
来源:AIMS AL Lab
Demo: https://wsssy.github.io/cocoemo_demo/
GitHub: https://github.com/wsssy/CoCoEmo
Paper: https://arxiv.org/pdf/2602.03420
背景:为什么情感语音合成还不够“像人”?
近年来,Text-to-Speech(TTS)系统在自然度、音色相似度和零样本合成方面取得了显著进展。然而,现有情感 TTS 大多仍将情绪建模为单一、全局、整句级别的条件,例如“开心”“悲伤”或“愤怒”。
但真实交流中的情绪往往更加复杂:一句话可能同时包含开心、失落、紧张等多种情绪;文本语义与声音情绪也可能并不一致。例如,一个人可以用平静甚至讽刺的语气说出积极文本,也可以用悲伤的声音表达中性的内容。
核心问题:
我们能否让 TTS 不只是“说出某一种情绪”,而是生成更接近人类表达的复杂情绪, 并在文本语义与声音情绪不一致时仍然稳定控制语音情感?
CoCoEmo:基于 Activation Steering 的复杂情感 TTS 框架
我们提出 CoCoEmo(Composable and Controllable Human-Like Emotional TTS via Activation Steering [1]),一种轻量、可组合、可控的情感语音生成框架。不同于重新训练模型或设计复杂 emotion prompt,CoCoEmo 直接在预训练 hybrid TTS 模型的中间激活空间中注入 emotion steering vector,从而引导模型生成目标情感表达。
CoCoEmo 主要回答三个问题:
1. Where to steer?
情感主要编码在 hybrid TTS 的哪个模块、哪一层、哪类操作中?
2. How to steer?
如何构造 emotion steering vector,并通过向量组合实现 mixed emotion 控制?
3. How to evaluate?
如何评价 mixed emotion 和 text-emotion mismatch 这类复杂情感表达?
CoCoEmo 的三大核心贡献
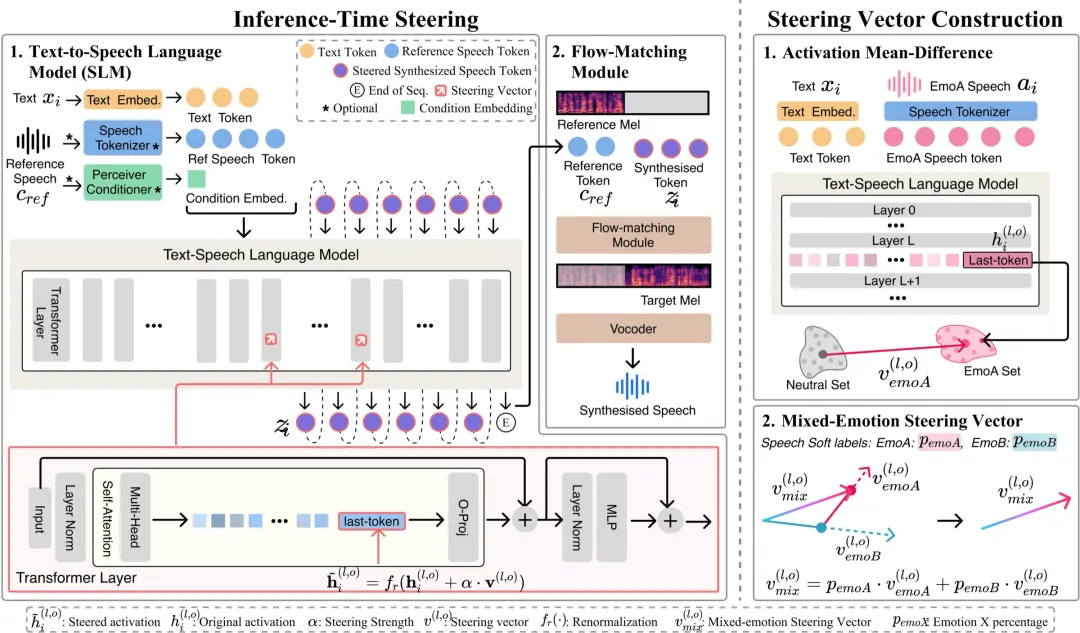

1. 系统分析 hybrid TTS 中的情感表征:SLM 更适合进行情感 steering
现代 hybrid TTS 通常包含两个阶段:Speech Language Model(SLM) 负责根据文本和条件生成离散语音 token;Flow-Matching Acoustic Model 负责将语音 token 转换为声学特征。
CoCoEmo 首先分析情感更适合在哪一阶段进行控制。实验发现,相比后端 flow-matching 模块,SLM 对情感韵律和表达变化具有更清晰的区分能力。当情感信息作用于 SLM 时,不同情绪在能量、语速和韵律模式上呈现出更明显的差异。进一步的 layer/operator 分析显示,SLM 的中后层以及 attention output 通常具有更高的情感线性可分性,更适合进行 activation steering。
我们在另一篇工作 A Geometric Perspective on Composable Emotion Steering in Text-to-Speech Models [2](ICML Workshop 2026)中进一步发现,SLM 相比 Flow-Matching模块具有更清晰、且跨说话人更稳定的情感子空间,因此更适合作为 activation steering 的位置。
2. 提出可组合的 emotion steering 方法,实现复杂控制
CoCoEmo 使用 mean-difference 的方式构造单一情绪方向向量,并在推理阶段将其注入选定的 SLM 层和操作中,引导模型向目标情感方向生成语音。
