
近年来,超低码率视频压缩已成为一个关键的研究领域。然而,现有的视频压缩方法在超低码率下难以保持足够的性能,这通常表现为感知质量下降,包括细节丢失、纹理模糊和图像伪影,以及重建视频与原始视频之间存在不一致。为应对这些挑战,本文提出一种基于多模态大模型(LMM)的视频语义压缩方法(LMM-VSC)。该框架包括:(1)语义信息提取器,用于从输入视频中提取语义信息;(2)视频编码器,用于以超低码率压缩输入视频;(3)混合解码器,将语义信息与高度压缩的比特流进行融合。实验结果表明,在超低码率条件下,该方法将比特率降低了68.4%的同时保持了与H.265参考软件相当的感知质量。
文章来源:IEEE International Symposium on Circuits and Systems (ISCAS) 2026
论文题目:LMM-VSC: Ultra-Low Bitrate Video Compression with Semantic Understanding
论文作者: Chaolei Liu, Li Song, Chuqin Zhou, Guo Lu (SJTUMedialab)
原文链接:https://ieeexplore.ieee.org/document/11562543
内容整理:刘潮磊
简介
随着视频内容在灾区救援、远程监控、在线通信和长期存储等场景中被广泛使用,如何在极低带宽或极低存储成本下保持可用的视频质量,已经成为视频压缩中的重要问题。尤其是在带宽资源严重受限,或需要长期保存海量监控视频的场景中,超低码率视频压缩具有很高的实际价值。然而,现有方法在超低码率条件下面临明显挑战:
- 极低码率下信息不足: 传统视频编码器和学习式压缩方法通常依赖运动估计、残差编码或特征压缩。当码率降低到 0.02 bpp 以下时,可分配的信息量极少,难以保留足够的画面细节。
- 感知质量明显下降: 在超低码率下,重建视频容易出现细节丢失、纹理模糊、块效应和压缩伪影,导致主观视觉体验明显变差。
- 生成式重建存在语义漂移: 图像生成模型虽然具备较强的细节恢复能力,但如果只依赖文本语义描述或生成先验,可能生成视觉上清晰、但与原始视频内容不一致的画面。
- 高层语义信息利用不足: 现有视频压缩方法大多关注像素、运动、残差或特征层面的压缩,较少显式利用视频中的对象、场景和语义关系来辅助重建。
针对上述问题,本文提出了 LMM-VSC,一种由多模态大模型驱动的超低码率视频语义压缩框架。它的核心思想是将视频压缩从单纯的像素或残差信息编码,扩展为“低码率参考视频 + 高层语义信息”的联合建模。具体来说,LMM-VSC 首先利用多模态大模型从原始视频中提取简洁的语义描述,再通过超低码率视频编码器生成参考视频,最后由混合解码器融合语义信息和参考视频,重建出视觉质量更高且语义一致的视频结果。本文的主要贡献如下:
- 提出 LMM-VSC: 将多模态大模型的视频理解能力和生成式模型的细节恢复能力引入超低码率视频压缩。
- 设计语义信息提取器: 从输入视频中提取精炼的全局语义描述,在几乎不增加码率开销的情况下为解码过程提供内容约束。
- 构建混合解码器: 结合低码率参考视频和语义描述,在提升纹理细节与感知质量的同时,缓解生成模型带来的语义不一致问题。
- 在多个数据集上综合测评: 在 HEVC Class B、UVG 和 MCL-JCV 等数据集上的实验表明,LMM-VSC 在超低码率条件下相比传统编码器和学习式压缩方法取得了更好的感知质量和一致性表现。
方法描述
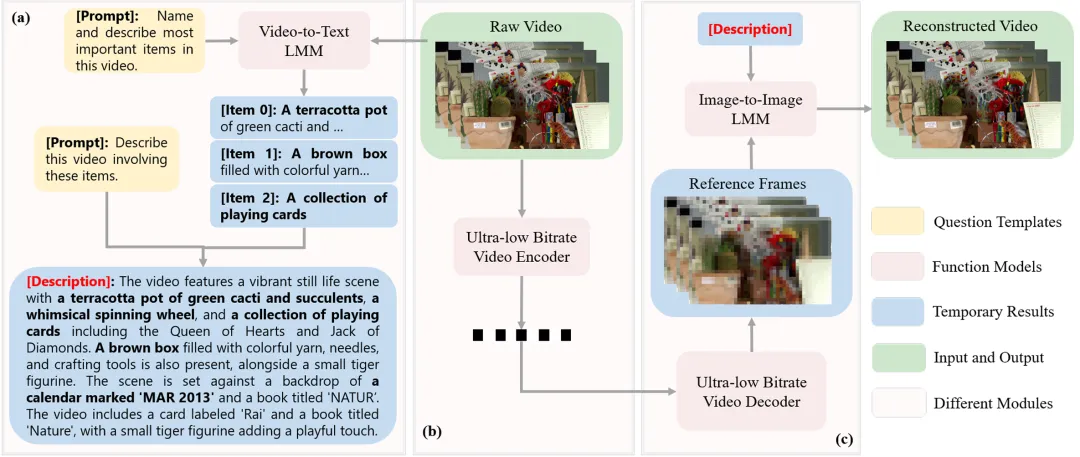

