
大多数网络并非为人工智能而建。关键在于:您的网络能否跟上带宽、计算能力和安全需求的激增,还是会落后于时代?人工智能工作负载对基础设施的挑战远超传统数据中心设计的预期,而适应最快的企业将赢得竞争优势。
本文将探讨每个企业为迎接人工智能驱动的未来必须解决的关键网络考量。
别让资源需求悄然逼近!
过去几十年间,网络基础设施的设计趋势基本可预测,但人工智能驱动的数据中心和网络设计正将需求推向远超常规的高度。在此环境下,若忽视网络容量与资源的升级,您可能正为公司规划一个以人工智能为核心的美好未来,却在为时已晚时才发现网络基础设施根本无法支撑。
为确保网络发展不拖后腿,助力企业实现人工智能就绪,您应重点关注以下领域。
边缘网络配置
AI 工作负载极其耗费资源。它们不仅消耗着前所未有的计算、存储和内存资源,而且还极其耗费网络资源。AI 工作负载几乎完全在专门的 AI 数据中心(云端或专用的边缘网络基础设施)内处理;它们几乎从未在本地进行处理。
因此,网络是 AI 工作负载请求者与其执行者之间的桥梁,使其成为整个基础设施中至关重要的部分。它必须可靠,并且能够提供 AI 流程不断增长的带宽需求所需的容量。如下图所示。
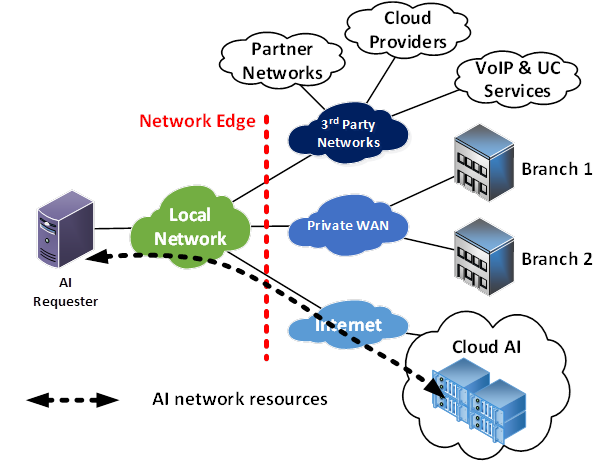

随着网络容量需求的增加,与“外部世界”(例如远程分支站点、其他私有网络以及互联网本身)的连接很快就会不堪重负。因此,网络边缘可能成为所有发往异地的网络流量(包括 AI 工作负载)的潜在瓶颈!因此,必须正确配置边缘网络。
容量
首先,为以 AI 为中心的应用配置边缘网络需要确保充足的带宽。与远程站点、专用网络、第三方网络和互联网的连接必须足以应对预期的峰值网络流量。路由器、交换机、VPN 网关、SBC 和防火墙等边缘网络设备必须具备处理预期流量所需的计算能力。AI 工作负载可能会导致网络流量意外增加,因此在网络流量预测中应适当考虑这些因素。
冗余
网络边缘容量只有在边缘连接正常运行时才可用。因此,边缘冗余是网络设计的重要组成部分——不仅对于人工智能而言,对于一般网络而言亦是如此。然而,随着关键任务应用和服务越来越依赖于人工智能,冗余变得越来越重要。
边缘网络设计
融合多种方法的边缘网络设计可以同时实现容量和冗余。这些方法包括选择合适的 WAN 技术、采用 SD-WAN 和 MPLS 等增强型连接方法,甚至在必要时使用无线桥接等选项。
边缘与云端 AI 处理
规模较大的组织应该考虑在自己的网络内部构建一些 AI 工作负载。混合 AI 架构可以实现本地 AI 集群与云端 AI 服务之间的集成。下图展示了这种架构。
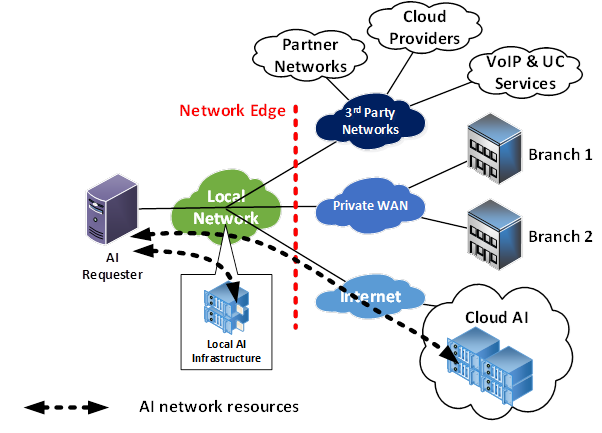
将 AI 数据中心资源部署在现场,对网络和组织的整体 AI 方法都具有诸多优势。这可以被视为一种“边缘计算”,其中计算能力在物理上更靠近工作负载请求者。这对所有类型的工作负载都大有裨益,尤其对 AI 工作负载更是如此,因为 AI 工作负载的密集程度要高出几个数量级。
当然,这会缩短响应时间,因为请求和响应的延迟大大减少,但这并不是唯一的好处:
- 数据主权与保密性:本地 AI 基础架构允许您在自己的私有数据集(包括客户信息、产品功能、财务记录和服务详情)上安全地运行 AI 工作负载,从而让您能够创建特定于组织的自定义工作负载。您无需与任何第三方 AI 提供商共享这些信息,因此采用隔离基础架构可以进一步增强安全性。
- 掌控:您可以根据工作负载选择并调整硬件、互连和软件。不存在共享租户限制、限流或意外弃用。您可以保留端到端策略权限(例如安全性、数据驻留、访问和维护窗口),因此合规性和变更管理可以按计划进行。
- 成本效益:事实证明,在规模化运营下,拥有自有硬件的本地 AI 基础设施可以胜过云端的总体拥有成本 (TCO),尤其是在稳定且高利用率的工作负载下。这还包括节省网络出口费用。
将内部部署 AI 基础设施选项与基于云的 AI 产品相结合,您可以创建混合 AI 环境,享受两全其美的优势,并进行调整以找到符合您组织需求的完美组合。
