
今天,字节跳动 Seed 正式推出原生全双工语音大模型 Seeduplex。相比于上一代半双工豆包端到端语音模型,Seeduplex 基于“边听边说”的全新框架设计,交互体验的自然感、顺畅度大幅提升。
如果说端到端架构通过统一“听”“说”模块,让 AI 拥有了自然表达的潜能,那么全双工(Full-Duplex)技术则通过实现“听”“说”同步,进一步释放了这种潜能。它赋予模型更自然的对话节奏和更出色的抗干扰能力——不再是简单的一问一答,而是能在噪声与无关人声的干扰下精准响应,做到快慢有度、收放自如。
具体来说,通过模型架构创新与训练优化,并攻克高并发下的卡顿与稳定性等工程挑战,Seeduplex 实现了业界领先的全双工语音实时交互效果,其在保持模型智能上限与超低时延的同时,重点实现了以下两项突破:
- 精准抗干扰:模型具备持续的“倾听”能力,从而能更好地理解用户所处的声学环境,准确忽略背景噪音和无关对话。在复杂场景下,相比半双工模型,其误回复率和误打断率减少了一半。
- 动态判停:模型能联合语音和语义特征,综合判断用户意图,可实现更自然的对话节奏控制。面对用户的思考犹豫,模型能耐心倾听;在用户说完后,又能快速响应。相比半双工模型,其抢话比例相对下降了 40%。
目前,Seeduplex 已在豆包 App 全量上线,这意味着全双工技术正式走出实验室,在业界率先实现了规模化落地,可为上亿用户提供连续高质量的实时语音交互体验。多维度评测显示,Seeduplex 在对话的流畅度和节奏感上,均显著优于传统的半双工方案及行业主流 App 的语音通话功能;在判停表现上,模型相比半双工方案提升了 8%,展现出更接近自然对话的分寸感。
项目主页:
https://seed.bytedance.com/seeduplex
体验入口:
请将豆包 App 更新至最新版本,在对话框内选择“打电话”,进入语音通话界面体验即可。
语音交互体验全面升级,对话节奏更精准、更自然
人与人的对话,本身就是一种边听边说的“全双工”交流,过程中充满了停顿、思考、犹豫,以及背景噪音的干扰与声音重叠。一个期望实现自然交互的语音对话系统,必须具备处理这种高自由度、非结构化音频流的能力——既要在喧嚣中“听得清”,又要懂得在你整理思绪时“耐心等”。
过去,传统半双工系统往往依赖级联的模块化设计:利用独立 VAD(语音活动检测)进行机械切音,或通过传统算法进行前端降噪。由于判定依据仅限于单一的声学特征或局部的文本语义特征,系统在复杂环境中极易“被带跑偏”,或在用户停顿时触发“抢话”。
而 Seeduplex 基于自研大语言模型(LLM)底座,创新打造实时语音全双工交互框架,并引入大规模语音数据进行预训练,具备了原生的语音语义联合建模能力。它能全局理解音频中的语音语义信息,动态决策对话节奏,相比传统系统在抗干扰和对话节奏控制表现上实现跃升。
1. 精准抗干扰:喧嚣中强大的“声学专注力”
复杂的声学环境一直是语音交互的挑战。背景噪音、人声干扰常会“污染”用户的语音输入,导致系统响应迟钝、播报中断甚至误触发。过去,用户常需提高音量或寻找安静角落,才能完成一次稳妥的交互。Seeduplex 模型能持续接收并理解用户侧音频,感知用户所在的全局声学环境,从而精准判断哪些是真正和模型交互的声音,哪些是干扰声。抗干扰力的提升,使得 Seeduplex 的误回复率与误打断率大幅下降。
2. 动态判停:快慢有时,收放自如
真正的自然交互,核心在于准确判断用户何时在思考、何时已说完。Seeduplex 通过深度融合语音与语义理解,在对话节奏把控上具有更强的灵活性。
全双工语音技术实现
从演示到规模化落地
全双工能力的实现,对模型架构、算法实现和工程链路都提出了更高要求。Seeduplex 采用了原生端到端的建模方式,系统具备流式感知能力,能够对输入的音频信号进行特征提取,并由底座模型进行实时处理。
在交互逻辑上,模型通过对声学特征与对话上下文的综合建模,自主判断当前时刻的状态,决定是开始回复、继续聆听还是响应用户打断。
