
近年来,零样本语音复刻技术快速发展,AI 已经能够仅凭一段文本和一小段参考音频,合成出自然度颇高的目标说话人语音。然而,在生成质量持续提升的同时,一个更基础的问题仍未被认真回答:
模型是否一定要先生成一段中间声学表示,再交给独立的声码器把它”渲染”成波形?
主流零样本 TTS 普遍采用这种”先生成中间表示、再渲染波形”的两阶段范式。模型先预测 mel 频谱、声学 token 或潜空间表征,再由一个单独训练的 vocoder 完成最终的波形合成。这套范式之所以流行,是因为它把语音生成与波形渲染解耦,使训练和工程都更易控制。代价则是,推理阶段始终要保留一个外部声学接口和一个独立声码器,模型从未真正离开”中间表征 + 声码器”的依赖。
BareWave正是为这一问题而提出。它定义并实现了一个全波形原生(waveform-native)的流匹配 TTS 框架:在推理时,BareWave 仅保留一个直接生成波形的生成器,输入文本与参考音频,输出目标说话人的波形采样点,不依赖任何中间声学表示,也不外接独立声码器。
项目主页(含音频 demo):https://barewave.github.io/


什么是全波形原生零样本 TTS?
BareWave 提出了一个更彻底的零样本 TTS 设定:从文本与一小段提示音频出发,单一模型直接生成目标说话人的波形采样点,整条推理路径上不引入任何中间声学表示(mel 频谱、声学 token、潜空间表征等)、不外接预训练编码器、也不附加单独的声码器。
简单来说,BareWave 将”语音生成”与”波形合成”压缩进同一个模型,由它一次性完成全部工作,从而把整个零样本 TTS 的推理图,简化为一条从文本和提示音频直达波形采样点的直接生成路径。
BareWave 是怎么做到的?
BareWave的核心设计可以概括为两个部分:
直接基于波形的模型架构,和基于表征对齐、噪声调度和速度感知对齐的训练流程。
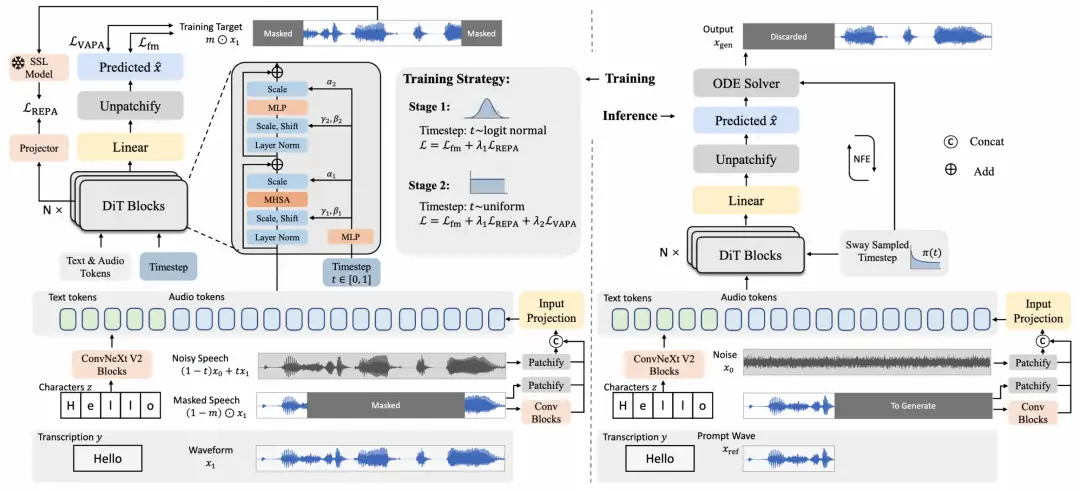
模型架构
BareWave 的生成器直接构建在波形 patch 上。原始波形先经一维卷积 patchify 切成 patch token,作为生成器的主信号流;提示音频以两条平行路径接入——一条直接采用原始波形 patch 以保留细粒度时域信息,另一条经卷积前端下采样至 patch 速率以提供更全局的上下文,二者拼接形成层级化的提示流。
文本侧以 character 粒度进入,先由轻量 ConvNeXt 块处理,再作为 in-context token 注入序列左侧。整体序列由 DiT 块处理,配合时间步调制与旋转位置编码,预测 patch-wise 干净波形,再经 unpatchify 还原为采样点。
训练流程
训练流程围绕三项设计展开:训练期表征对齐、分阶段噪声调度,以及速度感知感知对齐(Velocity-Aware Perceptual Alignment, VAPA)。三者只作用于训练阶段,推理阶段全部移除,生成器的推理路径不会因此变重。
首先,BareWave 采用训练期表征对齐为波形生成器注入语音先验。 在原始波形上从零训练,模型缺少一个像 mel 或 codec 空间那样天然带先验的”工作台”。BareWave 选取生成器中间层的一处隐状态,经过一个轻量对齐头后,与一个冻结的 WavLM 教师特征做余弦对齐。
对齐分支只在训练阶段挂在生成器一侧,推理时连同教师一起整体移除。这相当于在原始波形空间中借入了一份隐性的预训练结构,让 BareWave 更稳地组织语言、说话人与声学信息。
其次,BareWave 引入分阶段噪声调度,让训练在不同阶段聚焦不同的子问题。 流匹配训练对噪声水平 t 的采样分布非常敏感:早期希望快速收敛,更适合把 t 集中在中等噪声;后期则希望细化低噪声端的预测,更适合把更多采样落在接近干净端的状态。