本地 AI 基础设施的电力和冷却要求
在部署本地 AI 基础设施时,至关重要的是确保您的内部网络和数据中心基础设施符合结构化布线以及铜缆和光纤布线的数据中心物理层设计等要求。但这还不是全部。您还必须维护可靠的支持基础设施,包括机架空间和布线,以及可靠的电源和冷却系统。安全性和合规性也是关键考虑因素。
电力
为数据中心提供可靠且不间断的电力本身就是一门科学。冗余电源、不间断电源 (UPS) 和随时可用的柴油发电机是必备的。随着人工智能工作负载变得越来越关键,除非出现前所未有的灾难性情况,否则断电或电气故障都不应导致停机。
冷却
冷却是人工智能的另一个重要领域。用于运行人工智能工作负载的数据中心通常由专门的人工智能计算单元提供服务,例如 Nvidia GB200 NVL72,它包含 72 个 GPU 和 36 个 CPU。这些独立的人工智能超级计算机拥有极高的 CPU/GPU 密度,需要内部液体冷却系统来有效地散热。
这种内部液体冷却系统可以去除处理器本身的热量,但如何处理这些热量则取决于可用的基础设施。理想情况下,液体冷却系统应该通向一个冷却液分配单元 (CDU),该单元负责带走热量,并将其直接从液体冷却液中排放到外部环境中。然而,要实现这一点,必须具备所需的冷却液分配设施。
在大多数使用传统冷却基础设施的企业数据中心,此类系统并不容易获得。AI计算单元可以采用其他方法进行改造,包括后门热交换器(RDHx)和液气侧柜,这些都是散热的替代方法。这两种解决方案都不如CDU高效,并且会限制相同物理空间内可实现的GPU/CPU密度。理想情况下,这些解决方案应作为获得成熟CDU基础设施之前的过渡阶段。
安全
本地 AI 基础设施必须被视为高价值的“飞地”。它应与网络的其他部分隔离,并应采用强大的身份识别和授权机制,包括多重身份验证 (MFA) 和短期凭证。训练数据、模型构件(训练模型时生成的文件和元数据)以及静态和传输中的敏感数据应使用适当的行业标准加密技术进行保护。
以下是一些有助于保护本地 AI 基础设施的其他网络基础设施最佳实践:
- 使用下一代防火墙 (NGFW)、API 网关和 Web 应用防火墙 (WAF) 终止所有入口会话,并强制执行强身份验证、授权和速率限制,确保只有经过验证的流量才能到达后端。强制所有出口流量通过具有 DNS 过滤和数据丢失防护 (DLP) 功能的代理,以控制出站数据流、阻止恶意目标,并防止未经授权的数据传输到其可信边界之外(数据泄露)。
- 在数据中心内,应用零信任原则,包括强身份、最小特权微分段以及节点和工作负载的持续验证/证明。
- 人工智能基础设施的带外 (OOB) 管理应仅限于其自己单独分段的网络中。
- 如果您将语音、UC或 RTC 集成到您的 AI 方案中,请在 DMZ 中放置一个会话边界控制器来终止 SIP/TLS/SRTP。在 AI 服务之前(以及周围)设置严格的分层控制,确保没有人能够直接访问它们,只有经过验证的、权限最低的流量才能通过。
遵守
合规性检查您是否对所使用的数据及其处理方式应用了适当的规则。遵守相关标准(例如针对受监管数据的 HIPAA/PCI 和针对控制基线的 ISO 27001/NIST 800-53)可确保遵守这些规则。此外,实施数据治理(分类、最小化、访问控制、保留/擦除和可审计日志记录)有助于证明合规性。
结论
人工智能彻底重塑了网络的发展轨迹。为了充分发挥其价值,无论是在云端、本地部署还是混合部署,企业必须对其网络进行现代化升级,使其在设计上更加安全、可观察、自动化且合规。理解其中涉及的概念将有助于企业适应变化、获得稳定性、扩展能力并满怀信心地满足监管要求。
作者:Daniel Noworatzky
原文:https://info.teledynamics.com/blog/how-to-prepare-your-network-for-the-demands-of-ai
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61771.html