
本文主要介绍了面向电商直播场景的全模态理解大模型 TLiveOmni 在 vLLM 框架下的推理部署与量化优化全过程。文章详细阐述了如何通过自定义插件注册、修复多模态Token交替排布及浮点运算顺序等手段,解决vLLM原生架构对Omni模型支持不足及精度漂移的问题。在此基础上,团队采用了 SmoothQuant与GPTQ结合的复合量化方案,并构建了包含5000条高质量数据的校准集以最大限度保留模型效果。最终在H20与RTX 4090硬件上的实测表明,该方案在保证各模态任务精度损失控制在1.5%以内的前提下,实现了2.5倍至3.5倍的推理加速,且针对不同硬件特性总结出了FP8(H20)与W4A16(4090)的最优部署策略。
作者:谦宇,直播AIGC团队
来源:大淘宝技术
01 引言
在大模型的发展进程中,评估视角已不再局限于算法性能指标,而是越发关注推理效率与响应时延等部署侧表现。目前大模型的部署方案多围绕文本大模型(LLM)。然而,随着多模态大模型(VLM)的快速发展,引入了视觉、音频等多模态数据,这对整个大模型的推理系统是一个新的挑战。
本文以 TLiveOmni(针对面向电商直播场景设计的全模态理解大模型)为例,对大模型的实际部署进行了探索与对比分析。核心内容包括:自定义模型的vLLM[1]架构适配、vLLM的精度漂移修复,以及SmoothQuant[2]与GPTQ[3]结合的复合量化方案。最后在H20与RTX 4090等硬件平台进行加速验证。
02 vLLM 框架概览
在大型语言模型的实际落地中,训练与部署通常采用不同的框架。训练框架侧重于反向传播、梯度计算等,主要目标是最大化算力利用率以缩短训练周期。而推理部署框架则围绕推理速度、显存利用率及系统吞吐量。
目前,主流的大模型推理框架有:NVIDIA推出的TensorRT-LLM[4] ,基于TensorRT的LLM推理加速库,能充分发挥NVIDIA GPU硬件能力;vLLM利用PagedAttention机制优化了显存管理,获得了更高的吞吐量;SGLang[5]凭借其RadixAttention技术在复杂多轮对话和长上下文场景中展现出显著优势;Ollama[6]则通过简化的部署流程在个人开发及轻量级本地应用中广受欢迎。
vLLM推理部署
我们选择vLLM作为核心推理框架,主要基于以下三个考量:
- 高效显存管理:vLLM通过类虚拟内存的分页管理机制(PagedAttention),将KV Cache离散存储,显存碎片率降低 30% 以上。
- 极致吞吐与调度:vLLM采用异步动态批处理(Continuous Batching)技术,打破了传统静态Batch的等待限制,显著提升了高并发场景下的请求吞吐。
- 生态与标准化:兼容OpenAI API规范,并原生支持Llama、Qwen等主流架构,为TLiveOmni模型的快速迭代与下游集成提供了成熟的基础设施。
vLLM推理的主要挑战
- 多模支持缺陷:vLLM在处理长视频输入时存在引擎死锁(#28375)及多模态模型精度大幅下降(#29595)等遗留问题。
- 版本迭代断裂:vLLM v1在v0.11.1(2025.11.19)版本提供了对Omni模型的推理支持,但Omni模型的推理在部分场景下仍存在结果的异常(#30776)。Qwen3-Omni官方针对vLLM框架进行了适配,但官方适配版本为停止维护的vLLM v0版本,无法复用vLLM在v1重构所带来的优化增益。
- 异构框架导致的精度漂移:训练端(ms-swift[7]、Megatron-LM[8]、LLaMA-Factory[9])与部署端(vLLM)模型的实现方式不同,导致计算结果存在差异。
