
本文提出了一种基于学习图像压缩(LIC)的渐进编码(PIC)方案框架。
文章来源:ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM)
论文题目:DeepHQ: Learned Hierarchical Quantizer for Progressive Deep Image Coding
论文作者:Jooyoung Lee, Se Yoon Jeong, Munchurl Kim(韩国电子通信研究院 & 韩国科学技术院)
原文链接:https://dl.acm.org/doi/10.1145/3773994
代码链接:https://github.com/JooyoungLeeETRI/DeepHQ
内容整理:刘昱涵
研究背景与核心问题
研究领域定位
固定码率图像压缩模型,编出不同质量的码流需要多组编解码器。码流之间没有直接联系。(图 1 (a)) 可变码率图像压缩模型,可以用同一个编解码器生成不同质量的码流,但是码流之间仍然关联弱(图 1 (b)) 学习型渐进式图像编码(PIC):一个图像需要被压缩成:基础码流+不同质量等级的附加码流。进行不同位置的截断就可以解码出不同质量的图像。(图 1 (c))


现有方法及其局限
最原始的PIC方案:一遍一遍的重复编码压缩图像&重建图像的残差。效率慢,效果差

现有的学习型PIC方法(如CTC, DPICT)只对潜在表示进行处理。 DPIST把每个 latent 元素被表示为一串三进制数字(trits),并按重要性从高到低逐层传输。 CDC在 DPICT 的基础上引入 上下文模型,进一步减少码率和提升重建质量,但是大大增加了复杂度。 这两种模型采用手工设计的量化层次结构。其基本原理是:为最低质量层设置一个较宽的量化区间,然后通过不断均匀细分这个区间来得到更高质量层。

这种方法假设低质量层的宽区间总是能恰好包含高质量层的窄子区间,但这种固定的、均匀的量化步长假设通常是次优的,因为它没有考虑到不同质量层级、不同图像区域、不同潜在特征通道对量化精度的实际需求差异,从而导致压缩效率的损失。如图4中所展现,本模型在不同通道、不同质量点下的量化步长(彩色实线)更加丰富,贴近需要
本文要解决的问题
因此,本文的核心任务是:摒弃手工设计的量化,提出一种数据驱动的、可学习的分层量化方案,以自适应地决定每个质量层的最佳量化粒度,从而最大化整体率失真性能。
核心技术方案:DeepHQ详解
DeepHQ 的核心创新在于其“学习型分层量化器”以及与之配套的“扩展选择性压缩”机制。
分层量化器
这是DeepHQ的核心模块,其主要构成如下:
- 量化层级:论文旨在生成一个支持 L 个质量等级的渐进式码流。每个质量层 l 对应一个特定的率失真权衡点。
- 可学习量化步长:与固定步长不同,DeepHQ 为每一个量化层级学习一组独立的、可优化的量化步长参数。也就是给潜在变量的每一个通道学习一个特定的量化步长。整个模型需要额外学习的是一个 L * C 的矩阵。
- 分层量化过程:
- 步骤 1:从潜在变量y、超潜在变量z中,通过神经网络估计得到偏差均值μ,处理得到0均值分布的y* = y – μ
- 步骤 2:按层执行分层量化y,找到每一个通道的区间索引 k:输入无偏数据 y、当前层的学习步长 Δₗ、上一层的量化区间 Iₗ₋₁ 给量化模块Q,输出该层区间索引 k。
- 步骤 3:进行索引熵编码,生成码流。高层的量化会生成 “附加位流”,解码时叠加到低层位流上,就能提升质量。

分层量化子区间边界计算
模型经过学习而收敛得到的步长,低层和高层之间不一定是整数倍(比如低层步长 5,高层步长 2)。直接用步长划分区间会导致边界错位,产生碎片区间,最终会导致码率增加、失真变大,压缩效率骤降。
作者设计了临时边界计算 + 边界调整步骤,既保证用模型学出的步长,又避免边界错位和碎片区间
步骤 1:临时边界计算
- 按当前层的学习步长,以上一层的输出y作为中心开始划分区间,得到临时边界 B’;如果划分的边界超出了上一层的量化区间范围,就直接裁剪掉,只保留上一层范围内的边界。

