
谷歌已通过 Google AI Studio 中的 Gemini Live API 向开发者发布了 Gemini 3.1 Flash Live 预览版。该模型旨在实现低延迟、更自然、更可靠的实时语音交互,是谷歌迄今为止“质量最高的音频和语音模型”。通过原生处理多模态数据流,该版本为构建语音优先型智能体提供了技术基础,突破了传统基于回合制语言学习模型 (LLM) 架构的延迟限制。

“等待时间堆栈”时代结束了吗?
以往语音AI实现的核心问题在于“等待时间堆栈”:语音活动检测(VAD)会等待静音,然后进行转录(STT),接着生成(LLM),最后合成(TTS)。等到AI开口说话时,人早已继续进行下一步了。
Gemini 3.1 Flash Live 通过原生音频处理简化了这一流程。该模型并非简单地“读取”文本,而是直接处理声音细微差别。根据谷歌的内部指标,该模型在识别音调和语速方面比之前的 2.5 Flash Native Audio 显著提升。
更令人印象深刻的是它在“嘈杂”的真实环境中的表现。在包含交通噪音或背景嘈杂声的测试中,3.1 Flash Live 模型以前所未有的准确度从环境噪音中识别出相关的语音。对于那些需要在实际应用场景而非安静的录音棚中运行的移动助手或客服代理的开发者来说,这无疑是一项至关重要的优势。
多模态实时 API
对于 AI 开发者而言,真正的转变发生在多模态实时API中。这是一个有状态的双向流式接口,它使用WebSocket(WSS)来维护客户端和模型之间的持久连接。
与一次只能处理一个请求的标准 RESTful API 不同,Live API 允许连续的数据流传输。以下是数据管道的技术细节:
- 音频输入:该模型需要16kHz 、小端序的原始16 位 PCM 音频。
- 音频输出:它返回原始 PCM 音频数据,有效地绕过了单独的文本转语音步骤的延迟。
- 视觉上下文:您可以以大约每秒 1 帧 (FPS)的速度将视频帧作为单独的JPEG 或 PNG图像进行流式传输。
- 协议:现在单个服务器事件可以同时打包多个内容部分,例如音频片段及其对应的文本转录。这大大简化了客户端同步。
该模型还支持插话功能,允许用户在 AI 说话过程中打断它。由于连接是双向的,API 可以立即停止音频生成缓冲区并处理新传入的音频,从而模拟人类对话的节奏。
智能体推理基准测试
谷歌的 AI 研究团队不仅追求速度,更致力于提升实用性。此次发布的版本重点展示了该模型在ComplexFuncBench Audio测试中的表现。该基准测试旨在评估 AI 仅基于音频输入,在各种约束条件下执行多步骤函数调用的能力。