03 TLiveOmni 模型架构与vLLM架构适配
TLiveOmni 模型
TLiveOmni是一款面向电商直播场景打造的全模态理解大模型,原生支持图像、文本、音频与视频的统一输入,实现了128K上下文窗口,单次可深度解析长达12分钟的直播视频流。构建了覆盖音频、视频、图像维度的超20项精细化原子能力。包括音频维度的语境感知ASR与多说话人分离,视频维度的商品时序切分与直播卖点提取,以及图像维度的商品空间定位与细粒度OCR,实现了对直播内容的全面解构。
模型架构
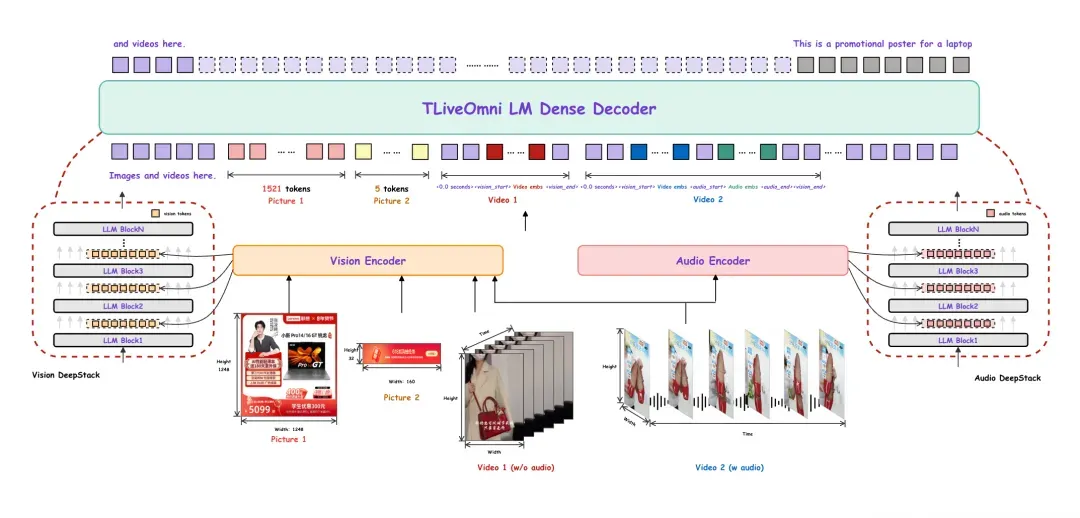

TLiveOmni模型以Qwen3-VL-Instruct[10] 模型为核心基座,其原生架构已具备强大的跨图文模态理解能力。在继承基座模型基础结构的同时,参照Qwen3-VL[11]中使用的Vision DeepStack方式,设计了Audio DeepStack模块。该模块保持了与AuT中的Aligner相同的结构,由两个线性层与一个激活函数层组成。
vLLM架构适配
模型注册:由于我们自定义的模型模型不在vLLM官方支持的列表中,需要对模型进行注册。采用Out-of-tree models方式,通过Plugin来注册我们的模型,无需修改vLLM源码。
def register():
from vllm import ModelRegistry
from your_code import YourModelForCausalLM
# 注册后,vLLM 即可通过 config.json 中的架构名识别并加载该模型
ModelRegistry.register_model("YourModelForCausalLM", YourModelForCausalLM)多模态数据处理

vLLM的数据前处理过程如图2所示,分为数据预处理、Token排布、Embedding映射三个阶段。本质是建立 “占位符 → Token序列 → Embedding向量” 的三级映射关系,具体如下:
- 数据预处理(
tlive_process):多模态数据的读取与向量化 - 标识与排布
- 定义标识 (
get_placeholder_str):指定Prompt中的多模态Token模版,例如<video_pad>。 - token展开与排布(
prompt_updates):完成特定Token的展开。例如,一个<video_pad>,替换成 N 个连续的视觉占位Token。
- 定义标识 (
- 向量对齐与更替
- 实际更替(
_maybe_apply_prompt_updates):当Token序列已经排布好后,模型通过Encoder计算出N个Embedding向量。根据展开后的Token位置,自动将这些向量填入对应的位置,完成Token到Embedding的映射。
- 实际更替(
根据这三个阶段我们进行TLiveOmni相应的适配。
04 框架适配与精度对齐
大模型的训练与推理通常采用不同的框架,训练过程多使用Transformers库,而部署则会选择更加高性能的vLLM推理引擎。但是由于这两者在底层实现上存在差异,会导致在相同的输入下得到不同的输出。为了保证训练和推理的一致性,需要对vLLM进行训练框架的适配实现精度对齐。
多模态对齐
Interleave 排布修复
在vLLM的默认多模态处理框架中,_maybe_apply_prompt_updates 函数负责将多模态特征(视觉或音频Embedding)映射到对应Token位置。
