
内容摘要:本文介绍了一种基于坐标的低复杂度分层图像编码器 (COOL-CHIC) ,它是一种能够替代自编码器的方法,每个解码像素仅对应 629 个参数和 680 次乘法。COOL-CHIC 的压缩性能接近现代常规 MPEG 编码器,如 HEVC ,并且性能与流行的基于自编码器的系统不相上下。这种方法受到基于坐标的神经表示的启发,其中图像被表示为一个学习的函数,将像素坐标映射到 RGB 值。然后使用熵编码发送映射函数的参数。在接收端,通过所有像素坐标的映射函数来获得压缩图像。
论文名称:COOL-CHIC: Coordinate-based Low Complexity Hierarchical Image Codec
作者及机构:Theo Ladune, Pierrick Philippe, F ´ elix Henry, Gordon Clare, Thomas Leguay ´
Orange Innovation, France
文章来源:ICCV 2023
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Ladune_COOL-CHIC_Coordinate-based_Low_Complexity_Hierarchical_Image_Codec_ICCV_2023_paper.pdf
代码链接:https://orange-opensource.github.io/Cool-Chic/
整理人:何冰
端到端图像或视频编码与隐式神经表示
为了使得方法的介绍更清晰,本节将简要分析隐式神经编码与以往端到端编码在训练过程以及传输码流部分的区别。