- 实验证明,围绕上一层还原数据(上一个选中量化区间的中点)划分的区间比围绕0划分,压缩效率更高(效果见消融实验);
- 裁剪的目的:避免无效数据。
步骤 2:边界调整 —— 消除碎片区间,保证量化效率
- 裁剪后可能会出现过窄的碎片区间(小于 0.3 倍量化步长),这类区间会让码率增加,所以需要自适应调整。
- 区间数量-2(按照左右对称各减一个),重新计算一个扩展步长,用这个步长在当前范围内重新划分区间,让区间宽度均匀,没有碎片;

概率质量函数(PMF)计算
需要先计算 “每个量化区间被选中的概率”,即量化区间端点的累积概率之差除以总概率,这就是概率质量函数(PMF)。

潜表示分量的选择性编码
为每个量化层设计专属的筛选规则,只挑选该层需要的潜表示分量进行编码,不需要的分量直接置 0(编解码过程中使用y的平均值μ来代替此处的y,使得其码率贡献为0),既保证图像质量,又大幅降低码率。
高层次必须选上低层次选择过的那些分量,以保证一致性。
- 步骤1:生成重要性图,表示码率成本和失真优化的权衡:使用hyper decoder倒数第二卷积层的输出,(包含了从重建的超潜在变量z_hat生成latent_mean和latent_scale的中间特征)执行 1×1 卷积操作,生成与潜表示y尺寸完全一致的三维重要性图 Im(z^),维度为C*H*W,作为重要性的参考。
- 步骤2:每个量化等级有一个单独的C维度向量γ,负责对重要性图加权,具体加权方案设置为乘方运算。
- 步骤3:通过round四舍五入量化,得到确定编码和不编码的位置。量化层内部会根据scale的大小将y再进行排序,以实现更细粒度的码率调节( 162 个渐进压缩点)。
- 步骤4:真正进行量化操作

训练策略
训练了基于balle18的MS以及TCM的两款PIC模型
采用三阶段训练:
- Stage1:训练最高质量的非渐进基础模型(50 epoch)。
- Stage2:联合训练所有8个主质量等级的量化步长和基础网络(20epoch)。
- Stage3:固定量化步长,加入选择性压缩模块(γ 和重要性图网络)继续训练(20 epoch)。
训练时一次性计算8个量化层的率失真,但通过减小batch size(从8降至2)控制显存。
采用了非对称逆缩放方案:使用round(y*scale)*rescale进行运算,rescale和scale是分别学习得到的
实验结果

DeepHQ-TCM 模型相比当前最先进方法 CTC,平均实现了 11.97% 的码率节省,同时参数显著更少(只有 CTC 的 14.19%),解码速度更快(快 11.47 倍)。比较DeepHQ-MS(w/o SC)和 DPICT_MS,证明利用学习步长的量化层级相比现有手工设计的量化层级,在编码效率方面具有显著优势。
所提出的 DeepHQ-TCM 模型在性能更好。TCM中使用了 Swin Transformer 注意力模块,相比 CNN 能够捕捉和利用更广泛的空间上下文,DeepHQ-TCM 对于具有更大图像的数据集(如 CLIC,平均分辨率:1,789.4×1,189.3;Tecnick,1,200×1,200)可能比 Kodak 数据集(768×512 或 512×768)获得更高的压缩效率。
当前 SOTA 方法 CTC将整个码率范围划分为三个区间,并为每个码率区间使用两种专用精炼网络(CRR 和 CDR),导致模型极其庞大且解码时间显著变慢。类似地,DPICT(带后处理)模型在其目标码率范围内分别训练两个专用的后处理网络,显著增加了模型规模。相比之下,我们的 DeepHQ 在整个码率范围内仅使用单个模型,从而避免了模型规模的爆炸,并使我们的模型规模与基础压缩模型相似。当使用 Mean-scale 模型作为基础压缩模型时,我们的 DeepHQ-MS 仅引起 0.59% 的参数开销。