- 对于常规模型(如 LLaVA[12]):多模态输入(图像或视频)对应的Token排布是连续的。vLLM默认将所有特征Embedding拼接成一个连续序列,再填入对应的连续区间内。
- 对于Omni模型(TLiveOmni):在处理带有音频的视频时,进行交替排布的设计,Vision Token和Audio Token是交替排布的(即:V, A, V, A…)。
vLLM默认的连续拼接逻辑与TLiveOmni模型的交替排布架构不匹配。如果强行按照vLLM默认方式处理,会导致映射错位。连续的视觉 Embedding会覆盖掉Audio Token的位置,导致映射的错位,由于Embedding的错位,会近一步导致模型输出和训练存在误差。下图直观展示了常规连续排布与TLiveOmni模型交替排布在vLLM映射过程中的差异。因此我们对这部分代码进行了修复,保证最终Token和Embedding的排布方式和训练时是一致的。

- Audio token自动 Padding
在vLLM的多模态处理逻辑中,为了优化Cache的效率(保证特征维度是 8 的倍数),会在音频特征提取前进行padding操作。而padding会导致最终Token长度的不一致,具体如下:

为了保持输出一致性,选择去除vLLM中Audio特征自动补全的部分。这样音频采样点将严格按照原始长度进行后续处理,确保生成的Token数量与预训练时一致。
- 浮点运算差异
在vLLM推理过程中,发现在进行 deepstack 相加时出现了精度误差。具体为,vLLM和Transformers对于 deepstack 和 residual 部分相加的先后顺序不同。

虽然数学上A+B+C=(A+C)+B,但在GPU浮点运算中:
- 非结合律:浮点数运算不满足加法结合律,每一步加法都会进行一次截断/舍入。
- 量级淹没:
residual通常输出大。先加大数还是先加小数,会导致低位信息的丢失程度不同。 - 误差累积:这种微小的舍入差异随模型层数逐层放大,最终导致输出精度漂移。
为了消除这一部分的差异,我们修改vLLM的计算逻辑,确保deepstack和residual的计算顺序和Transformers一致。
通用对齐
- Flash-Attention 差异
在同一模型中,Vision模块的Attention计算结果与Transformers一致,而Language模块却存在差异,这是因为后端实现路径不同。通过源码对比发现,vLLM对两种模态采用了完全不同的Attention后端:
- Vision模块(Qwen3-VL等):
- 调用函数:直接调用Flash-Attention官方的
flash_attn_varlen_func。 - 特点:直接使用
flash_attn库,计算逻辑与训练实现完全对齐,因此结果一致。
- 调用函数:直接调用Flash-Attention官方的
- Language模块(vLLM ):
- 调用函数:调用vLLM自定义的算子
torch.ops.vllm.unified_attention_with_output。 - 特点:这是vLLM为了适配KV Cache管理(如PagedAttention)、推理加速而专门重写的算子。
- 调用函数:调用vLLM自定义的算子
由于vLLM的自定义算子在CUDA实现层面与原版Flash-Attention在累加精度、Scaling处理或算子融合上存在微小差异,导致了最终结果的不一致。这一差异当前版本无法解决,但带来的精度误差在可接受范围内。