简言之,端到端的图像或视频编码会使用可学习的编解码器学习原视觉数据的复杂高效变换,原本冗余信息很多的视觉数据在变换后的新域拥有紧凑表达。在整个数据集上训练结束后,编解码器即可被直接用于类似的图像或视频数据的压缩。解码器被提前传输到解码端,因此在编解码具体图像或视频时,只需要获得并传输其紧凑表达即可。端到端方法使用神经网络高效地学习视频数据中的统计信息,因此能够达到比传统方法更好的压缩效率。
隐式神经表示则没有编码器结构,无论是在编码端还是解码端,其过程都是时空相关的信息输入可学习的解码器网络,获得特定位置的视觉信息。每个图像或者视频数据的压缩都需要从头开始训练网络,其压缩原理并非利用统计信息,而是简单粗暴地通过过拟合来获取是视觉数据的紧凑表示。(或者说整个网络的结构是不同压缩内容的先验/统计,而网络的参数则完全是因内容而异的)在传输过程中,需要传输时空相关的信息和解码器网络权重。
编码时间
端到端编码器一旦训练结束,其在编码具体视觉信息过程中仅需要进行一次网络的前向传播即可。而隐式神经表示的每次编码过程都需要从头训练网络。在编码时间上,端到端编码更有优势。
解码时间以及复杂度
解码时,两种方法均是进行一次网络的前向传播,而隐式神经表示的网络结构很简单,因此在解码时间和复杂度上会有显著优势。
编码性能
图像隐式神经表示尚未成熟,其压缩性能发展非常迅速,考虑BD-rate,每一代比前一代提升大概20个百分点。目前最新的图像隐式神经编码器 C3 (后续的文章会介绍)可以达到与VTM相近的性能,BD-rate 落后 MLIC+ (端到端方法)大概10个百分点。
COOL-CHIC 编码器整体介绍
