
在生成式 AI 媒体领域,行业正从纯粹的概率像素合成转向能够进行结构推理的模型。Luma Labs 近日发布了Uni-1,这是一款基础图像模型,旨在解决标准扩散流程中固有的“意图鸿沟”。Uni-1 通过在生成之前加入推理阶段,将工作流程从“提示工程”转变为“指令执行”。

架构:仅解码器自回归Transformer
虽然像稳定扩散模型或Flux这样的流行模型依赖于去噪扩散概率模型(DDPM),但Uni-1采用的是一种仅包含解码器的自回归Transformer架构。这种转变在技术上意义重大,因为它使模型能够将文本和图像视为交错的标记序列。
在这种架构中,图像被量化为离散的视觉标记。模型预测序列中的下一个标记,无论该标记是单词还是视觉元素。这形成了一个反馈回路,模型可以通过预测逻辑空间布局来推断文本指令,然后再生成最终的高分辨率细节。
主要技术属性:
- 统一智能:该模型在同一次前向传递中同时执行理解和生成操作。
- 交错标记:通过在单个流中处理文本和视觉数据,该模型能够保持对空间关系的更高上下文感知能力。
- 空间逻辑:与扩散模型可能由于潜在空间限制而难以处理“左/右”或“后/下”不同,Uni-1 将构图的几何形状作为其序列预测的一部分进行规划。
基准测试推理:RISEBench 和 ODinW-13
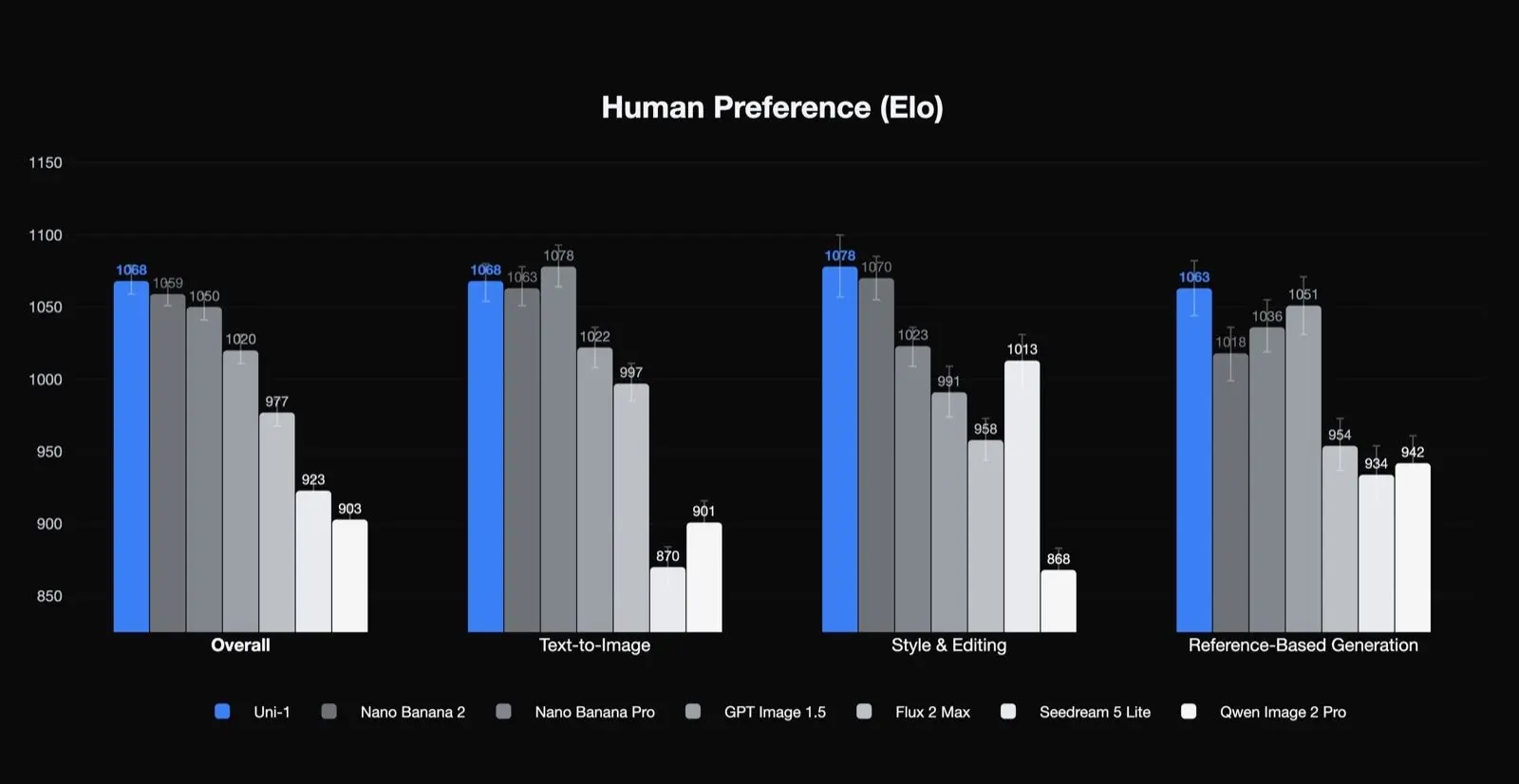
为了验证“先推理后生成”的方法,Luma Labs 将 Uni-1 与行业基准进行了对比评估,这些基准更注重逻辑而非单纯的美观。结果表明,Uni-1 目前在用户偏好排名中领先于Flux Max和Gemini。
数据科学家应注意 Uni-1 在两个特定基准测试中的表现:
| 基准 | 重点领域 | Uni-1 性能 |
| RISEBench | 基于推理的视觉编辑 | 空间推理和逻辑约束处理精度高。 |
| ODinW-13 | 开放式探测 | 优于仅理解变体,表明生成可以提高视觉认知能力。 |