- RSNorm对齐
vLLM原生的RMSNorm采用了高度优化的CUDA算子(如fused_add_rms_norm),虽然速度快,但在处理residual加法和数据类型转换的顺序上,与Transformers的原生实现存在微小偏差。具体如下:

因此对vLLM这部分的Norm进行了替换。为什么要替换 Norm?因为Q、K的Norm结果有1e-4级的误差,这一量级的精度误差是无法忽略的。并且误差会经过Attention矩阵乘法后会被放大、累积,最终影响模型性能。
04 模型量化方案
模型量化
- 量化概念简介
1、量化的优势
模型量化是实现大模型工业级部署、降低推理成本的关键技术。其核心优势体现在:
- 极大释放显存:通过将大模型权重(如72B、235B-A22B等)进行INT4或INT8量化,可释放约50%-75%的显存空间。这使得大模型能够运行在消费级显卡(如 RTX 4090)或显存较小的单机多卡环境中。
- 显著降低延迟:大模型推理的Decoding阶段通常受限于访存(Memory-Bounded)。量化后,权重与激活值的位宽减小,算子访存压力降低。配合现代 GPU 的低精度计算单元(如 Tensor Core),可显著缩短执行时间。
2、量化对象与维度
模型量化的对象主要包括以下几个方面:
- 权重(Weight):权重量化是最常用的量化,用于减少模型占用显存。
- 激活(Activation):推理过程中的中间值量化,不仅可以减少显存占用,结合权重的量化可以进行整型算子加速(W8A8)。
- KV Cache:在长文本生成中,KV Cache往往会占用大部分显存,对其进行量化可以提高长序列的处理能力。
- 梯度(Gradients):主要应用于训练阶段,通过量化来缓解网络带宽压力,加速反向传播过程。
3、量化精度与数据格式
在量化领域,我们通常用 WxAy 的表示法来描述量化的方案,“W”代表权重的位数,“A”代表激活值的位数。除此之外,还存在FP8量化,这是由NVIDIA推出的新一代量化格式,目前在H100, L40S 等新一代 GPU 上得到原生硬件支持。

4、量化阶段与分类
根据量化发生的时机,可分为以下两类:
- 量化感知训练 (QAT,Quant-Aware Training): 也可以称为在线量化。它需要利用额外的训练数据,在量化的同时结合反向传播对模型权重进行调整,确保量化模型的精度和训练时保持一致。
- 后练后量化 (PTQ,Post Training Quantization):也可以称为离线量化。它是在已训练的模型上,使用少量或不使用额外数据,对模型量化过程进行校准,其中:
- 训练后动态量化(PostDynamic Quantization)不使用校准数据集,直接对每一层layer通过量化公式进行转换。QLoRA[13]就是采用这种方法。
- 训练后校正量化(Post Calibration Quantization)需要输入训练校准数据集,根据模型每一层layer的输入输出调整量化权重,GPTQ就是采用这种方法。
5、量化方法
目前量化方案主要分为以下几类:
- 通道级量化(Channel-wise):如 LLM.int8[14]、SmoothQuant、AWQ。通过对不同通道应用不同的缩放因子来处理激活值或权重的分布。
- 基于优化目标的方法:如GPTQ。通过最小化量化前后输出的误差来优化权重。
- 基于旋转矩阵的方法:如QuaRot[15]、SpinQuant[16]。通过旋转变换消除激活值中的离群点(Outliers)。