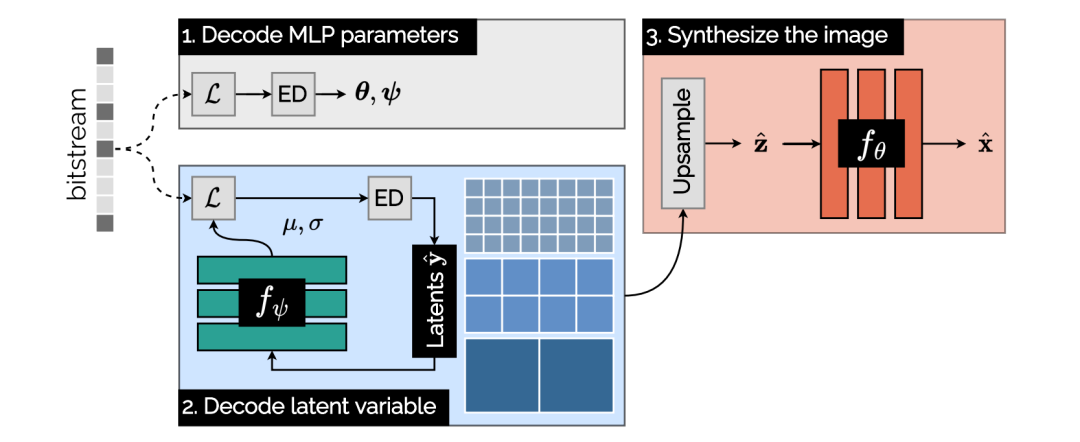

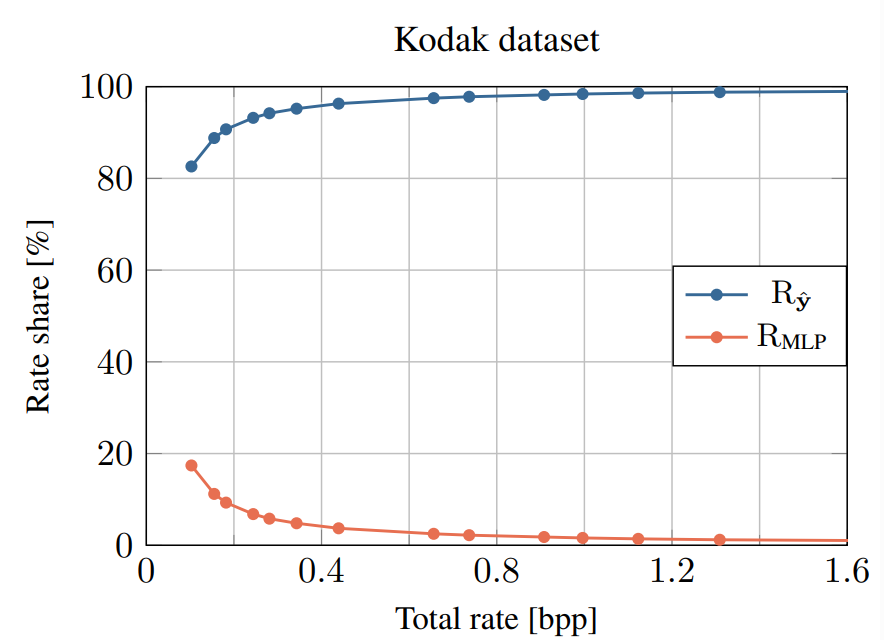
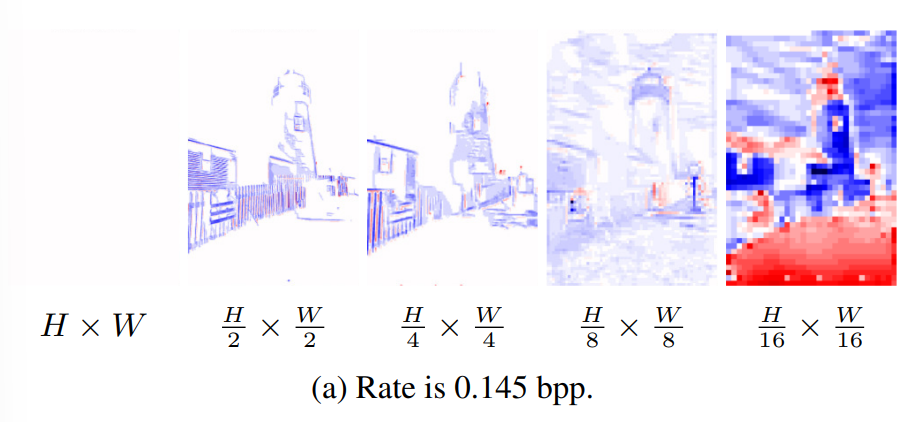
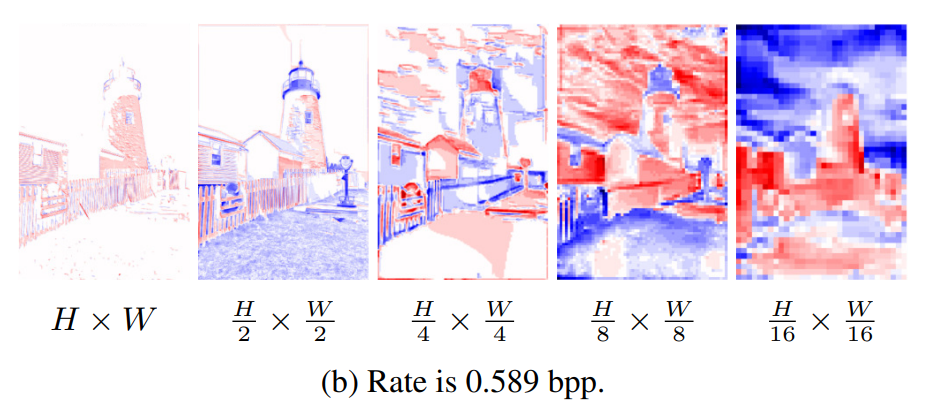
码流文件包括三部分,分别是,自回归概率MLP模型权重 θ(绿色),生成MLP网络权重 ψ(红色),latents权重 ŷ(蓝色)。其中 θ 和 ψ 可被直接熵解码,其码率大小占整个码流文件大小的 20% 以下,高质量的图像会扩大 latents ŷ 的层数以及尺寸,而固定 θ 和 ψ的大小,因此码率越高,两个MLP的码率占比越小。由于latents ŷ 存在空间相关性,因此使用自回归概率模型进一步减小其大小。在解码时码流需要通过该自回归概率模型恢复出完整的latents ŷ 信息。
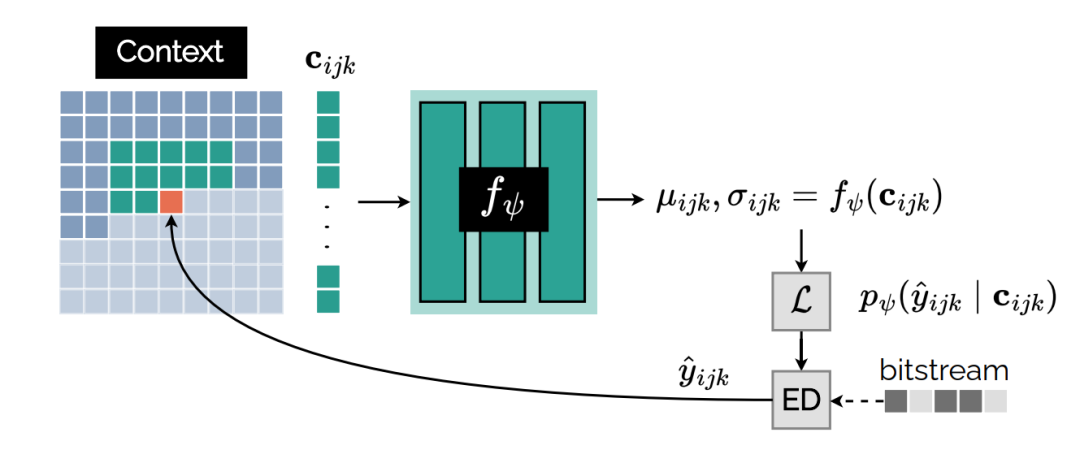
自回归概率模型
在训练过程中,向latents ŷ 中加入噪声以减少后续量化带来的性能下降
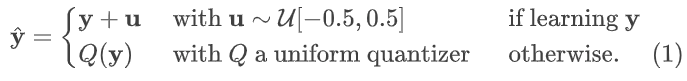
采取了学习型编码的常用技术,通过已解码的 latent 对未解码的 latent 进行概率预测以获得更紧凑的表示。
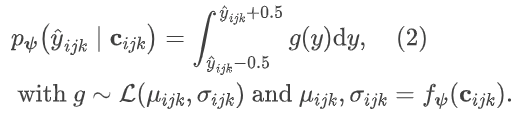
latents 升采样过程
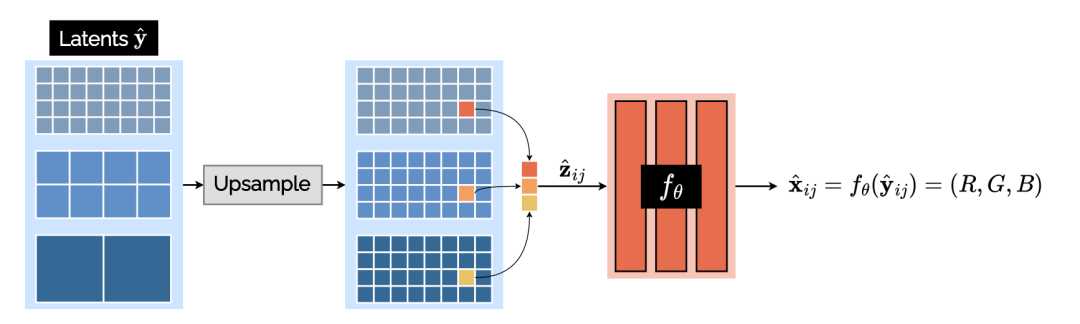
