
语音技术仍然面临数据分布问题。自动语音识别 (ASR) 和文本转语音 (TTS) 系统在高资源语言方面取得了快速发展,但许多非洲语言在开放语料库中的代表性仍然不足。谷歌及其合作者组成的研究团队推出了WAXAL,这是一个涵盖 24 种非洲语言的开放多语言语音数据集,其 ASR 组件由转录的自然语音构建而成,TTS 组件则由录音棚级别的单人录音构建而成。
WAXAL 被构建为两个独立的资源,因为 ASR 和 TTS 对数据的需求不同。ASR部分的设计围绕着不同的说话人、自然环境和自发的语言生成展开。TTS部分的设计则围绕着受控的录音条件、语音平衡的脚本以及适合合成的更清晰的单说话人音频展开。这种分离在技术上至关重要:一个适用于在嘈杂的真实环境中进行稳健识别的数据集,通常与一个能够生成强大的单说话人 TTS 模型的数据集并不相同。

ASR 数据的收集方式
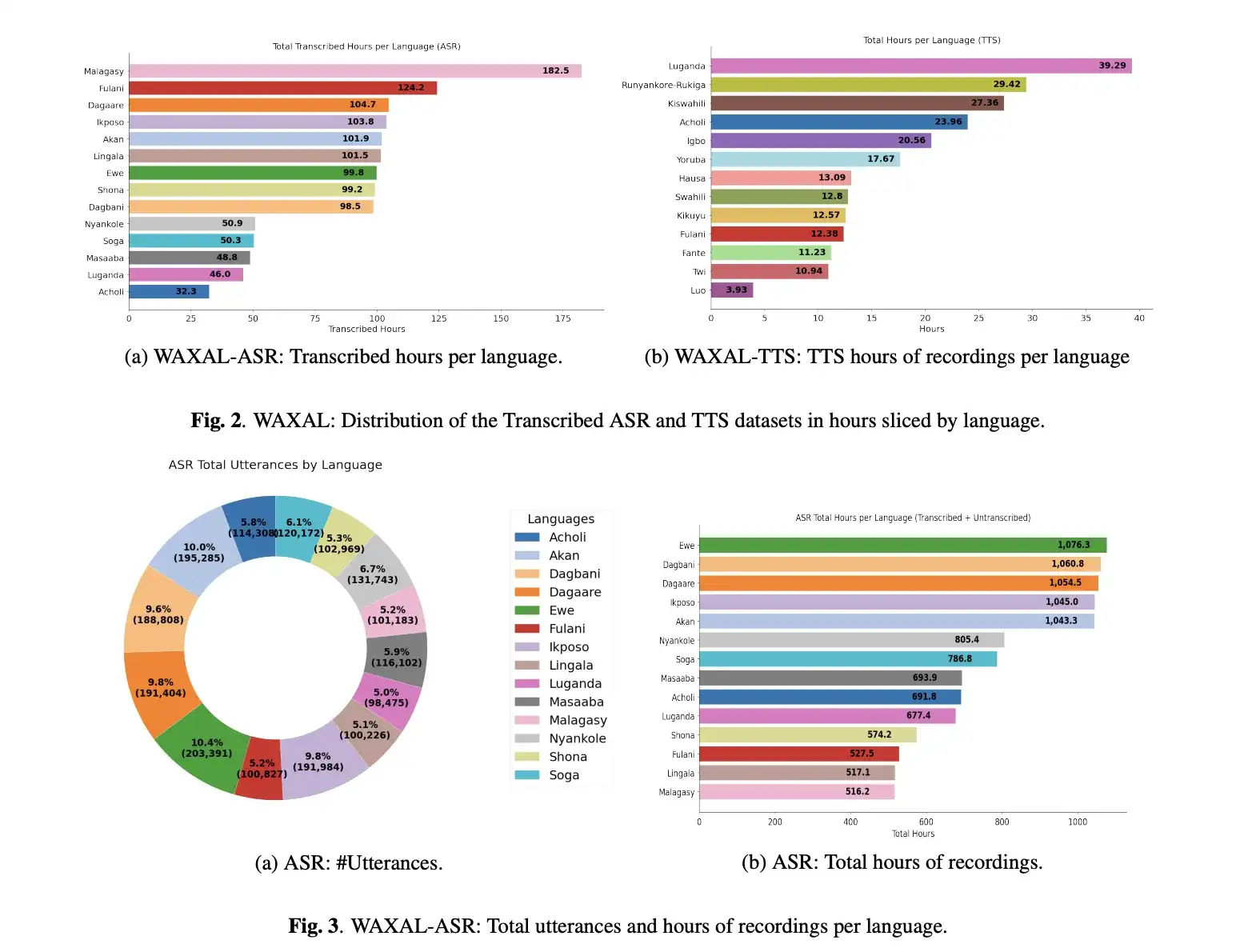
WAXAL 的自动语音识别 (ASR) 部分采用图像提示语音采集。受试者被展示图像,并被要求用母语描述所见内容,这种方式比简单的提示朗读更为自然。录音在受试者的自然环境中进行,每次录音时长至少为 15 秒。采集过程还记录了受试者的年龄、性别、语言和录音环境等元数据。仅对部分采集的音频进行了转录:研究团队表示,当前发布的 ASR 版本包含约 10% 录音的转录文本。这些转录文本由付费的当地语言专家制作,尽可能使用当地文字,否则使用英文字母转写。
对于任何构建多语言 ASR 系统的人来说,这一点都至关重要。图像提示语音往往比严格脚本化的朗读更能捕捉到自然的词汇和句法变化,但也增加了转录难度,并扩大了不同说话人、领域和声学条件下的差异。WAXAL 并没有回避这种权衡,而是充分利用了它。因此,它并非一个完美无瑕的基准数据集;它更接近于一个包含真实变异性的、实地采集的多语言 ASR 数据。
TTS 数据的收集方式
WAXAL 的 TTS 部分构建方式截然不同。TTS 数据集专为高质量的单人合成语音而设计。研究团队为每种目标语言创建了一个包含约 108,500 个单词、语音平衡的脚本。他们邀请了 72 位社区成员参与,男女配音演员人数相等,并在专业的录音棚环境中进行录制,以降低背景噪音并保持音频质量。目标是每位配音演员录制约 16 小时的干净、经过编辑的音频。
这是合成语音的正确设计选择。与自动语音识别(ASR)系统相比,文本转语音(TTS)模型更注重发音的一致性、录音条件、麦克风质量和说话人身份。因此,WAXAL避免了将“语音数据”视为单一类别的常见错误,而实际上,ASR和TTS流程需要截然不同的监督信号。
要点总结
- WAXAL 是一个开放的多语言语音语料库,专为资源匮乏的非洲语言自动语音识别 (ASR) 和文本转语音 (TTS) 而构建。
- ASR 数据采用图像提示的自然语音,在真实环境中采集。
- TTS 数据采用录音棚质量的单声道录音,并配有语音平衡的脚本。
论文地址:https://arxiv.org/pdf/2602.02734
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/65530.html