
本文为上海交通大学与蚂蚁集团的合作工作,主要关注多模态数据的统一高效无损压缩。无损压缩是数据存储与传输的基石,但在多模态协同的大数据时代,现有压缩器要么仅针对单模态设计导致部署冗余,要么依赖重量级大模型导致推理开销巨大,而如何在保持轻量化的同时实现跨模态的统一压缩一直缺乏理想方案。
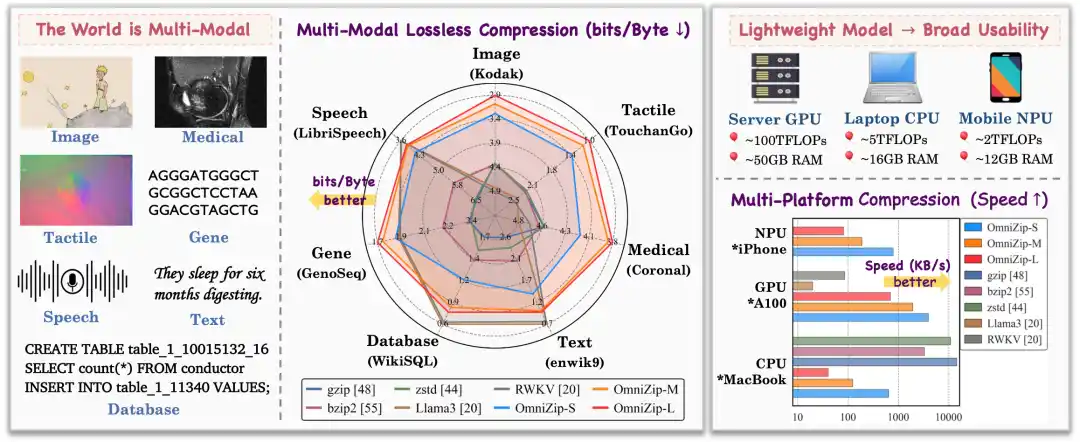
因此,本文提出 “OmniZip”:首个面向端侧部署的多模态通用无损压缩框架,覆盖自然图像、医疗影像、文本、语音、触觉、数据库及基因序列等 7 种异构模态。OmniZip 通过引入统一分词策略、模态路由上下文学习以及结构重参数化技术,在保持极小参数量(4.8M~96M)的同时,在 16 个数据集上明显超越了 gzip、zstd、bzip2 等传统通用压缩工具(码率节省 30%~60%),并在 iPhone NPU、MacBook CPU 等资源受限的移动端设备上实现了近乎实时(~1MB/s)的无损压缩推理。
文章来源:CVPR 2026
论文题目:OmniZip: Learning a Unified and Lightweight Lossless Compressor for Multi-Modal Data
论文作者:Yan Zhao, Zhengxue Cheng, Junxuan Zhang, Dajiang Zhou, Qunshan Gu, Qi Wang, Li Song (SJTU Medialab & Ant Group)
项目链接:https://github.com/adminasmi/OmniZip-CVPR2026
论文链接:https://arxiv.org/pdf/2602.22286
内容整理:赵研
引言

随着AI与物联网的普及,数字生态呈现显著的多模态特征,涵盖图像、文本、语音以及医疗影像、触觉传感、数据库、生物基因等异构数据。在数据库存储、医学影像及模型训练等精度敏感场景中,任何信息损失都可能导致严重后果,因此无损压缩成为保障数据系统效率与可靠性的核心基础设施。
基于深度学习的概率建模技术显著提升了无损压缩率,但其实际应用面临两大瓶颈:
- 计算复杂度过高: 现有高性能模型(如大语言模型)参数量巨大,导致编解码速度极慢,难以在边缘设备或实时系统中部署。
- 模态兼容性不足: 异构数据在结构与统计特性上差异极大,现有方法多针对单一模态设计,缺乏能显式刻画模态差异且保持高效参数共享的统一框架。
因此,本文提出 OmniZip,一种兼顾高性能与工程可部署性的轻量化多模态通用无损压缩方法。其核心技术包括:
- 模态通用分词器: 将多模态信号无损映射至统一离散词元空间,奠定统一表示基础。
- 动态路由建模机制: 在上下文建模与前馈网络中引入自适应路由策略,使模型在共享主干网络的同时,能针对不同模态动态选择最优建模路径。
- 结构重参数化: 利用重参数化训练策略,在不增加推理开销的前提下提升模型表达能力。
在覆盖 7 种模态的 16 个数据集上,OmniZip 的压缩效率较传统工具 gzip 提升了 42%~62%,性能达到或超越了主流单模态专用模型。更重要的是,OmniZip 在 MacBook CPU 和 iPhone NPU 等端侧设备上实现了约 1 MB/s 的近乎实时推理速度,证明了其在实际工程中的应用潜力。
方法
如图 1 所示,本文提出了一种轻量化的多模态无损压缩框架,旨在支持图像、文本和语音三大类核心数据形态,并针对它们在实际应用中的具体分支(如自然图像、医学影像、触觉信号、基因序列、结构化数据库等)进行优化压缩。方法的核心是通过统一框架处理不同模态数据,在保证压缩效率的同时,确保在资源有限的端侧设备(如笔记本CPU、移动端NPU)上也能实现近实时的推理速度。
整体框架