语义信息提取器
该模块使用多模态大模型从输入视频中提取精炼的语义信息,并将这些信息传递给后续的混合解码器。它的作用不是直接恢复像素,而是为生成过程提供语义约束,使解码器在补充细节时不会随意生成,而是尽量围绕原始视频内容进行重建。这样,最终视频不仅能获得更好的感知质量,也能保持与原视频较高的一致性。
论文中还提出,语义描述并不是越详细越好。如果描述过长,多模态大模型可能会关注一些感知上并不重要的细微内容,反而导致关键区域出现纹理模糊、细节不稳定或一致性下降。因此,LMM-VSC 在语义信息提取器中采用了两阶段处理策略。第一阶段,模型先识别视频中的关键对象,并生成较详细的对象级描述,例如对象名称、颜色、外观等属性,用来引导模型关注视频中的重要区域。第二阶段,系统再基于这些对象级描述,综合生成一段全局视频语义描述。
超低码率视频编码器
将生成模型引入视频压缩时,一个重要挑战是语义不一致。生成模型虽然可以显著改善画面观感,补充纹理和细节,但如果只依赖文本语义描述来恢复视频,很容易生成“视觉上合理、但与原始视频不一致”的内容。为了解决这一问题,LMM-VSC 引入一个超低码率视频编码器,将原始视频压缩成极低码率的比特流。这个比特流随后会被解码成一个参考视频。参考视频可以作为混合解码器的重要约束,防止生成模型过于自由发挥。
混合解码器
该模块将语义信息提取器输出的文本描述和视频编码器产生的压缩码流结合起来,用于重建最终视频。混合解码器包含两个关键组成部分:一是视频解码器,用来从超低码率比特流中恢复低感知质量的参考帧;二是视频优化器,用来同时处理参考帧和原始视频的语义描述,生成具有更高感知质量的最终视频帧。最终,LMM-VSC 实现的是一种“低码率参考视频 + 高层语义信息 + 生成式细节恢复”的混合重建机制。
实验设计与验证
实验设置与系统实现
数据集
论文在多个公开视频数据集上评估 LMM-VSC 的超低码率视频压缩性能,包括 HEVC Class B、UVG 和 MCL-JCV。这些数据集覆盖了不同类型的视频内容,用于验证方法在多种场景下的泛化能力。
对比方法
主要包括两类:一类是传统视频编码标准的参考软件,包括 HM-16.25 和 VTM-17.0,分别对应 HEVC/H.265 和 VVC;另一类是学习式视频压缩方法,包括 DCVC-DC 和 DCVC-FM。其中,DCVC-DC 的开源实现对超低码率支持有限,因此它只能在部分码率范围内参与比较,例如在 HEVC Class B 上支持约 0.022-0.035 bpp,在 MCL-JCV 上支持约 0.013-0.024 bpp。
评价指标
评价指标分为两类:
- 一致性指标:使用 PIEAPP,衡量重建视频与原始视频的接近程度,数值越低越好。
- 感知质量指标:使用 MUSIQ、NIQE、BRISQUE,衡量重建视频本身的视觉质量。其中 MUSIQ 越高越好,NIQE 和 BRISQUE 越低越好。
实现细节
论文中 Video-to-Text LMM、Image-to-Image LMM 和视频编码器分别采用 InternVideo2.5、Flux-1-dev-ControlNet-Upscaler 和 DCVC-FM 的默认参数。所有实验在 NVIDIA A100 Tensor Core GPU 上进行。
率失真性能实验

在 0.02 bpp 以下的超低码率条件下,LMM-VSC 在感知质量上整体优于 HM、VTM、DCVC-DC 和 DCVC-FM。
具体来看,LMM-VSC 在 MUSIQ、NIQE、BRISQUE 等无参考指标上表现更好,说明它生成的视频更清晰、伪影更少。在 0.015 bpp 以下,LMM-VSC 的 PIEAPP 也明显更低,说明它在极低码率下还能保持更好的内容一致性。
主观视觉结果

本文的可视化结果表明,LMM-VSC 在相近码率下能恢复更多细节,例如人脸、边缘和鞋子纹理。
相比之下,传统方法容易出现块效应和模糊,学习式方法在极低码率下也会丢失较多细节。LMM-VSC 通过语义信息和参考视频共同引导重建,因此画面观感更自然,同时内容没有明显偏离原视频。
消融实验结果

消融实验主要验证两个设计:语义信息提取器(SIE)和不同 Image-to-Image LMM 的选择。
结果表明,加入语义信息提取器后,模型在一致性和感知质量上都有提升,说明语义描述确实能帮助重建更准确、更清晰的视频。
此外,使用 Flux 的效果明显优于 SDXL,因此论文最终采用 Flux 作为混合解码器中的图像增强模型。
结论
LMM-VSC 的价值在于把“大模型的理解与生成能力”引入视频压缩,尤其面向传统方法最困难的超低码率场景。它不是简单地让生成模型凭空补画面,而是用“语义描述 + 极低码率参考视频”共同约束重建过程。
论文实验表明,LMM-VSC 可以在极低码率下获得更好的视觉质量,并保持较高的语义一致性。整体来看,这是一种很有启发性的方向:未来的视频压缩可能不再只是压缩像素和运动信息,也会压缩并利用视频的高层语义。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。