为支撑模型在豆包 App 上全面上线,团队在模型框架设计、算法优化、工程性能与稳定性方面进行了大量优化:
- 模型框架设计:构建更贴合语音实时对话原生特性的模型架构,使模型能够直接从数据中学习语音与语义的一体化表达和节奏控制,显著提升交互自然度。
- 算法与训练:依托海量语音数据进行大规模预训练,并通过多能力、多任务的后训练体系,实现对话智能、超低延迟、对话节奏控制、强抗干扰能力与指向性理解等多维能力的协同优化,使模型具有稳定、高效、自然的交互表现。
- 推理性能:通过投机采样、量化等方式极致优化性能,实现成本和延迟的平衡。
- 服务稳定性:重点解决了收音、播报卡顿等问题,确保模型可在大流量环境下连续稳定运行。
最终,Seeduplex 突破了数据构建、超低时延与模型效果协同优化等核心技术瓶颈。大规模 A/B 实验数据证明了全双工交互模式的价值,相比此前上线豆包的半双工模型,Seeduplex 在用户的通话时长、留存等核心指标上均实现正向提升,整体通话满意度绝对值提升了 8.34%,用户反馈中“抢话”、“响应慢”、“误打断”等问题的提及比例明显下降。
Seeduplex 评测结果,多维度较半双工模型显著提升
我们对 Seeduplex 进行了一系列主客观评测,结果显示,Seeduplex 在打断与判停表现上均显著优于半双工模型,并在多项关键指标上处于行业领先水平。
相比豆包 App 之前使用的半双工对话框架,Seeduplex 的整体交互体验进一步提升,其判停 MOS 分提高了 8%,对话流畅度 MOS 分提升了 12%。
具体来说,Seeduplex 将判停延迟降低约 250ms 的同时,复杂场景下的 AI 抢话比例相对减少 40%;针对用户的打断需求,在响应准确率更高的前提下,Seeduplex 将打断响应的延迟进一步缩短了约 300ms;在复杂声学干扰场景下,Seeduplex 将误回复率和误打断率降低了一半。
另外,通过与原半双工模型以及行业主流 App 语音通话功能的横向对比,Seeduplex 在判停、打断响应任务上展现出明显优势,并显著提升了评测用户对整体交互节奏是否合理的对话流畅度评价。
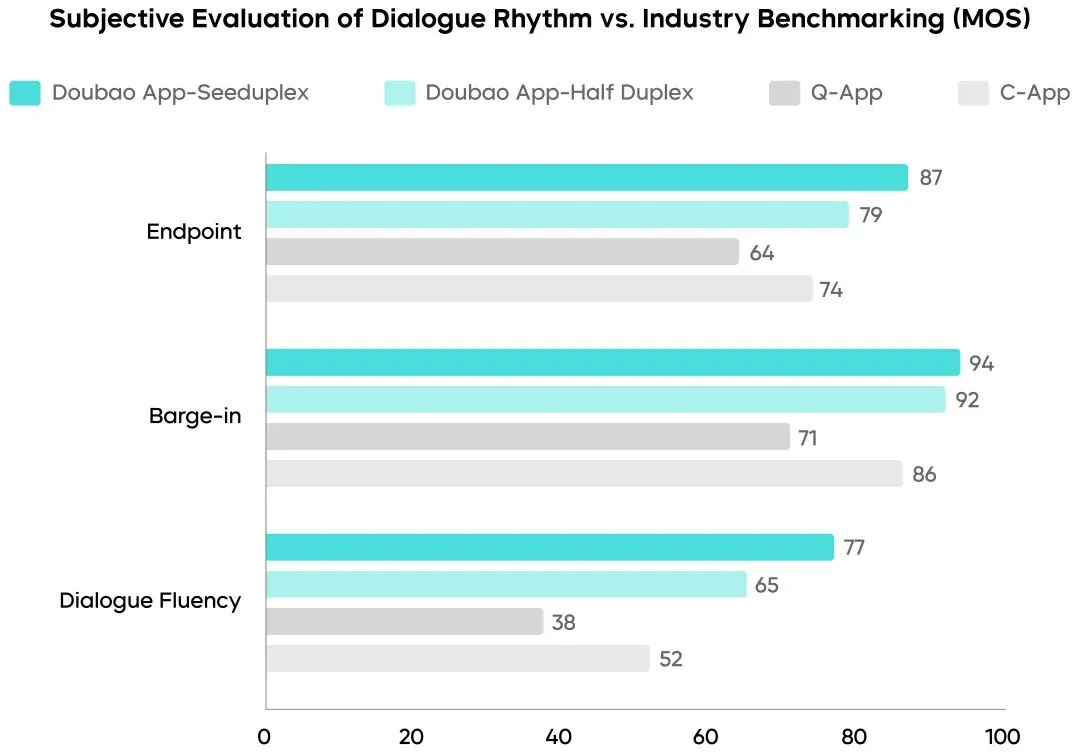

通过组织真人对话测试,初步摸底了目前人机对话相对真实人人对话(普通人群)的水位。结果显示,以“人人对话”为基准,Seeduplex 在判停表现上相比半双工方案显著提升了 8%。而在响应打断的表现上,真实人人对话有时在响应上相对滞后,Seeduplex 则表现更稳定,略好于人人对话的平均水平。但在整体对话流畅度上,Seeduplex 和真实人人对话仍有不小差距,有待进一步提升。
总结与展望
Seeduplex 的上线,是语音交互从“回合制”向“实时自然交互”演进的关键一步。其原生全双工框架不仅提升了模型的抗干扰能力与节奏控制力,更重要的是,也为模型实现感知、思考与执行的全方位融合提供支撑。
未来,Seed 将在以下几个方面继续突破:
- 继续提升模型的音频理解能力,深度优化在多人对话、智能硬件等复杂交互场景中的表现。
- 通过数据 Scaling 和算法优化,持续提升模型的对话节奏多样性和控制能力。
- 在“边听边说”的基础上,引入模型主动能力,如在倾听的过程中附和用户、结合声学环境和对话语境主动交互。
- 实现更深度的多模态融合,在现有语音、文本模态的基础上引入视觉模态,实现“边听、边看、边说”的多维协同。
- 实现感知、思考、输出一体化,进一步探索“边听边想”、“边听边搜”等方案,让模型具备更深度的思考和执行能力,继续提升语音交互的流畅度。
以全双工为起点,Seed 期望未来 AI 能不断进化,在感知、交互与行动的闭环中,真正实现听、看、想、说、做的协同。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。