量化方案选择
我们采用了SmoothQuant与GPTQ相结合的复合量化思路:利用SmoothQuant优化激活值中的离群点;利用GPTQ优化权重参数,最大程度保留模型精度。
- SmoothQuant
SmoothQuant是一种PTQ 方法,其核心在于解决离群点 (Outliers) 的问题:当 LLM 参数量超过7B后,激活值中会出现远超均值的离群点(通常比正常值大100倍以上)。如果我们使用 INT8 量化,大多数的激活值将被清零。SmoothQuant通过数学等价变换,引入平滑因子s,将激活值的离群点转移到权重上(因为权重分布通常更平滑、更易量化),从而实现了高精度的量化。

- GPTQ
GPTQ的思想最初来源于Yann LeCun在1990年提出的OBD[17]算法,随后OBS[18]、OBC(OBQ[19]) 等方法不断进行改进,GPTQ是OBQ方法的加速版。OBD实际上是一种剪枝方法,用于降低模型复杂度,提高泛化能力。具体为:如果要在模型中去除一些参数(即剪枝),直觉上想,我们希望去除对目标函数影响小的参数。即希望找到一个量化过的权重,使新的权重和老的权重之间输出的结果差别最小:

GPTQ正是沿用这一思路,通过最小化量化前后的权重差异,来对每个layer选择合适的量化参数。
量化数据抽取策略
为了在降低模型权重精度的同时最大限度保留TLiveOmni模型的效果,我们设计了如下校准集抽取逻辑:任务完整性: 校准集必须覆盖模型所有训练过的任务指令和能力边界。任务难度/敏感度: 识别出那些对数值波动极其敏感的任务,并给予更多的样本权重。低敏感任务(感知型):比如短Caption(”一张桌子”)。高敏感任务(精度型):OCR/Markdown:一个像素的激活偏差可能导致“8”量化成“0”,或者Markdown结构符丢失。Visual Grounding(空间定位):权重的微小扰动会使边界框漂移几十个像素。Temporal Grounding(时序定位):微小的扰动会导致最终时间轴的偏移。
模态完整性:指校准集必须包含模型涉及的所有输入模态组合及其时间/空间维度。
确保校准集包含图像、视频、音频、文本及其所有组合形式,涵盖不同的时空维度特征,最终形成了共计 5,000 条 高质量数据的校准池。
06 性能评测与硬件对比
TLiveOmni性能分析
- 精度评估
- 硬件环境:单卡H20。
- 量化方案:采用SmoothQuant与GPTQ结合的复合量化策略
- 量化参数:主要针对Language Model部分进行量化。

实验数据表明,各量化方案的精度损失均严格控制在 1.5% 以内。其中,FP8量化的精度损失最小,在图像与视频任务中甚至呈现微弱的性能提升。
- 推理速度测试
- 硬件环境:单卡H20。
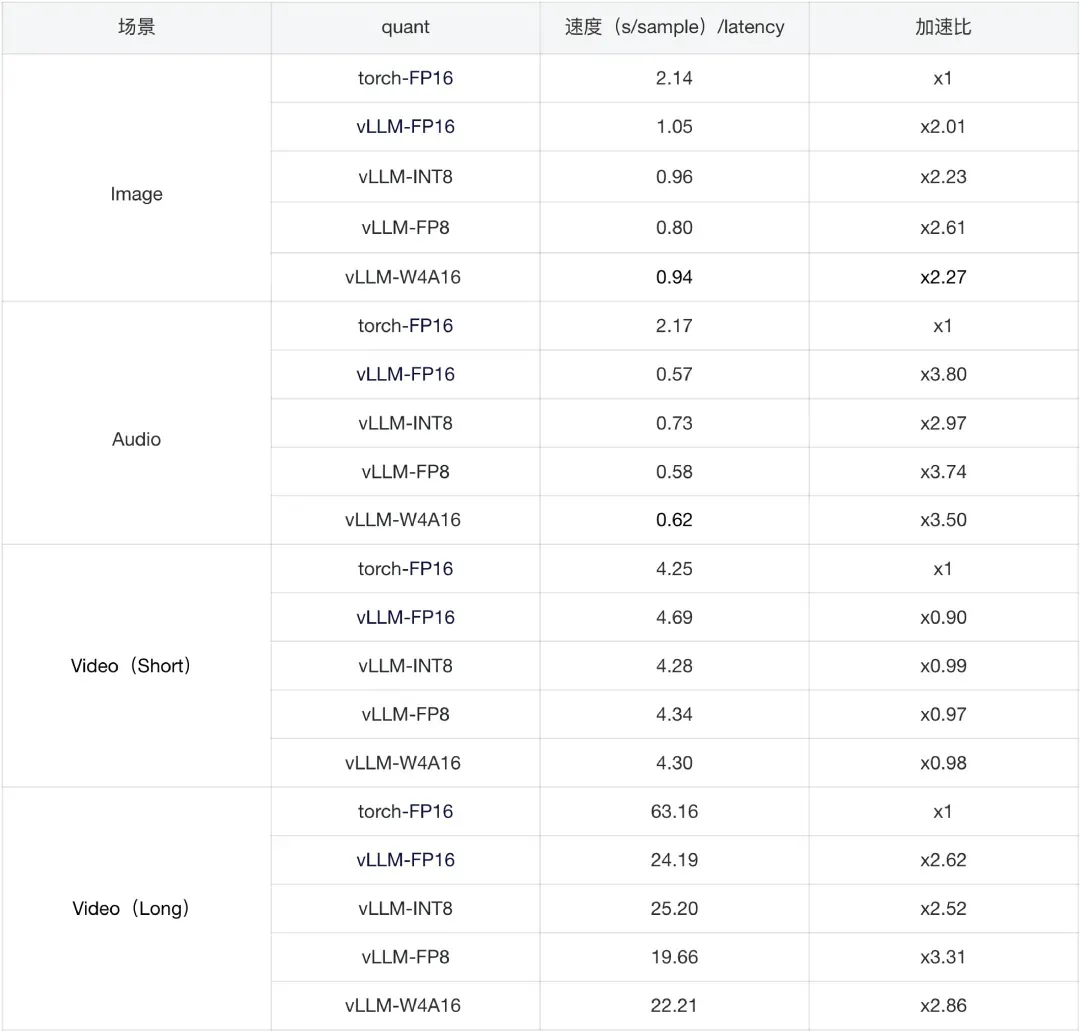
经过量化的TLiveOmni模型在图像、音频及长视频任务中均取得了显著的加速收益。W8A8/FP8量化后的综合加速比分布在 2.5x 至 3.5x 之间。Video(Short)加速收益不明显,主因在于 vLLM 的多模态预处理效率低于 Torch,产生的时延在总耗时中占比过高,掩盖了推理端的加速增益。相比之下,Video(Long)虽同样存在预处理时延,但因其推理阶段耗时更长,预处理占比相对较低,从而使 vLLM 的推理加速优势得以更充分地体现。后续可以通过对 vLLM 预处理函数进行定制化重构,以消除该阶段带来的时延。
异构硬件对比 (H20 vs. RTX 4090)
