
在电影《侏罗纪公园》中,当观众看到巨型恐龙朝自己走来时,会自然而然联想到低沉、轰鸣的脚步声,仿佛大地都在震颤。这是因为人类对声音的预判,不仅依据物体外形,还会结合尺寸、质量、运动速度等物理属性。
不过,现有的视频转音频生成 AI,主要基于视频中的物体类别与场景信息生成音效,似乎未能充分体现随质量、速度变化的物理规律。
韩国科学技术院(KAIST)、浦项科技大学(POSTECH)、索尼人工智能实验室(Sony AI)的研究团队合作,研发出一项名为PAVAS(Physics-Aware Video-to-Audio Synthesis,物理感知视频转音频合成)的人工智能技术,可理解视频中的物理场景并生成更逼真的音效。相关研究成果发布于 arXiv 预印本平台。


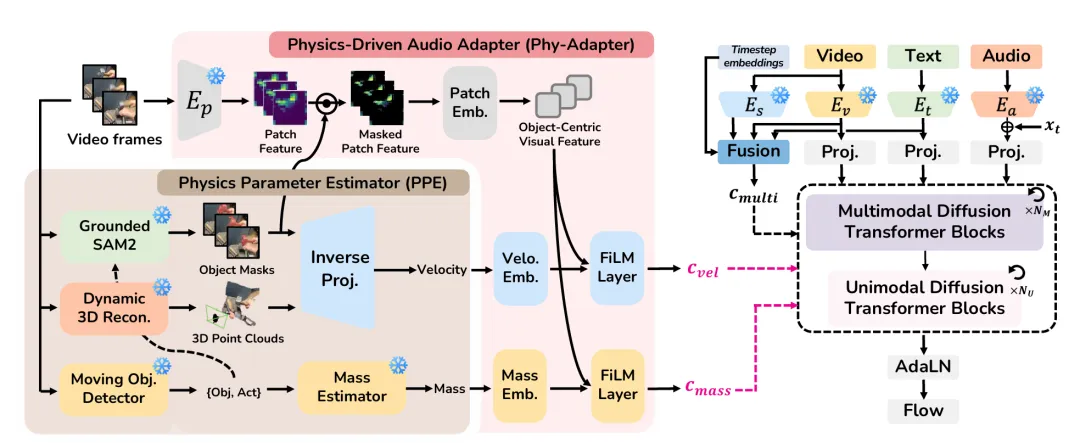
该技术的核心创新在于:让 AI 自主推断视频中物体质量、速度等不可见物理参数。普通视频不会标注物体的精确重量与速度数值,研究团队通过分析物体所处环境与运动特征,让 AI 完成物理量估算,并将结果融入音效生成流程。
简言之,这款 AI 不再仅识别 “画面里有什么”,而是理解 “为何会发出这种声音” 的物理成因。
技术验证结果显示,在物体碰撞、撞击等物理交互场景中,该 AI 生成的音效高度贴近真实环境;尤其当物体质量与速度发生变化时,音效的响度、音色会随之自然变化,还原度显著提升。

近年来,音视频同步生成的 AI 技术发展迅猛,典型代表如谷歌 Veo 3、字节跳动 Seedance 2.0 等。但在影视、广告、游戏等实际制作场景中,为已有视频匹配并补充适配音效的后期制作需求,远高于全新音视频生成需求。
现有商用 AI 模型多聚焦音视频联合生成,而 PAVAS 的核心差异在于:精准分析视频中物体的运动与碰撞特性,生成与场景高度匹配的逼真音效。
迈向物理一致性生成式 AI
研究团队表示,该技术为物理一致性生成式 AI领域开辟了新可能。物理一致性生成式 AI,不再仅生成视觉上合理的结果,而是真正理解现实世界的物理规律与因果关系。
未来,这项技术有望广泛应用于内容音效制作自动化、增强现实(AR)/ 虚拟现实(VR)内容、元宇宙、机器人仿真等领域,为用户带来更具沉浸感的体验。
研究人员指出,现有生成式 AI 的发展多依赖数据与模型规模的提升,而本研究的价值在于,让 AI 直接理解物理量与因果关系。未来它可拓展为下一代多模态 AI 的核心基础技术,实现文本、视频、语音等多类型信息的统一理解与处理。
论文信息:Oh Hyun-Bin et al, PAVAS: Physics-Aware Video-to-Audio Synthesis, arXiv (2025). DOI: 10.48550/arxiv.2512.08282
信息源于:techxplore
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。