编码过程
如图 2 所示,编码过程首先通过统一的分词器将不同模态的原始信号映射为离散词元序列,确保此过程具有严格的可逆性。得到词元序列后,采用自回归模型进行条件概率建模,估计每个词元在给定前序词元的条件下的概率。接着,使用算术编码将条件概率分布转化为比特流,从而实现压缩。
解码过程
解码过程与编码过程保持完全对称,采用相同的自回归模型进行逐步解码。首先,解码器从编码阶段生成的比特流中恢复出原始词元序列。通过与编码过程相同的条件概率模型,逐步恢复每个词元,直到完整重建输入数据。由于算术编码是可逆的,解码过程能够保证无损重建。
轻量化骨干网络
为构建兼具高性能建模与高效部署能力的压缩框架,本文首先对三种典型自回归架构:Transformer(基于自注意力)、Mamba(基于状态空间模型)及 RWKV(基于线性注意力)进行了系统性评估。对比维度涵盖了压缩效率(bits/Byte)、理论计算复杂度(MACs)以及基于移动端芯片(Apple M4)的实测推理吞吐量(KB/s)。
在实验配置方面,为排除多模态表征机制的干扰,评估统一在文本数据集 enwik8/9 上开展。模型采用 16K 词表的 SentencePiece BPE 分词,并维持 1024 的上下文窗口。为模拟真实部署环境,所有候选模型均通过 CoreML 框架转换为统一格式,并在 MacBook Pro 的 CPU 上测试其真实推理效能。

实验结果如表 1 所示,在同等参数量级下,RWKV 在压缩性能与运算效率之间取得了最佳平衡:其压缩率优于或等同于 Transformer,且端侧推理速度表现出显著的硬件亲和性,吞吐量大幅领先。相比之下,Mamba 在 CPU 端的部署效率较低,未能体现出性能优势。因此,综合权衡建模精度、计算开销与部署可行性,本文最终选定 RWKV 作为 OmniZip 的核心骨干网络。
通用分词器构建
实现多模态通用无损压缩的首要挑战在于,如何在确保严格可逆性的前提下,消除异构数据在空间维度、统计特性及语义表达上的显著差异。为此,本文设计了一套统一分词方案,将各类信号映射至共享的离散词元空间。
- 文本与结构化数据
针对自然语言、生物序列及数据库记录,本文采用 SentencePiece BPE 算法构建 16K 规模的基础词表。为增强领域自适应性,我们在词表中显式注入了特定模态的原子符号:例如基因序列的碱基符号(A, T, G, C)以及 SQL 结构化查询的关键字(SELECT, FROM 等),以提升对稀疏语义组合的建模效率。
- 图像与触觉张量数据
针对具备二维空间相关性的图像类数据,本文采用分块光栅扫描策略。彩色图像被划分为 的局部切片,并按子像素顺序展开为序列。每个 8-bit 子像素对应单一词元。医疗影像直接进行灰度像素映射;触觉信号则根据其传感器特性,分别转化为 RGB 图像序列或伪 RGB 三元组,实现表示层面的模态对齐。
- 语音波形数据
为规避传统音频量化编码带来的不可逆精度损失,本文对语音信号采取逐字节建模策略。通过直接读取原始比特流并将每个字节映射为独立词元(词表大小 256),该方案在不损失任何频谱细节的前提下,将连续波形无缝纳入自回归概率建模框架。
- 共享词元空间与模态掩码
我们将上述模态特定的子词表合并为统一空间,为使模型感知模态间的条件先验,我们在序列头部添加了模态标识前缀(如 <gene>、<tactile> 等)。此外,为优化预测精度并消除跨模态分布干扰,本文引入了模态掩码机制。在输出概率分布计算阶段,通过二值掩码 Mm 强制约束 Softmax 的预测范围:

该机制确保了算术编码过程仅在当前模态的有效值域内进行搜索,显著提升了编码效率与分布拟合的准确性。
自适应模态路由
OmniZip 的核心骨干基于 RWKV 架构,其利用线性递归机制维护隐藏状态,在保持长序列建模能力的同时实现了推理复杂度的线性化。然而,多模态数据(一维文本、二维图像张量、连续语音波形)在时空关联结构与统计分布上存在本质异质性,单一静态的上下文建模路径难以兼顾各模态的最优拟合。因此本文设计了自适应模态路由机制,如图 3 所示。

- 上下文建模中的模态路由
为在统一框架下实现模态自适应,本文在 RWKV 的时间混合模块(Time-mixing)中引入了混合专家机制(MoE)。通过对不同子结构的消融分析,本文发现将 MoE 应用于 V(Value)投影层 能产生最显著的性能收益。这表明 K(Key)与 R(Receptance)层更倾向于提取通用的语义索引与时序门控特征,而 V 层则承载了具有显著模态差异的内容表示。本文采用 Top-2 稀疏路由策略,在不显著增加计算负担的前提下,为不同模态提供定制化的特征映射路径。
- 模态自适应前馈网络
在非线性表征层面,本文同样将标准前馈网络(MLP)重构为路由前馈模块。不同模态在特征变换需求上各异(如文本侧重语义组合,图像侧重纹理映射),共享参数会限制模型的表达上限。在 OmniZip 的 MoE-MLP 设计中,每个专家子网络的维度被精简为原始 MLP 的 50%,配合 Top-2 激活机制,使得单个词元触发的活跃参数量与标准架构持平。
模型优化策略
- 重参数化训练策略
为了提升模型的压缩能力并保持推理复杂度的低要求,本文重参数化训练策略,在训练阶段扩展模型容量,并通过结构重参数化保持推理阶段的效率。在 RWKV 主干网络中,我们为每个时间混合模块的 R、K、V 投影层引入辅助分支,采用矩阵分解形式来增强表达能力。训练阶段,输出由主干和旁路共同计算,推理阶段则通过重参数化合并旁路,恢复为单一路径结构,这样避免了增加计算开销。
- 损失函数
本文的训练目标函数包括两部分:主要的交叉熵损失用于概率建模,辅以 Z-loss 和负载均衡损失以稳定混合专家训练过程。交叉熵损失优化压缩码长,而 Z-loss 约束路由网络中的 logit 数值,避免过大数值导致的梯度不稳定。负载均衡损失则通过限制专家之间的分布不均衡,提升专家的利用效率,从而增强模型的泛化能力。损失函数中的权重系数设置为 λ = 0.001 和 μ = 0.01 ,确保主任务优化的同时提升 MoE 训练的稳定性。

实验
数据集
本文实验覆盖七类典型模态:自然图像、医疗图像、触觉信号、自然语言文本、基因序列、结构化数据库与语音。整体选取 16 个公开数据集进行训练与评估,数据集概览见表 2。
为保证多模态训练的稳定性与可比性,我们对各模态训练数据量进行统一约束:每个模态固定使用 1GB 数据。对于规模较大的数据集,随机采样得到 1GB 子集;对于规模较小的数据集,则结合模态特点做轻量增强以补足规模差异。训练时进一步采用均衡批次采样:数据加载器以轮询方式在不同模态间循环取样,并在各模态内部对打乱后的索引等比例抽取,从而保证每个 batch 中不同模态样本数量一致,避免模型偏向数据量更大的模态。

实现细节
为评估模型规模对压缩效率与计算开销的影响,我们通过调节嵌入维度与网络块数构建了三种规模的模型变体:OmniZip-S、OmniZip-M 与 OmniZip-L,其结构配置与复杂度统计见表 3。