针对4090与H20两种典型硬件,我们进行了全场景性能压测。
- 下表展示了在不同模态任务下,各量化方式的加速比。我们测试了图像、音频、视频(长、短)以及文本任务下,vLLM在不同量化方式下的推理速度(s/sample)。

针对H20与RTX 4090在多模态全场景下表现,基于实测数据(表7)得到如下结论:
1. H20推理性能显著优于RTX 4090
实测结果显示,H20在绝大多数场景下的绝对时延均显著低于RTX 4090。
- 长序列表现:在视频长场景下,H20的耗时(最优方案 19.66s)相比4090(最优方案 30.74s)快了约 54%。
- 加速稳定性:H20在FP16、INT8、FP8等多种量化路径下均能得到最短的延时。
2. 访存瓶颈 vs. 算力瓶颈
两款显卡表现的差异源于其硬件差异:
- H20:长视频任务涉及20k Prefill+4k Decode,属于典型的访存密集型场景。H20搭载的96GB HBM3显存拥有极高的读写宽带,约3.6TB/s,能够支持超长文本序列KV Cache的实时读取。
- 4090:主要受限于带宽与显存。其GDDR6X显存带宽远低于HBM3,带宽约1TB/s。在长序列解码阶段,频繁的访存请求导致GPU算力不能高效利用。同时,4090的48G显存在应对超长上下文时,显存空间利用已近极限,需要不断管理、切换显存切片,导致近一步的时延。
3. 量化方案的硬件偏好性
不同硬件平台对量化格式存在不同的偏好:
- H20 -〉FP8
- H20所属的Hopper架构原生集成了高性能FP8 Tensor Core。在FP8模式下,H20不仅通过低位宽减轻了访存压力,更通过更高效的FP8算子计算近一步提升计算速度。
- 4090 -〉W4A16
- 在4090上,W4A16 在所有模态中均取得了最优加速比(如 Audio 达 2.1x,Long Video 达 1.6x)。对于带宽和显存受限的4090而言,将权重压缩至4-bit极大减少了权重搬运的时间开销,并节省显存用于存放 KV Cache。
4. 其他发现:前处理与 CPU 频率的影响
在图像和音频等多模态数据推理中,我们发现硬件整体Latency不仅取决于GPU:
- CPU频率影响:H20与4090所在主机CPU频率差异,直接影响了多模态数据(图片解码、特征提取)的前处理速度。
5. 部署方案总结
基于以上两种硬件对比结果,我们提出以下建议:
- 大规模生产/长序列业务(如电商直播、视频密集描述):
- 首选方案:H20 + vLLM-FP8。
- 理由:利用 HBM3高带宽和Hopper架构,可获得最佳的加速比。
- 边缘计算/显存受限场景:
- 首选方案:RTX 4090+vLLM-W4A16。
- 理由:通过极致的4-bit权重量化突破48GB显存容量瓶颈,使其也能胜任20k以上的长序列多模态推理。
- 系统级优化:
- 部署多模态模型时,应同步关注CPU侧的算力。优化数据加载,减少前处理在整个推理生命周期中的占比。
07 参考文献
- vLLM: https://github.com/vllm-project/vllm
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models https://arxiv.org/pdf/2211.10438
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers https://arxiv.org/pdf/2210.17323