更进一步,CoCoEmo 支持将多个情绪向量按比例组合,例如:
- 70% happy + 30% sad
- 50% angry + 50% surprise
- 40% happy + 30% sad + 30% angry
CoCoEmo 支持对不同情绪方向进行比例化组合, 而不是局限于单一情绪标签。
3. 构建面向复杂情感表达的评估协议
传统情感 TTS 通常依赖单标签 emotion accuracy 或 MOS 评价,但这不足以衡量 mixed emotion。对于混合情绪,我们不仅关心目标情绪是否出现,还关心情绪比例是否合理,以及语音质量、说话人相似度和可懂度是否保持稳定。
因此,CoCoEmo 新引入多维评估指标,包括:
- Emotion Similarity (E-SIM):合成语音与目标语音的情感相似度;
- Target Emotion Probability (TEP):目标情绪概率;
- Spearman’s Correlation (ρ):情绪增长排序与目标混合情绪排序的一致性;
- Dominant Hit Rate (H-Rate):主导情绪是否被正确增强;
效果:混合情感与情绪冲突场景下更稳健的控制表现
CoCoEmo 在 CREMA-D 和 IEMOCAP 上进行评估,并测试了 CosyVoice2 和 IndexTTS2 两类代表性 hybrid TTS backbone。
实验结果显示,CoCoEmo 能够更稳定地控制 mixed emotion。在合适的 steering strength 范围内,CoCoEmo 提升了 E-SIM、Spearman’s ρ 和 H-Rate,同时基本保持说话人相似度和语音可懂度。
在 text-emotion mismatch 场景下,baseline 的情感控制效果会随着 mismatch 程度升高而明显下降;而 CoCoEmo 仍能持续增强目标声音情绪,尤其在 high-mismatch 设置下表现更明显。这说明 CoCoEmo 可以更直接地引导声学情感表达,减弱文本情绪偏置对语音生成的干扰。
为什么 CoCoEmo 适合复杂情感 TTS?
CoCoEmo 的优势在于,它不是简单地给模型额外输入一个情绪标签,而是直接调节模型内部与情感表达相关的表征。这带来三点好处:
- 轻量:无需重新训练 TTS backbone;
- 可组合:不同情绪向量可以按比例组合,支持 mixed emotion;
- 框架可复用:可迁移到不同 hybrid TTS 系统,只需提取对应 backbone 的 steering vectors。
应用前景:更自然、更细腻的情感语音生成
CoCoEmo 为下一代可控语音合成系统提供了新的可能性,尤其适合需要复杂情绪表达的场景:
- 有声书与角色配音
- 情感陪伴与人机交互
- 情感计算研究
同时,更强的情感语音控制能力也需要负责任地使用。在真实人声相关应用中,应重视授权、合成语音披露以及滥用防护机制。
参考文献
[1] Wang, S., Tan, S., Liu, S., Jia, H., Huang, G., Bailey, J. and Dang, T., 2026. CoCoEmo: Composable and Controllable Human-Like Emotional TTS via Activation Steering.
[2] Wang, S., Bailey, J. and Dang, T., 2026. Geometric Perspective on Composable Emotion Steering in Text-to-Speech Models.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。