的 LFM2-VL-1.6B,旨在用于文档理解、用户界面阅读以及边缘约束下的多图像推理等实际应用任务。
具有母语语音生成的音频语言模型
LFM2.5-Audio-1.5B 是一种原生音频语言模型,支持文本和音频的输入输出。它采用音频到音频模型,并使用音频去标记器。据称,在硬件资源有限的情况下,该去标记器在相同精度下比之前的基于 Mimi 的去标记器快八倍。
该模型支持两种主要的生成模式。交错生成模式专为实时语音对话代理而设计,尤其适用于延迟较为敏感的应用场景。顺序生成模式则面向自动语音识别和文本转语音等任务,并允许在不重新初始化模型的情况下切换生成模式。音频堆栈采用低精度量化感知训练,这使得 STOI 和 UTMOS 等指标能够接近全精度基线水平,同时又能部署在计算能力有限的设备上。

要点总结
- LFM2.5 是一个基于 LFM2 设备优化架构的 12 亿规模混合模型系列,包含基础版、指令版、日语版、视觉语言版和音频语言版,全部以 Hugging Face 和 LEAP 的开放权重形式发布。
- LFM2.5 的预训练范围从 10T 扩展到 28T 个标记,而 Instruct 模型增加了监督微调、偏好对齐和大规模多阶段强化学习,这使得指令遵循和工具使用质量超越了其他 10 亿类基线。
- LFM2.5-1.2B-Instruct 在 10 亿级文本基准测试中表现出色,在 GPQA 测试中达到 38.89 分,在 MMLU Pro 测试中达到 44.35 分,并且在 IFEval 和 IFBench 测试中领先于 Llama 3.2 1B Instruct、Gemma 3 1B IT 和 Granite 4.0 1B 等同类模型。
- 该系列包括专门的多模态和区域变体,其中 LFM2.5-1.2B-JP 在其规模下针对日语基准测试取得了最先进的结果,而 LFM2.5-VL-1.6B 和 LFM2.5-Audio-1.5B 则涵盖了边缘代理的视觉语言和本地音频语言工作负载。
参考资料:
- https://www.liquid.ai/blog/introducing-lfm2-5-the-next-generation-of-on-device-ai
- https://huggingface.co/collections/LiquidAI/lfm25
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/64113.html