- TensorRT-LLM https://github.com/NVIDIA/TensorRT-LLM
- SGLang https://github.com/sgl-project/sglang
- Ollama https://github.com/ollama/ollama
- ms-swift https://github.com/modelscope/ms-swift
- Megatron-LM https://arxiv.org/abs/1909.08053
- LLaMA-Factory https://arxiv.org/abs/2403.13372
- Qwen3-VL Technical Report https://arxiv.org/pdf/2511.21631
- Qwen3-Omni Technical Report https://arxiv.org/pdf/2509.17765
- LLaVA:Visual Instruction Tuninghttps://arxiv.org/abs/2304.08485
- QLoRA: Efficient Finetuning of Quantized LLMs https://arxiv.org/abs/2305.14314
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale https://arxiv.org/abs/2208.07339
- QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs https://arxiv.org/abs/2404.00456
- SpinQuant: LLM quantization with learned rotationshttps://arxiv.org/abs/2405.16406
- Optimal Brain Damage https://proceedings.neurips.cc/paper_files/paper/1989/file/6c9882bbac1c7093bd25041881277658-Paper.pdf
- Optimal brain surgeon and general network pruning https://www.babak.caltech.edu/pubs/conferences/00298572.pdf
- Optimal Brain Compression: A framework for accurate post-training quantization and pruning https://openreview.net/pdf?spm=a2c6h.13046898.publish-article.15.65286ffaa2V6mQ&id=ksVGCOlOEba
08 团队介绍
本文作者谦宇,来自淘天集团-直播AIGC团队。作为直播电商智能化领域的先行者,始终致力于通过AI原生技术创新重构电商直播场景中的人货场交互范式。团队基于对大语言模型研发、多模态语义理解、语音合成、数字人形象建模、AI工程化部署及音视频处理技术的深厚沉淀和积累,已搭建起覆盖直播全链路的AI技术矩阵。自主研发的数字人直播解决方案通过商业化验证,成功实现从技术研发到商业变现的完整闭环,累计服务上千家商家。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。