Gemini 3.1 Flash Live 在这项基准测试中取得了惊人的90.8% 的成绩。对于开发者而言,这意味着语音代理现在无需文本中介先进行思考,即可处理复杂的逻辑推理。例如,根据价格阈值查找特定发票并通过电子邮件发送。
| 基准 | 分数 | 重点领域 |
| ComplexFuncBench 音频 | 90.8% | 从音频输入调用多步骤函数。 |
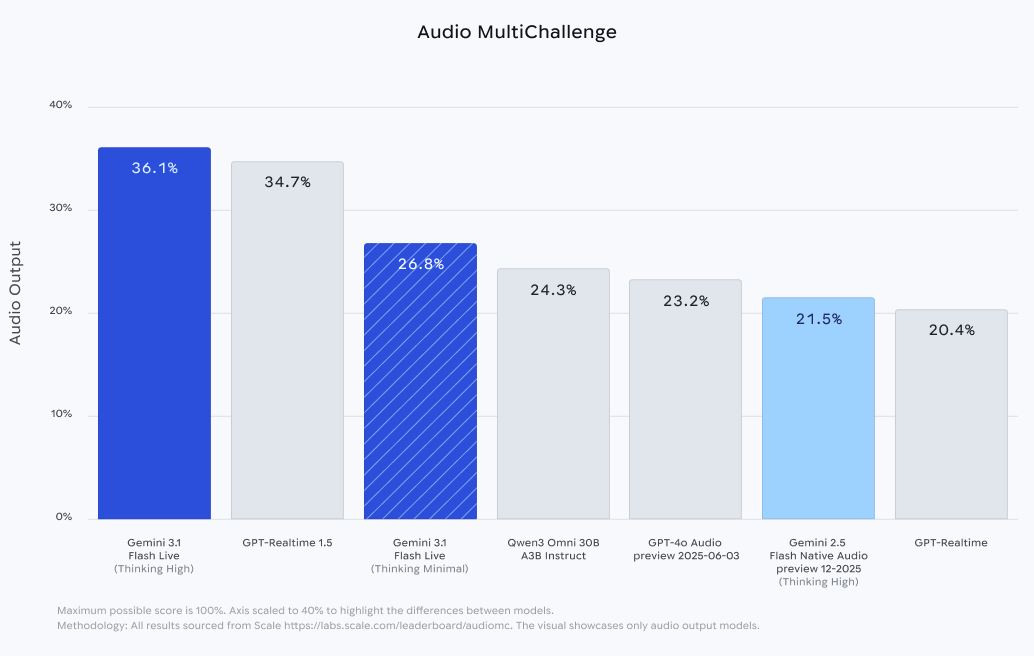
| 音频多挑战 | 36.1% | 在嘈杂/断断续续的言语中(边思考边听)听懂指令。 |
| 上下文窗口 | 128k | 可用于会话内存和工具定义的令牌总数。 |
该模型在音频多任务挑战赛(启用思考功能后得分 36.1%)上的表现进一步证明了其强大的适应能力。这项基准测试旨在检验人工智能在应对真实世界人类语音中常见的干扰、卡顿和背景噪音时,能否保持专注并遵循复杂的指令。

开发者控制项:thinkingLevel
对于 AI 开发者而言,一项突出的功能是能够调整模型的推理深度。通过 thinkingLevel 参数,开发者可以在“最低”、“低”、“中”和“高”之间进行选择。
- 最低:这是实时会话的默认设置,优先确保尽可能低的首次令牌生成时间(TTFT)。
- 高:虽然会增加延迟,但能让模型在响应前进行更深入的“思考”步骤,这对通过实时视频进行的复杂问题解决或调试任务至关重要。
弥合知识鸿沟:Gemini Skills
随着 AI API 的快速演进,在开发者的编码工具中保持文档的及时更新已成为一项挑战。为解决这一问题,谷歌的 AI 团队维护着 google-gemini/gemini-skills 代码库。这是一个由“技能”(即经过精心整理的上下文和文档)组成的库,可将其注入 AI 编码助手的提示词中,从而提升其性能。
该仓库包含一个名为 gemini-live-api-dev 的特定技能,专注于 WebSocket 会话的细节以及音频/视频二进制大对象(blob)的处理。更广泛的 Gemini Skills 仓库报告显示,添加相关技能后,使用 Gemini 3 Flash 时的代码生成准确率提升至 87%,使用 Gemini 3 Pro 时则提升至 96%。通过使用这些技能,开发者可以确保其编码助手采用 Live API 的最新最佳实践。
要点总结
- 原生多模态架构:它将传统的“转录-推理-合成”堆栈简化为一个原生音频到音频的处理过程,显著降低了延迟,并实现了更自然的音调和节奏识别。
- 有状态双向流:该模型使用 WebSocket (WSS) 进行全双工通信,允许“强插”(用户中断)和同时传输音频、视频帧和转录文本。
- 高精度智能推理:它针对直接从语音触发外部工具进行了优化,在 ComplexFuncBench Audio 的多步骤函数调用测试中取得了 90.8% 的分数。
- 可调的“思考”控制
thinkingLevel:开发者可以使用新的参数(范围从最小到高)在 128k 个标记的上下文窗口中平衡对话速度和推理深度。 - 预览状态和限制:目前该模型处于开发者预览阶段,需要 16 位 PCM 音频(16kHz 输入/24kHz 输出),目前仅支持同步函数调用和特定内容部分捆绑。
参考资料:
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-live/
https://github.com/google-gemini/gemini-skills/blob/main/skills/gemini-live-api-dev/SKILL.md
https://ai.google.dev/gemini-api/docs/live-api/get-started-sdk
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/65747.html