
微软发布了 VibeVoice-ASR,它是 VibeVoice 系列开源前沿语音 AI 模型的一部分。VibeVoice-ASR 被描述为一个统一的语音转文本模型,可以一次性处理长达 60 分钟的音频,并输出结构化的转录文本,其中包含“谁”、“何时”和“什么”等信息,同时支持自定义热词。
VibeVoice 位于一个统一的代码库中,该代码库以 MIT 许可证托管了文本转语音 (TTS)、实时 TTS 和自动语音识别 (ASR) 模型。VibeVoice 使用以 7.5 Hz 频率运行的连续语音分词器,以及一个基于下一标记的扩散框架。在该框架中,大语言模型 (LLM) 对文本和对话进行推理,扩散头则生成声学细节。该框架的文档主要针对 TTS 功能,但它定义了 VibeVoice-ASR 所处的整体设计环境。
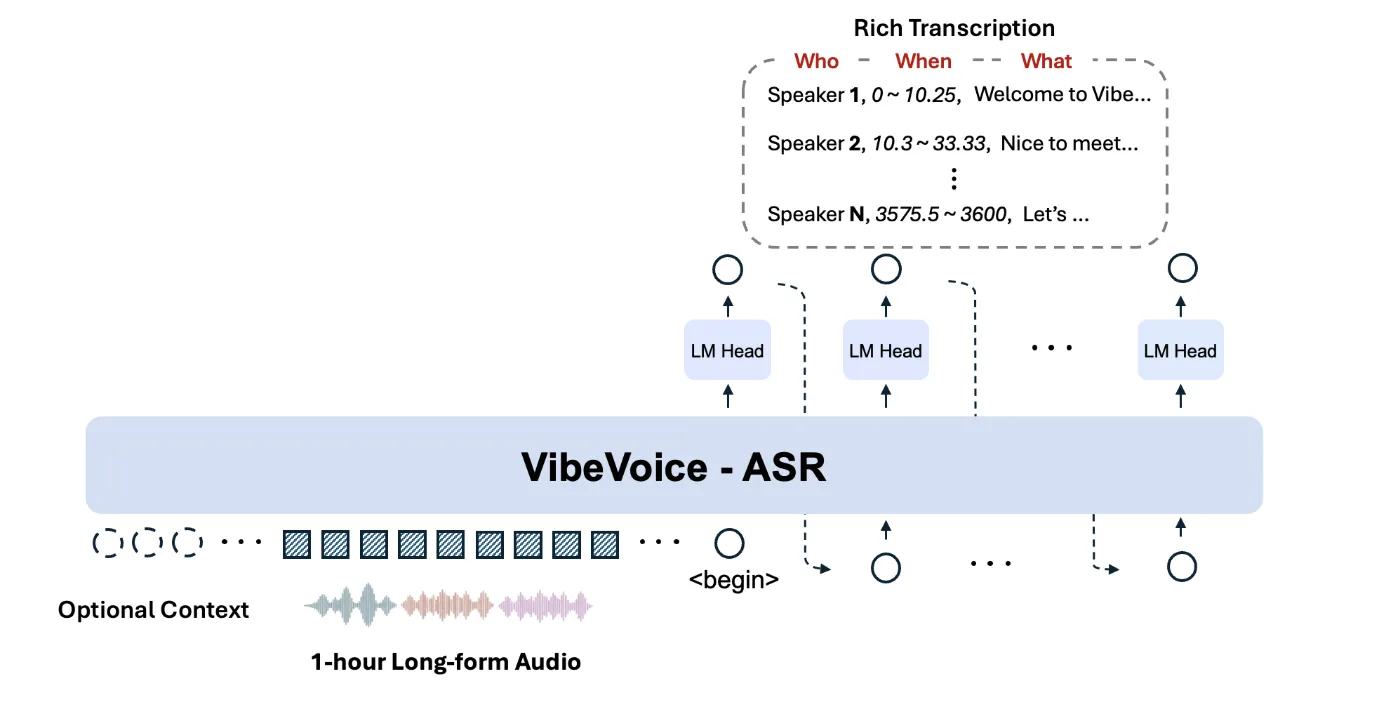

具有单一全局上下文的长格式自动语音识别
与传统的自动语音识别 (ASR) 系统不同,后者通常先将音频分割成短片段,然后再分别进行人声分割和对齐,而 VibeVoice-ASR 则设计为可在 64K 标记长度预算内接收长达 60 分钟的连续音频输入。该模型保留了整个会话的全局表示。这意味着该模型可以在整个一小时内保持说话人身份和主题上下文,而无需每隔几秒就重置一次。
60分钟单次处理
第一个关键特性是,许多传统的自动语音识别(ASR)系统会将长音频分割成短片段进行处理,这可能会导致整体上下文丢失。而VibeVoice-ASR则采用64K标记窗口处理长达60分钟的连续音频,从而在整个录音过程中保持说话人追踪和语义上下文的一致性。
这对于会议记录、讲座录音和长时间客服电话等任务至关重要。只需对整个序列进行一次处理,即可简化流程。无需实现自定义逻辑来合并部分假设或修复音频片段边界处的说话人标签。
自定义关键词以提高域名准确性
自定义热词是第二个关键功能。用户可以提供热词,例如产品名称、组织名称、技术术语或背景信息。模型会使用这些热词来指导识别过程。
这样一来,无需重新训练模型,即可针对特定领域的词元,调整解码方向,使其更倾向于正确的拼写和发音。例如,开发人员可以在推理时传递内部项目名称或客户特定术语。当需要在多个产品中部署相同的基础模型时,如果这些产品具有相似的声学条件但词汇表差异很大,则此功能非常有用。