该模型在ODinW-13 数据集上的表现尤其值得人工智能研究人员关注。它表明,通过自回归训练生成像素的模型,比仅针对计算机视觉任务训练的模型,能够构建更稳健的目标检测和分类内部表征。
Uni-1 的运行:简明英语和 API 访问
Uni-1 的用户体验 (UX) 设计旨在最大程度地减少对即时工程的需求。由于该模型能够通过意图进行推理,因此它可以接受简单的英语指令。
- 当前可用性:可通过lumalabs.ai/uni-1访问。
- 成本基础:每张图像约0.10 美元。这反映了与轻量级扩散模型相比,推理优先的自回归模型需要更高的计算开销。
- API路线图: Luma已确认即将推出API接口。这将使开发者能够将Uni-1的空间推理功能集成到自动化创作流程中,例如动态UI生成或游戏资源开发。
要点总结
- 架构转变: Uni-1 摒弃了传统的扩散管道,转而采用仅解码器的自回归转换器,将文本和像素视为单一的交错标记序列,从而统一理解和生成。
- 推理优先综合:该模型在渲染之前执行结构化的内部推理和空间逻辑,使其能够根据简单的英语指令执行复杂的布局,而无需预先进行工程设计。
- SOTA 基准测试:它在人类偏好排名中领先于 Flux Max 等竞争对手,并在RISEBench(基于推理的视觉编辑)和ODinW-13(野外开放检测)上设定了新的性能标准。
- 生产一致性:该模型专为高保真专业工作流程而设计,在保持角色表身份完整性方面表现出色,能够将粗略的草图转化为结构精确的精美艺术作品。
- 开发者访问权限: Uni-1目前面向网络用户开放,并将于即将推出 API,其定价约为每张图像 0.10 美元,定位为高精度创意应用的高级引擎。
参考资料:https://lumalabs.ai/uni-1
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/65636.html