不同分辨率的 latent 在升采样至最大分辨率后进行级联,以获得当前位置的特征 。其通过生成网络以获得某点像素的 RGB 值。
损失函数
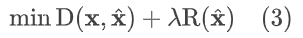
训练过程的损失函数同时考虑码率和失真,其中码率部分由于 latents ŷ 占码率绝大部分,因此以其码率作为整体的码率的近似,像素级别的输出,使用 MSE 作为失真指标。
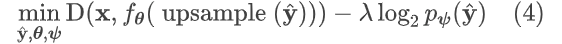
MLP模型压缩过程
θ 和 ψ的参数是在训练结束后进行离线量化和熵编码。使用不同量化步长进行量化, 其具体步长通过遍历搜索得到,旨在最小化整体的率失真。
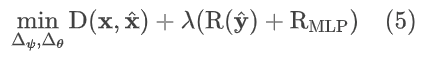
并且同样使用拉普拉斯分布对量化后的模型参数进行分布估计,以 θ 参数为例:
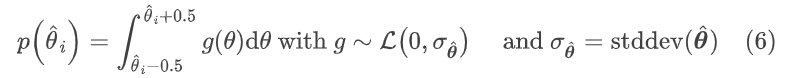
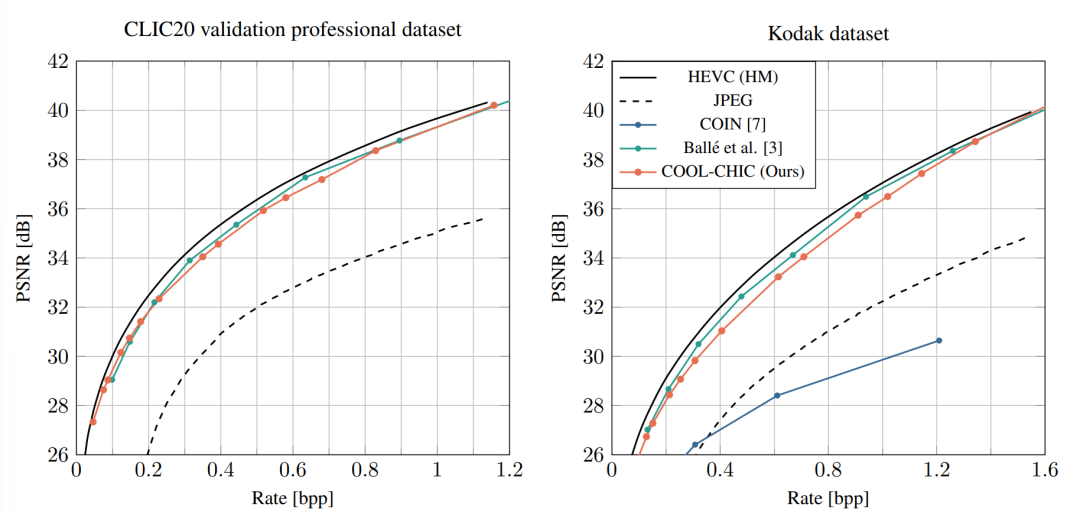
实验及结果
可以看到,COOL-CHIC的压缩性能可以与HEVC相比拟。
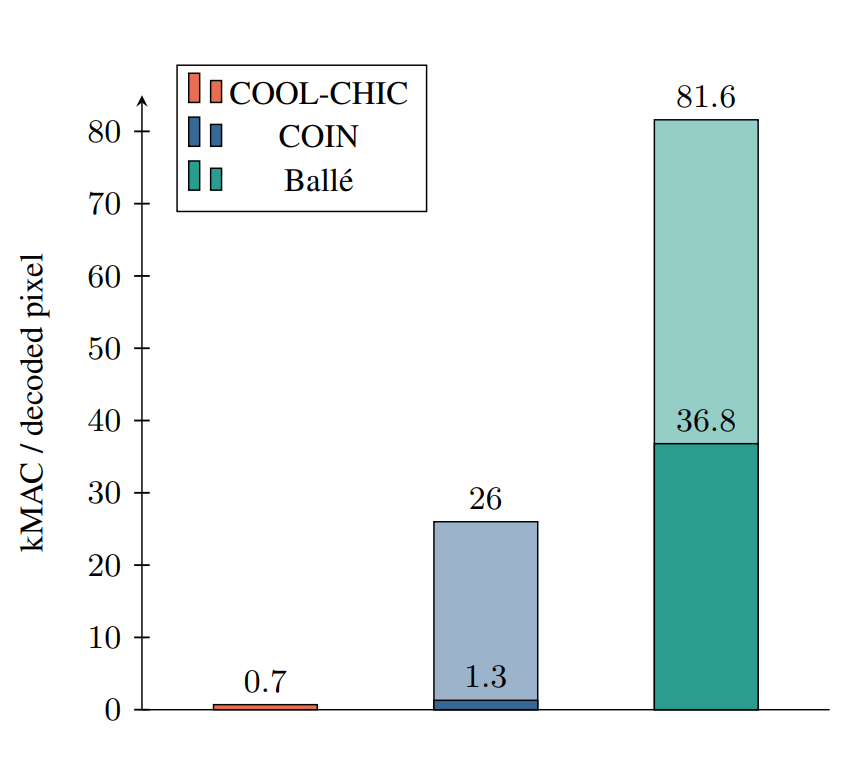
其解码复杂度相较于 COIN (上一代基于坐标的图像编码方案)和 balle 的端到端图像编码方案相比,有显著的解码复杂度下降。
可视化
最后文章对于其 latents 做了一些可视化。更大尺寸的 latent 可以学到更精细的细节。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。