BareWave 因此采用两段式调度——前段使用 logit-normal 分布,把训练聚焦在中等噪声以加速收敛;越过预设切换点后,调度切换为均匀分布(uniform),使采样覆盖更多清洁状态,便于在训练的后期进一步打磨细节。最后,BareWave 在流匹配损失之外引入一个谱域感知损失,并通过速度感知缩放(VAPA)让其与流匹配损失的时间结构对齐。 波形生成往往需要使用频谱距离作为感知损失。然而在 BareWave 采用的 x-预测/v-loss 框架下,流匹配损失会对数据空间预测误差引入一个 1/(1-t)² 的隐式时间权重,在接近清洁端被显著放大;而数据空间中带固定系数的多分辨率 STFT 感知损失并不携带这一权重,相对强度在低噪声区间反而被压低。为此,BareWave 在感知损失上施加一项 (1-t)^(-γ) 的时间缩放,使其随时间增长的强度与流匹配损失对齐;γ = 1 时正好对应 L1 谱距离在 x-空间到 v-空间转换中获得的缩放比例。感知损失仅在训练后期启用,把谱域感知细化真正落在最关键的时间区间。
实验结果:内容更清晰,说话人更相似
BareWave 在 Seed-TTS test-en 与 LibriSpeech-PC test-clean 两个零样本语音复刻基准上进行了系统评估,统一沿用 F5-TTS 的评测协议,报告内容清晰度 WER、说话人相似度 SIM-o 与感知自然度 UTMOS。
在同等训练数据条件下(Emilia 英文子集,约 19.4k 小时),BareWave 在 Seed-TTS test-en 上的 WER 与 SIM-o 在同等数据系统中均为最佳;在 LibriSpeech-PC 上取得 2.88% WER 与 0.614 SIM-o,相较中间表示路线的同档基线,三项指标均有竞争力。
这说明,BareWave 在不依赖任何中间表征与外部声码器的前提下,依然能在内容清晰度(WER)与说话人保持(SIM)上达到与中间表示路线相当甚至更优的水平。

总结
BareWave 给出了一份完整的全波形原生零样本 TTS 训练方案:在推理侧坚持极简,把表征对齐、分阶段噪声调度与速度感知感知对齐留在训练侧,分别回应波形空间在先验、调度与感知监督上的三类挑战。实验结果表明,全波形原生流匹配 TTS 完全可以作为零样本语音合成的一条可行方向:在不引入任何中间声学表示或独立声码器的前提下,达到甚至超过同训练数据的中间表示系统的零样本表现。
相关文献参考:
[1] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. 2023. Flow Matching for Generative Modeling. In International Conference on Learning Representations.
[2] Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Yang, Jiaqi Li, Peiyang Shi, Yuancheng Wang, Kai Chen, Pengyuan Zhang, and Zhizheng Wu. 2024. Emilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation.
[3] Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, and Furu Wei. 2022. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing. IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518.
[4] Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. 2025. Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think. In International Conference on Learning Representations.
[5] Cheng Luo, Zexu Pan, Bingjie Lu, Shengkui Zhao, Hexin Liu, Jiaqi Yip, Eng Siong Chng, Trung Hieu Nguyen, and Bin Ma. 2025. WaveFM: A High-Fidelity and Efficient Vocoder Based on Flow Matching.
[6] Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, Jian Zhao, Kai Yu, and Xie Chen. 2025. F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics.
[7] Sefik Emre Eskimez, Xiaofei Wang, Manthan Thakker, Canrun Li, Chung-Hsien Tsai, Zhen Xiao, Hemin Yang, Zirun Zhu, Min Tang, Xu Tan, Yanqing Liu, Sheng Zhao, and Naoyuki Kanda. 2024. E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS. In IEEE Spoken Language Technology Workshop (SLT).
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。