本文采用三阶段分步训练以提升训练稳定性:阶段一冻结前馈路由模块,仅训练其余参数 2 个批次(学习率 1 x 10-4);阶段二冻结上下文路由模块,再训练 2 个批次(学习率保持 1 x 10-4);阶段三解冻全部参数进行 20 个批次端到端训练,并使用余弦退火将学习率从 1 x 10-4 平滑衰减至 1 x 10-5。优化器采用 FusedAdam 以提升训练效率与数值稳定性,所有模型均在 NVIDIA A100 GPU 上完成训练。
在评估与部署阶段,我们在三类平台上测试性能:NVIDIA A100 GPU(高吞吐)、MacBook Pro 2024(Apple M4 CPU,桌面端推理)与 iPhone 17 Pro(A19 NPU,移动端推理)。CPU/NPU 侧将 PyTorch 模型转换为 CoreML 并通过 Xcode 测量延迟;GPU 侧切换至性能模式并确保无额外进程干扰,连续执行 1000 次前向推理,以平均时延作为报告结果。
无损压缩性能

- 图像类数据
如表 4 所示,通用压缩器在图像类数据上的表现整体受限:以若干自然图像、触觉与医学图像数据集为例,gzip、bzip2、zstd 往往仍处在较高码率区间(约 2.3–4.6 bits/Byte)。传统图像专用无损压缩(如 FLIF、JPEG-XL)压缩率明显更好,体现了结构化建模对图像统计特性的适配优势。学习型图像压缩方法则呈现一定领域依赖:在自然图像上训练的模型迁移到触觉或医学图像时性能往往下降,说明单模态训练在跨分布场景下泛化有限;而将图像简单转为 ASCII 再用语言模型建模的多模态方法 LMIC,也因为忽略图像模态的专有结构而存在性能差距。
相比之下,OmniZip 在三类图像模态上均保持稳定且有竞争力的表现:即使最小的 OmniZip-S 也能在多类图像数据上达到与专用学习型方法相近的水平,并相对 gzip 提升约 30%;随着模型增大,性能进一步提升,例如在若干代表数据集上 OmniZip-L 可达到 2.925/0.987/3.937 bits/Byte,相对 gzip 的码率降低约 33%/57%/16%。

- 文本类数据
如表 5 所示,传统通用压缩器在文本类数据上通常能取得较稳定但有限的压缩率(如约 2.3 bits/Byte)。近年来的学习型文本压缩在自然语言上显著更强,例如 NNCP、CMIX 在 enwik9 上可达到约 0.85–0.88 bits/Byte;基于大语言模型的方案还能进一步提高概率估计精度,但通常伴随较高推理复杂度,且在基因序列、数据库等非自然语言文本上收益相对有限,反映出子模态间统计差异仍然明显。
OmniZip 在更小的模型规模下,在多种文本类数据上依然取得竞争力结果:OmniZip-S 相对 gzip 提升约 24%–47%,OmniZip-M/L 进一步带来约 10%–20% 的增益;在数据库与基因数据上提升更明显,部分数据集上 OmniZip-L 可达到约 1.740 与 1.782 bits/Byte,接近当前最优水平。

- 语音类数据
如表 5 所示,语音具有连续时间与频谱相关性,统计特性与图像/文本差异明显。通用压缩器在语音数据上通常码率较高(约 5.6–6.5 bits/Byte),专用无损音频算法(如 FLAC)更优(例如约 4.96 bits/Byte),体现了面向音频预测残差建模的优势。多模态学习型方法在语音上显示出一定潜力(例如可到约 3.6 bits/Byte),但常伴随较大的模型与推理开销。OmniZip 在性能与效率之间取得更好的折中:在 LibriSpeech 上相对 gzip 提升约 36%–42%,相对 FLAC 提升约 15%–23%,同时速度明显快于其他学习型方案。
复杂度与吞吐
如图 5 所示,我们在不同硬件与 batch size 下评估推理速度。吞吐随 batch size 增大而提升,并在约 512 左右趋于饱和,主要得益于 RWKV 的线性复杂度与路由的稀疏激活,使得高并发下接近线性加速。在 A100 上三种规模均可达到 MB/s 量级,其中 OmniZip-S 峰值约 4 MB/s,较 OmniZip-L 高约 8 倍;在 MacBook CPU 与 iPhone NPU 上,OmniZip-S 仍可维持约 1 MB/s 的近实时速度,OmniZip-M/L 也能达到百 KB/s 量级(约 200 KB/s 与 100 KB/s)。从 batch=1 增至 512,各平台吞吐普遍提升 10–20 倍,表明具有良好的并行扩展性与端侧部署可行性。

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。