微软还提供了一个finetuning-asr 目录,其中包含基于 LoRa 的 VibeVoice-ASR 微调脚本。热词和 LoRa 微调相结合,既能实现轻量级自适应,又能实现更深层次的领域专业化。
丰富的转录、分句化和时间安排
第三项功能是包含“谁”、“何时”和“什么”信息的富文本转录。该模型联合执行自动语音识别 (ASR)、人声分割和时间戳功能,并返回结构化的输出,指示谁在何时说了什么。
下面列出了三个评估指标,分别为 DER、cpWER 和 tcpWER。

- DER 是说话人分割错误率,它衡量模型将语音片段分配给正确说话人的准确度。
- cpWER 和 tcpWER 是在对话环境下计算的词错误率指标
这些图表总结了该模型在多说话人长篇数据上的表现,这是该 ASR 系统的主要目标设置。
这种结构化的输出格式非常适合下游处理,例如针对特定说话人的摘要、行动项提取或分析仪表板。由于片段、说话人和时间戳都来自同一个模型,下游代码可以将转录文本视为时间对齐的事件日志。
要点总结
- VibeVoice-ASR 是一个统一的语音转文本模型,可以在 64K 标记上下文中一次性处理 60 分钟的长音频。
- 该模型同时执行自动语音识别、语音分割和时间戳功能,因此可以在单个推理步骤中输出结构化的转录文本,其中编码了谁、何时和什么。
- 自定义热词允许用户注入特定领域的术语,例如产品名称或技术术语,以提高识别准确率,而无需重新训练模型。
- 使用 DER、cpWER 和 tcpWER 进行评估侧重于多说话人对话场景,这使得该模型与会议、讲座和长时间通话相一致。
- VibeVoice-ASR 在 VibeVoice 开源堆栈中以 MIT 许可证发布,并附带官方权重、微调脚本和用于实验的在线 Playground。
参考资料:
https://huggingface.co/microsoft/VibeVoice-ASR
https://github.com/microsoft/VibeVoice?tab=readme-ov-file
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/64476.html