图9的消融实验验证了deephq各模块的作用。 centered表示子区间边界围绕低层重建的对称构建,质量提升显著。消除过小的区间碎片(adjust),节约码率。选择性编码可以进一步提升性能。

在衡量画面真实感的LPIPS指标方面,DeepHQ性能同样出色。

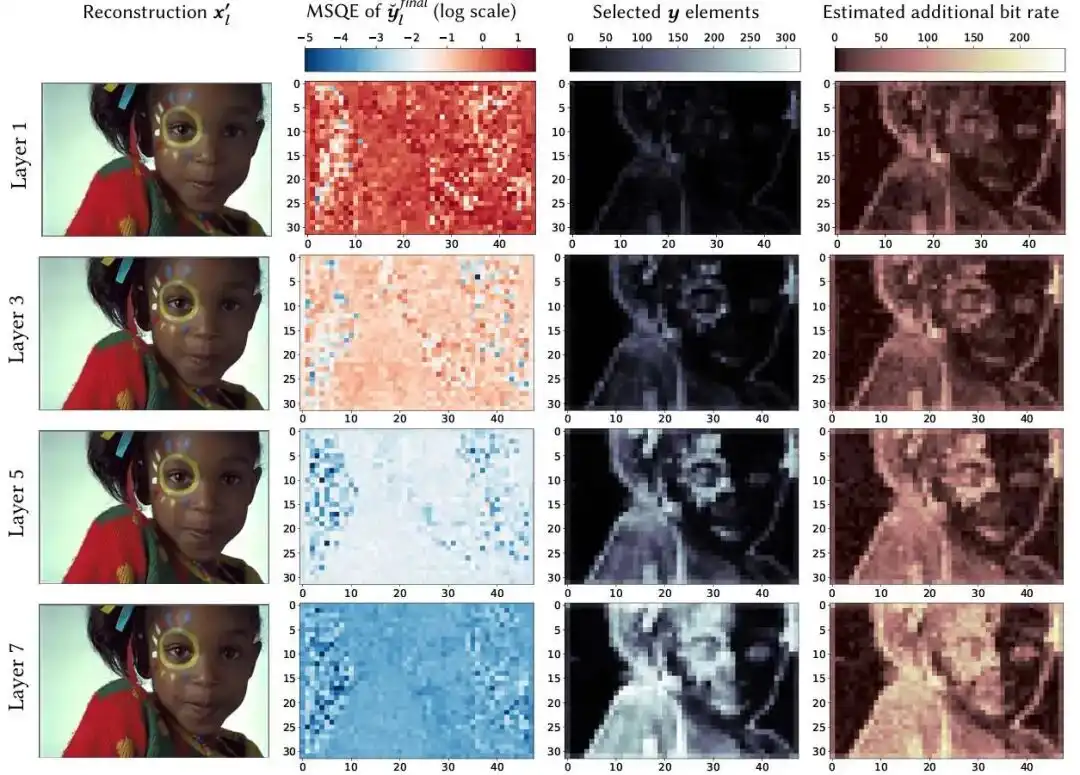
随着量化层数量的增加,量化误差、选中的表示分量数量以及逐层码率消耗如何变化。量化误差随着量化层数的增加逐渐减小。选中的表示分量随量化层的增长而增加,图像中复杂度较高的区域倾向于涉及更多的表示分量。低质量压缩的比特消耗主要分配在轮廓周围。相比之下,随着压缩质量的提高,分配比特的部分往往转向纹理区域。
结论
在本文中,我们提出了一种名为 DeepHQ 的学习型渐进式图像压缩方法。该方法基于为每个量化层学习得到的量化步长进行压缩。此外,我们提出了一种扩展的选择性压缩方法,仅对每个量化层中必要的表征元素进行压缩,从而进一步提高了压缩效率。与当前学习型渐进式编码研究领域中最先进的性能相比,我们的 DeepHQ 方法在模型参数数量显著更少、解码速度明显更快的情况下,实现了更高的编码效率。此外,DeepHQ 还能够稳定支持细粒度的逐分量渐进式编码。在未来的工作中,我们将研究一种将分层量化方案与整个模型进行完全联合训练的方法。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。